- Published on
不定期更新的正则表达式经验库
- Authors

- Name
- McDaddy(戣蓦)
正则简直是伴随程序员整个生命周期的存在,不论做前端还是后端。这里记录下我日常累积的一些关于正则表达式的知识点,以此充当一个个人正则速查手册
主要的正则规则
| 正则 | 含义 |
|---|---|
| \d \s | 数字 空格 |
| \w | 字母数字下划线,等同于:[a-zA-Z0-9_] |
| [abc] | a b c 中任意一个 |
| [^abc] | 不是a b c 中任意一个 |
| \b \B | 字符串边界 非字符边界 /\baaa/ 不能匹配xaaa 能匹配’aaa |
| \t | tab |
| a4 | 表示a至少连续出现3次不多于4次 |
| ab|cd | 匹配ab或cd |
正则在JavaScript中的语法应用
string只有一个正则方法match如果有匹配到:
- 当正则不带g,返回一个数组,其中第一位是匹配到的值。重复执行也永远返回第一个匹配到的结果
- 当正则带g时它可以一次性返回所有的匹配值的数组,否则和
regex.exec(str)的返回一样
没有匹配到,返回null
regex = /(\d{4})-(\d{2})-(\d{2})/g regex2 = /(\d{4})-(\d{2})-(\d{2}) string = '2017-06-12 2018-01-12' string.match(regex) //["2017-06-12", "2018-01-12"] string.match(regex2) //["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12 2018-01-12", groups: undefined]所以如果使用
string.match正常情况都要带g,不然容易有歧义。Regex有两个方法test和exectest只返回一个booleanexec返回执行匹配的结果
regex = /(\d{4})-(\d{2})-(\d{2})/g
regex2 = /(\d{4})-(\d{2})-(\d{2})
var string = '2017-06-12 2018-01-12'
// test 返回的是 true/false
regex.test(string) // true
regex2.test(string) //true
//exec如果是执行带g的正则,每次执行会记录下最后一次匹配的index, 直到匹配失败返回null,所以exec可以配合while操作
regex.exec(string) // ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12 2018-01-12", groups: undefined]
regex.exec(string) // ["2018-01-12", "2018", "01", "12", index: 11, input: "2017-06-12 2018-01-12", groups: undefined]
regex.exec(string) // null
//如果正则不带g, 那个exec不管执行多少次都是返回第一个匹配
regex2.exec(string) // ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12 2018-01-12", groups: undefined]
//返回的数据结构是一个数组,0位是匹配到的完整字串,1~n位是正则中分组所匹配到的内容,index是当前匹配到的开始位置
0: "2018-01-12"
1: "2018"
2: "01"
3: "12"
groups: undefined
index: 11
input: "2017-06-12 2018-01-12"
- replace的正则用法
str.replace(regexp|substr, newSubStr|func)
//newSubStr支持特殊变量
// "🍰loHel🍕" 在有分组的情况下
'🍰Hello🍕'.replace(/(Hel)(lo)/, '$2$1')
// "🍰ello🍕ello🍕"
// H被替换为ello🍕
'🍰Hello🍕'.replace(/H/, "$'")
// "🍰🍰ello🍕"
// H被替换为🍰
'🍰Hello🍕'.replace(/H/, "$`")
//第二个参数可以是函数, 函数第一个参数是当前匹配到的字串,后面就相当于前面的$1,$2...
//将'2019-01-01'替换为01/01/2019
var str = '2019-01-01'
var reg = /(\d{4})-(\d{2})-(\d{2})/
// 01/01/2019
var result = str.replace(reg, '$2/$3/$1')
// 01/01/2019
result = str.replace(reg, function (match, year, month, day) {
return `${month}/${day}/${year}`
})
| 变量名 | 含义 |
|---|---|
| 2, $3…… | 第n个分组匹配的结果 |
| $` | 插入当前匹配的子串左边的内容 |
| $' | 插入当前匹配的子串右边的内容 |
| $& | 当前匹配的子串 |
贪婪与非贪婪
贪婪就是.* 他会尽量匹配最长的内容 如下会返回"witch" and her "broom" 而不是 witch和broom
var str = 'a "witch" and her "broom" is one';
str.match( /".*"/g); // 本意是要得到两个引号之间的内容
原因是正则遇到.*时会因为.是可以匹配任意字符的存在,所以就直接匹配到了行尾,这时候回头(回溯)来看.*之后要匹配什么,结果就会匹配到距离行尾最近的一个" 非贪婪就是.*?加上一个问号,告诉正则每匹配一个字符都要看一眼下一个要匹配的是啥,如果能匹配上就直接返回,而不是无限继续

或符号|的使用
在没有分组的情况下,|符号的范围就是左边全部或右边全部,只要任一匹配就可以。所以使用|要注意使用分组
let reg=/^ab|cd$/;
console.log(reg.test('bcd'));//true 以cd 结尾,所以为true
console.log(reg.test('bacd'));//true 以cd 结尾,所以为true
let reg=/^(ab|cd)$/;
console.log(reg.test('bcd'));//false
console.log(reg.test('bacd'));//false
分组的匹配不捕获
(?:)表示分组的匹配但是不捕获
例子: /^a(.*)(?:hello)(.*)b$/ 表示a开头b结尾,中间必须要有hello,虽然hello被括号包起来了,但它不是一个分组

断言
当需要判断一个字符串中是否有指定内容,除了使用通配,还可以断言。
断言就是直接判断是不是, (?=p)表示当前字符之后的字符要满足p, 它匹配的是位置,不是任何的字符串,它的功能类似^$
(?=pattern)语法也称为正向肯定预查,其中这里面的字符 pattern 表示的就是 要获取到这个字符,但是不匹配出来 (仅仅作为匹配的时候的条件限制,不会把匹配的结果输出)
(?<=pattern)语法也称为反向肯定预查,和正向的区别是(?=pattern)如果左边有内容,就要保证左边的都要匹配上,这个位置才成立,反向表示只要右边的内容匹配上,这个位置才成立
例子:

这样是不能匹配到555的,原因是(?=s)左边没内容,所以它就匹配到第一个s这个位置,注意是句首,不是s后的位置,此时要开始匹配\d*,因为接下来第一位是s,所以匹配不到

加上反向标志,表示我要匹配(?<=s)右边的内容是\d*, 所以可以匹配到
/^.*hello.*$/im.test(page) // 通配符来满足前后可能都有内容
/^(?=.*hello).*$/im.test(page) // 表示开头之后会出现一个满足.*hello的字符串

按理说断言中的内容是不会被匹配出来的,但是因为上面的例子后面是.*, 所以hello也会被带进去
正则表达式的与或非
与
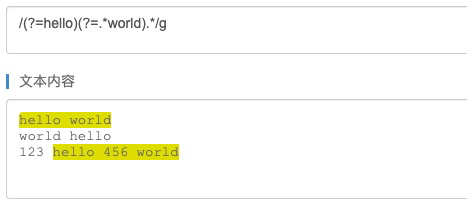
问题: 判断字符串是否同时包含hello和world,这里可以使用断言来实现判断多个条件。 这个写法只能hello在前world在后
/^(?=.*hello)(?=.*world).*$/im.test(page)
或
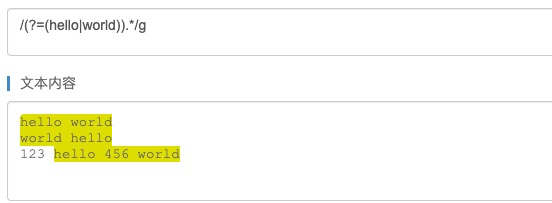
问题:判断字符串有hello或者world
/^.*(hello|world).*$/im.test(page) // 使用或操作符
/^(?=.*(hello|world)).*$/im.test(page) // 使用断言
非
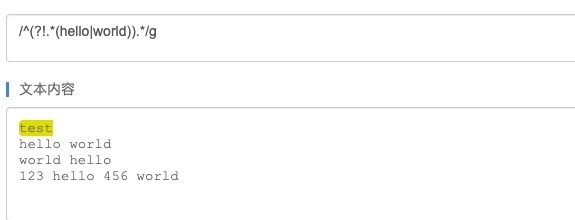
问题:判断字符串同时不包含hello和world, (?!p)和(?=p)刚好相反,表示当前之后不满足p这个条件
/^(?!.*(hello|world)).*/g.test(page)
常用正则
/([\w]*[\u4E00-\u9FA5]+[,,::。、\w?]*[\u4E00-\u9FA5][\w]*)+/ // 是否有中文
/^[a-zA-Z\u4e00-\u9fa5][a-zA-Z\u4e00-\u9fa50-9-_]{1,254}$/ // 长度为2-255,以大小字母或中文开头,可包含数字、下划线_和连字符-
/^[a-zA-Z\u4e00-\u9fa5](?!.*[@/=\s":<>{}[\]]).{1,127}$/ // 以大小写字母或中文开头,不支持字符@/:=\"<>}{[]和空格
/^-?[1-9]\d*$|^0$/ // 整数