- Published on
【笔记】- 计算机网络
- Authors

- Name
- McDaddy(戣蓦)
OSI 七层模型
OSI即Open System Interconnection,是一种理想的逻辑分层模型,目的是将复杂的流程简单话。实现专人干专事
分层的含义
层级的意义就是,下层要为上层服务
应用层:用户最终使用的接口,
表示层:数据的表示、安全、压缩
会话层:建立和管理会话的, 在四层模型中,以上三层为应用层
传输层:(主要提供安全及数据完整性保障)网络层不可靠,保证可靠的传输 (TCP/UDP)。解决的是如何让互联网通讯可信赖的问题,从而大幅降低互联网应用程序开发的负担
网络层:(主要关心的是寻址),主要保存IP地址,进行逻辑寻址,定位到对方,找到最短的路 。解决的是网如何通的问题
数据链路层: (主要关心两个设备之间传递数据),保存网卡的mac地址,建立逻辑链接,将数据组合成数据帧进行传递 (差错校测,可靠传输) 。主要负责局部网络世界的数据传输能力
物理层:核心是传输数据比特流,是真正传输数据的,而上面的层都是为了写入对应数据传输信息的(双绞线、光纤、同轴 电缆、无线...)
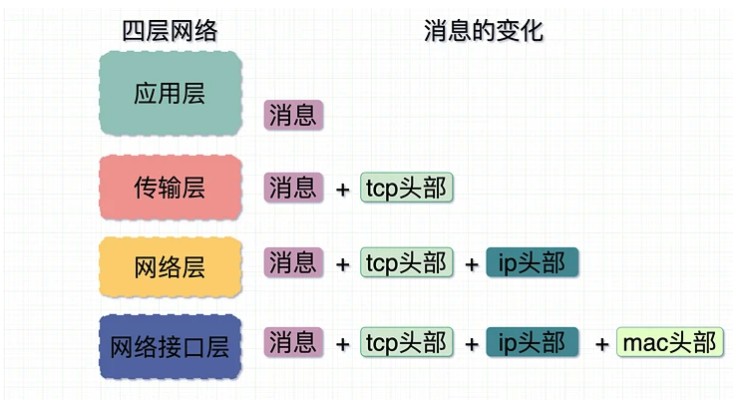
一次数据传递的流程(四层模型):
- 应用层添加消息,即真正的传输内容
- 传输层添加tcp头部,形成数据段。所有的通信一定是端口和端口之间的通信,即使在浏览器发起一个请求,能显式看到的只是目标的端口,但实际会分配一个随机端口给发送方
- 网络层添加IP头部,用于寻址,形成数据包
- 数据链路层添加mac地址信息,形成数据帧
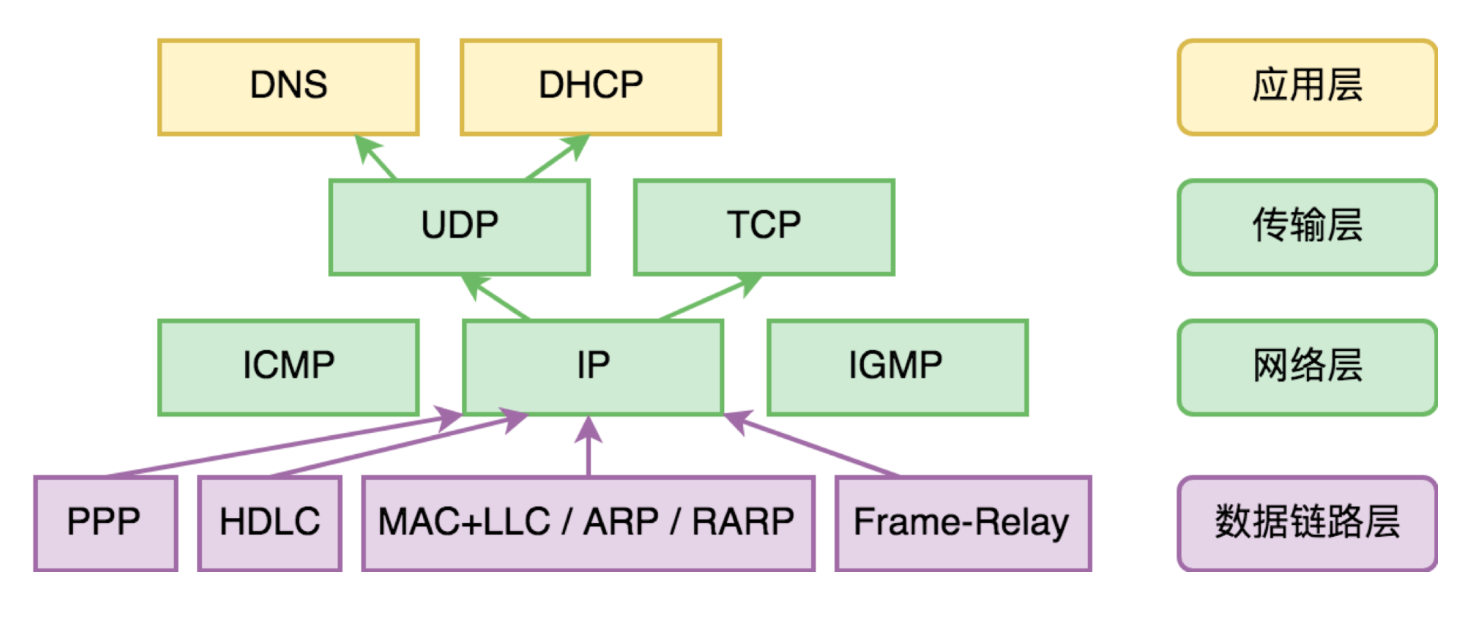
协议
协议都是在四层模型的3层及以上,数据链路层(交换机)和物理层(中继器,集线器)被称为物理设备
- 网络层(路由器网关):
IP协议:可以通过路由器寻址查找,将消息发送给对方的路由器,通过ARP协议,发送自己的mac地址ARP协议: Address Resolution Protocol,作用是从ip地址获取mac地址
- 传输层
- TCP
- UDP
- 应用层
- HTTP
- DNS
- FTP
- SMTP
- DHCP
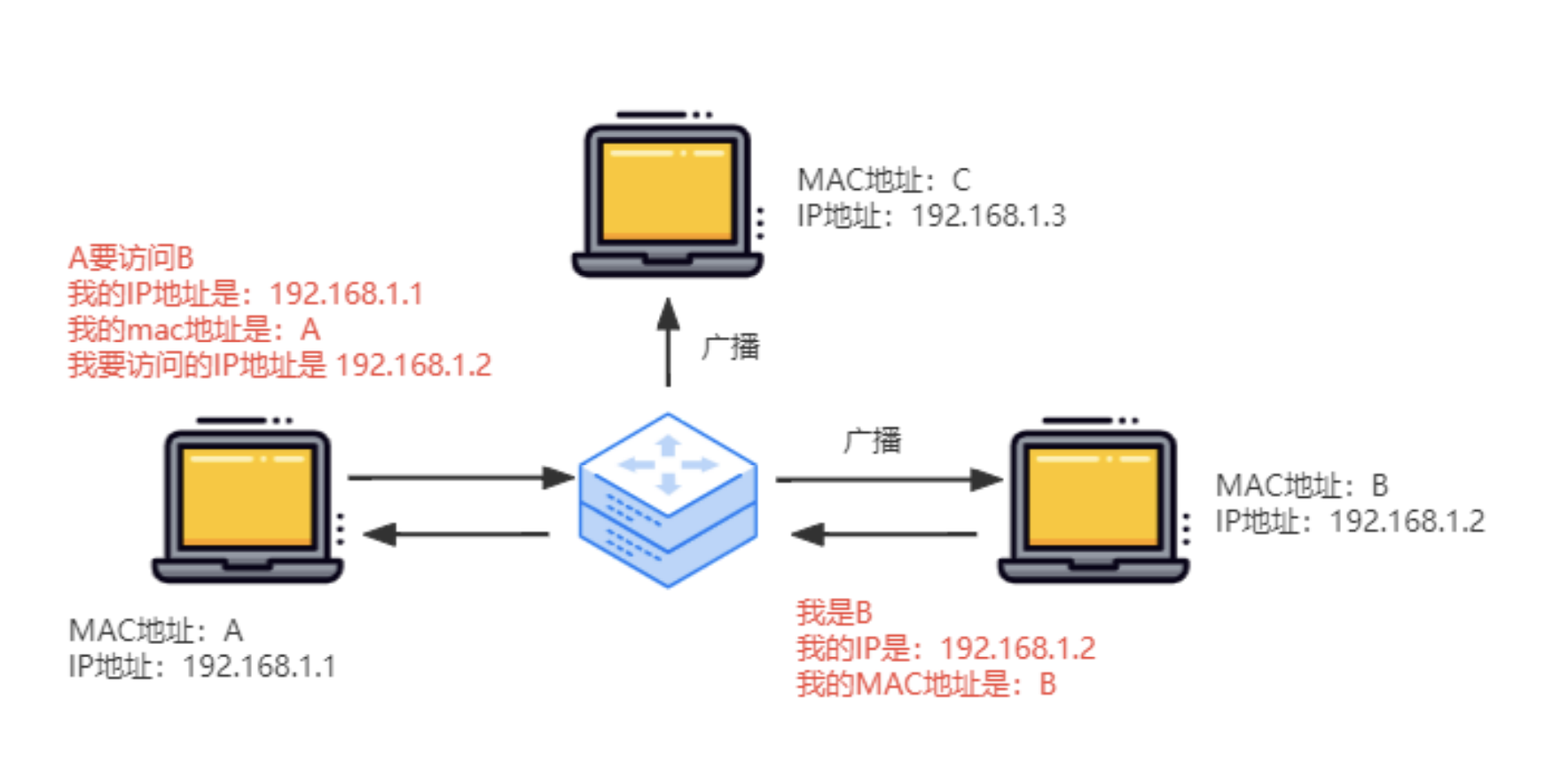
ARP协议
Address Resolution Protocol,它是服务于局域网的
根据目标的IP地址,得到目标的mac地址,也会把自己的mac地址发送给路由器缓存
在局域网内,或者说在一个网关内,假设A要与B通信,但A只知道B的IP地址,那么就能通过路由器广播给所有节点,B地址收到广播后就会返回自己的mac地址,并且缓存在路由器中,这样下次A要和B通信时,就可以直接通过路由器中缓存的mac地址直接找到B。
ARP攻击
就是发起攻击的欺骗源主机,把自己伪装成网关,向局域网内的目标主机发送ARP应答报文,使得目标主机误以为欺骗源的MAC地址就是网关的MAC地址,这样就使本来应该流向真实网关的数据流向了欺骗源机器,使得目标机器无法通信
防御措施:
- 动态ARP检测:一般需要企业级交换机支持,个人组织比较难实现
- 静态ARP绑定:就是把自身机器和真实网关的IP-MAC地址做双向绑定,不允许动态修改
- ARP防火墙: 一般杀毒软件等都有此功能
DHCP协议
通过DHCP自动获取网络配置信息 (动态主机配置协议Dynamic Host Configuration Protocol)我们无需自己手动配置IP
DNS协议
Domain Name System的缩写,DNS服务器,就是进行域名与IP转换的服务器
- 顶级域名 .com
- 二级域名 .com.cn
- 三级域名 www.zf.com.cn , 即有多少个点就是几级域名
DNS的查找过程(www.zf.com.cn):
- 操作系统DNS缓存,缓存命中直接返回IP。这就是为什么本地配了host可能并不能立即生效的原因
- 查找本地host文件
- 通过DNS服务器,找到根服务器,得到.cn的服务器IP地址
- 向.cn的IP发送请求,得到cn下com的ip
- 如此循环,得到最终的www的ip,并缓存在DNS服务器上
ICMP协议
Internet Control Message Protocol,是网络层的协议,全称叫互联网控制报文协议。它能够检测网路的连线状况,以保证连线的有效性。基于这个协议实现的常见程序有两个:ping 和 traceroute,它们可以用来判断和定位网络问题。
数据传输过程
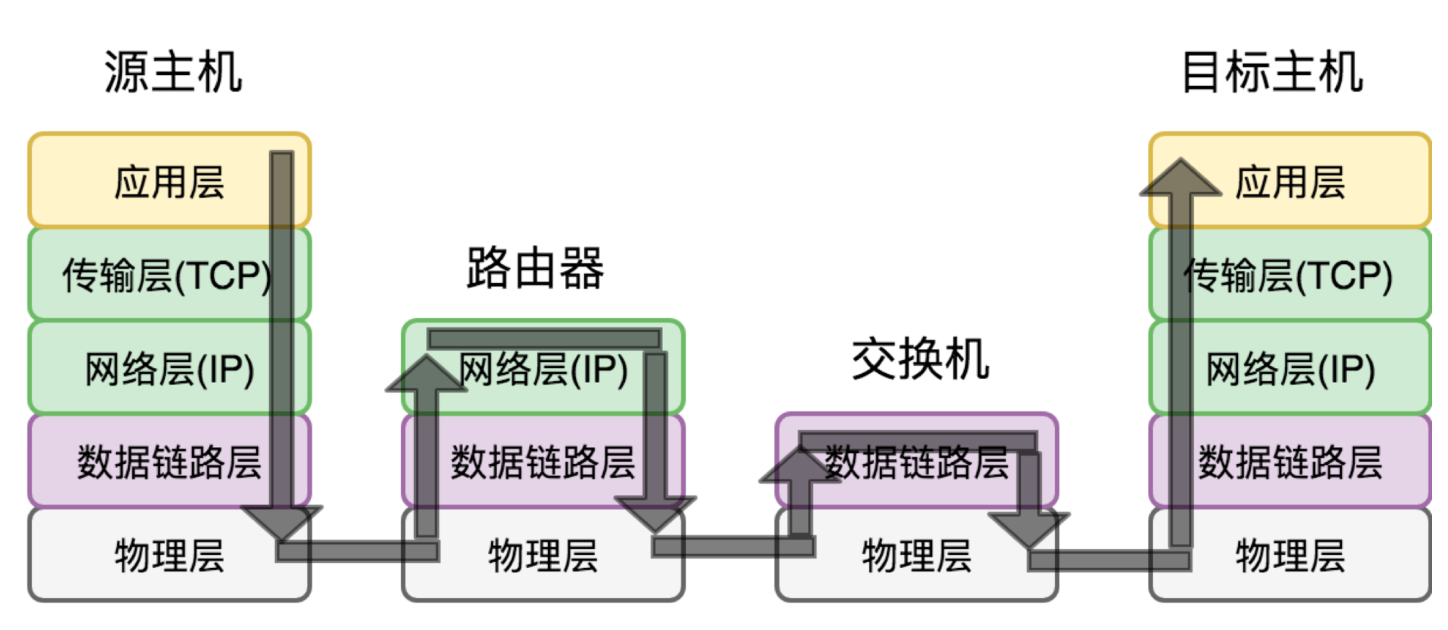
**情形一,源主机和目标主机在同一个局域网内,中间通过交换机连接,采用了最常见的以太网协议。**会经历以下步骤
主机X向主机Y发送数据包
- 交换机从某端口A收到MAC地址为A发来的数据包,在交换机上记录交换机端口A和X的MAC地址的关系
- 但是它不知道机器Y在哪里,于是向除了A之外的所有端口广播,称为flooding
- Y收到广播的信息,向X放出确认包,此时交换机从B端口收到后,记录下Y的MAC地址和B端口的关系
- 交换机把确认包转发给X,称为forwarding
通过以上可以总结出,交换机是性能极高的网络数据交换设备。它通常工作在网络协议的第二层,也就是数据链路层。这一层只认 MAC 地址,不认 IP 地址。MAC 地址本身是个唯一身份标识,就像我们的身份证号,并没有可寻址的作用。
它的工作原理就是不断地收集资料去创建一个地址映射表:MAC 地址 => 交换机端口。这个表很简单,它记录了某个 MAC 地址是在哪个端口上被发现的。
情形二,源主机和目标主机都有公网 IP 地址,它们中间经过若干交换机和路由器相连。
如果都是在公网,那么靠交换机那样广播效率就太低了。路由器区别于交换机在于它工作在网络层,依靠源和目标的IP地址,可以知道两者的关系
- 如果是局域网内的两个主机,就充当交换机的作用
- 如果是公网机主机,就把数据包包装起来,路由器有导航的功能,根据路径(路由表)把包发送出去,最终到达目标的网关
NAT
第三种情况,有一台主机它的地址是局域网地址,而另一方是公网地址。
就比如手机连入WiFi的地址肯定是局域网地址,理论上只能在局域网内通信,是不能连接公网的,但实际情况我们都可以上网,原理就是采用NAT技术
(Network Address Translation,网络地址转换)技术。它的原理比较简单,假设我们现在源主机用的 IP+ 端口为 iAddr:port1,经过 NAT 网关后,NAT 将源主机的 IP 换成自己的公网 IP,比如 eAddr,端口随机分配一个,比如 port2。
也就是从目标主机看来,这个数据包看起来是来自于 eAddr:port2。然后,目标主机把数据包回复到 eAddr:port2,NAT 网关再把它转发给 iAddr:port1。
也就是说,NAT 网关临时建立了一个双向的映射表 iAddr:port1 <=> eAddr:port2,一旦完成映射关系的建立,在映射关系删除前,eAddr:port2 就变成了 iAddr:port1 的 “替身”。这样,内网主机也就能够上网了。
我们家用的 WiFi 路由器,就充当了 NAT 网关的作用,这也是我们能够上网的原因。这个也有点像代理的意思
TCP

TCP是基于连接的协议,它对数据进行分段打包传输,对每个数据包都编号控制顺序
建立连接
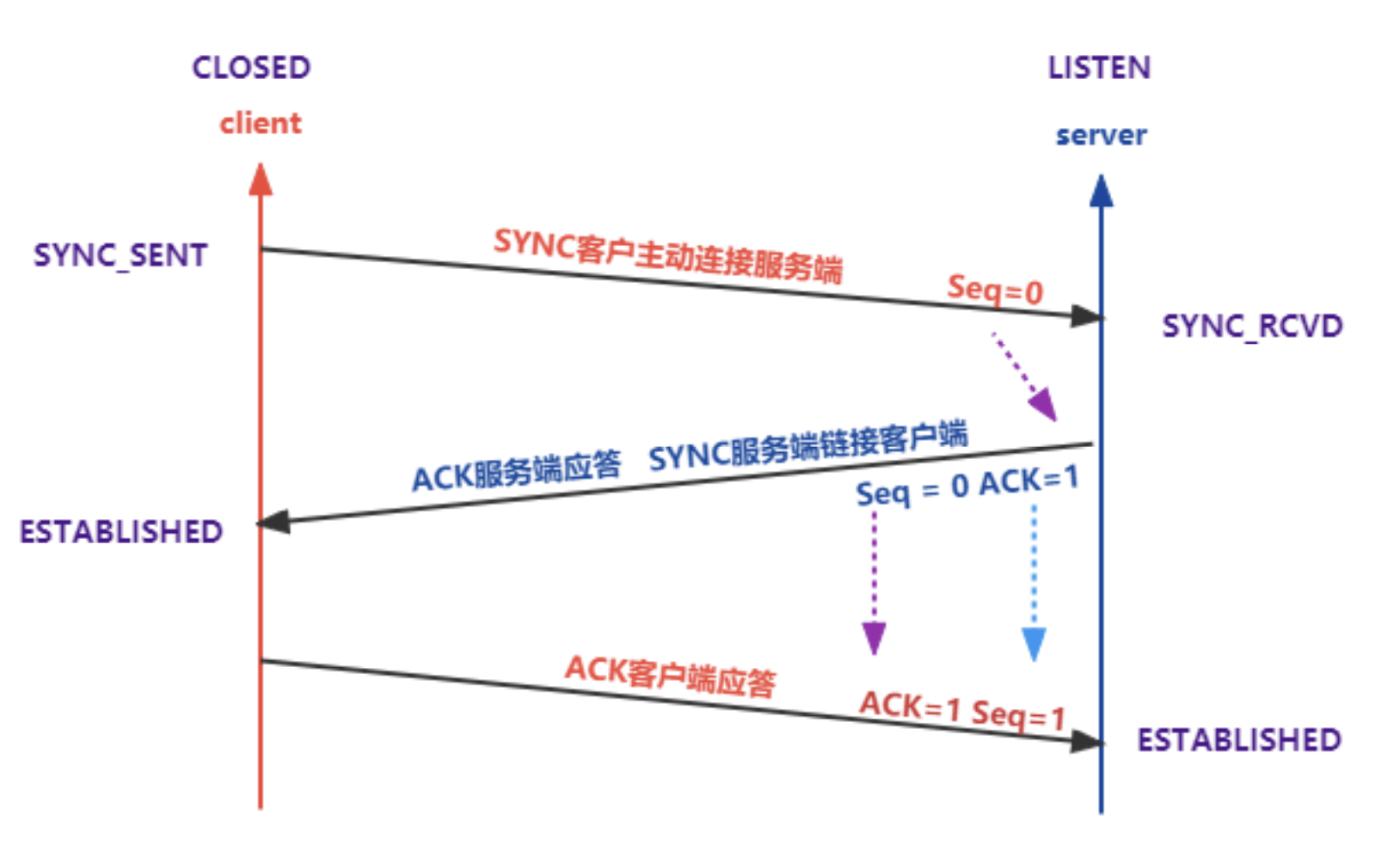
SYN表示要建立连接的信号Seq表示当前自己的序列号ACK表示确认信号,它是从对方的Seq + 1得到的,并发送回去- 最终双方的
Seq都从0到了1,即完成了连接的建立

数据传输
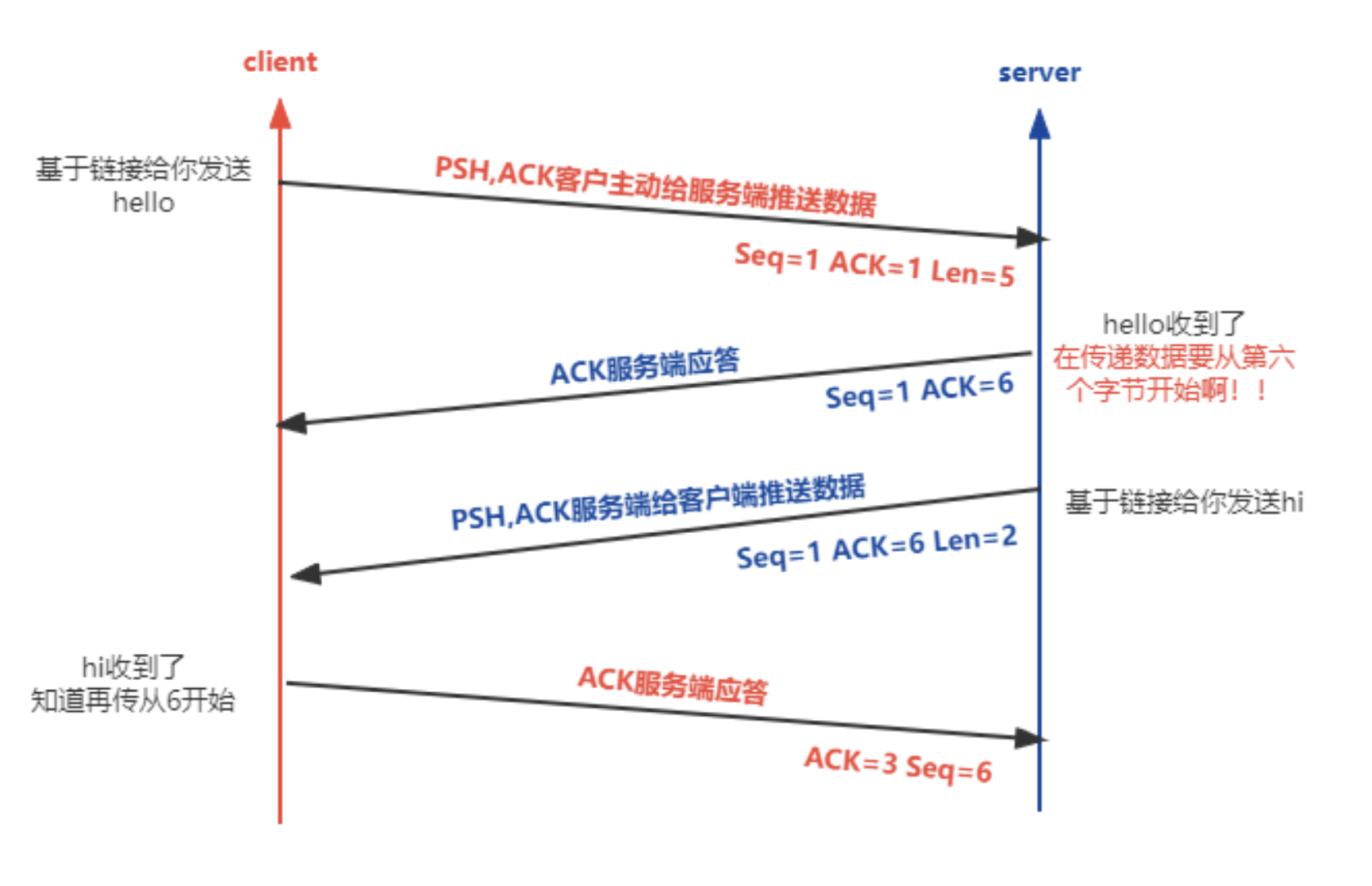
PSH表示推送数据Len表示这次推送数据的长度- 不论客户端还是服务器每次接收到非ACK的信号后,都会主动发送一个ACK包表示确认
- 这里的服务器的第一次应答,表示数据收到了,ACK为对方的
Seq + Len即下一个对方的序列号,同时每次都会带上自己的Seq

如上图,如果一次传输的数据过大,那么TCP就会分包,这里以发送30002个汉字为例
- 在局域网每个TCP包能携带的最大字节数是16332。由于在utf8下一个汉字占3个字节,所以总的内容长度是
30002 * 3 = 90006 - 这里分成了5个包,总长度为
16332 * 4 + 8346 = 90006 - 每次的
Seq都会从上次的结束位开始 - 单个包的总大小是16388,其中56是报文头
- 总大小为什么是16388,这是根据网络环境变化的,在大多数情况下,以太网的最大传输单元是1500,所以如果在英特网上发30002个汉字,将拆分成更多的包
断开连接
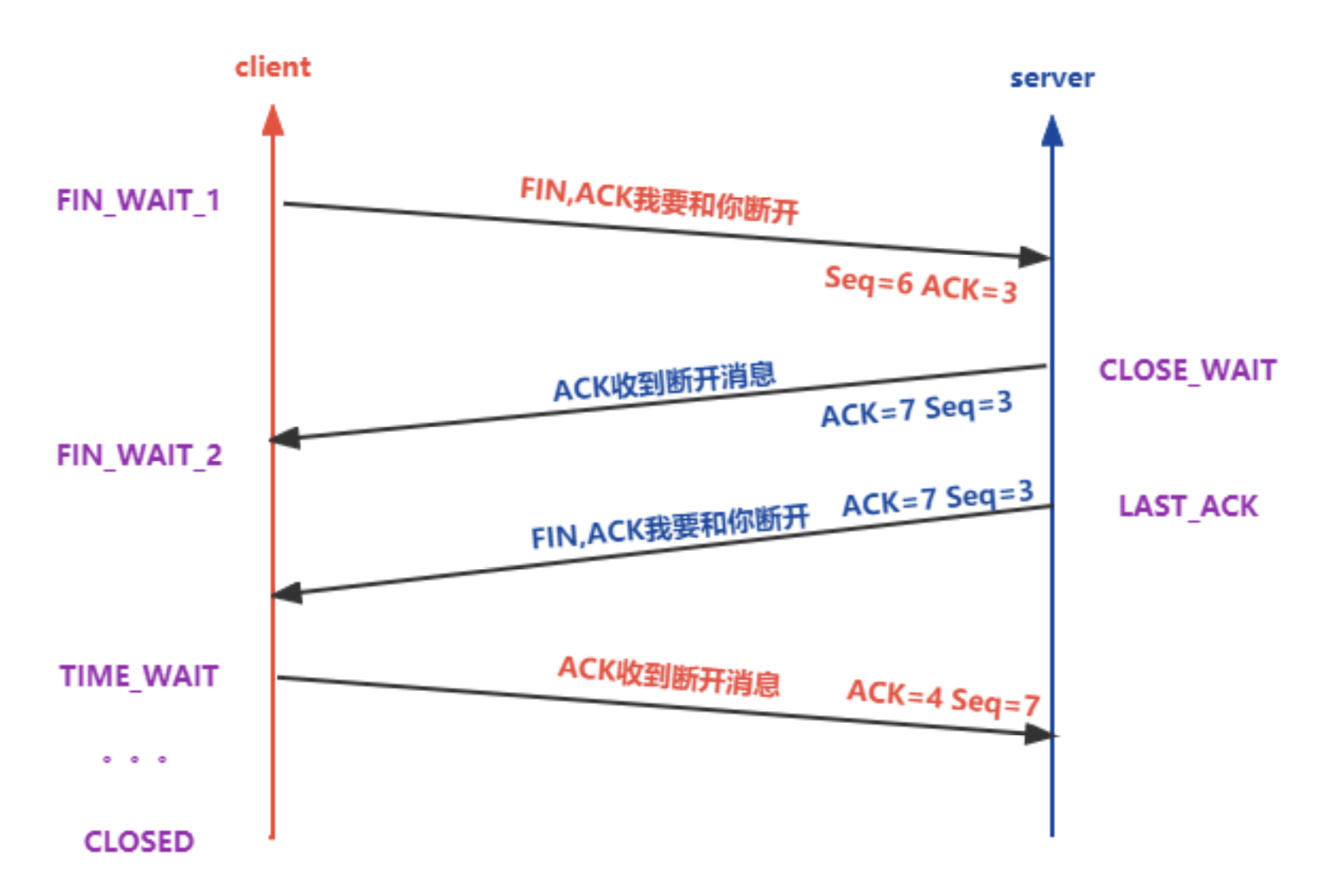
为什么需要4次挥手

上图就是一个典型的场景,客户端一次性发送了大量数据给服务端,然后立即主动断开,此时服务端还没处理完成数据,消息都没来得及返回。
- 客户端发出
FIN包,FIN就是断开连接的信号 - 服务端返回
ACK包,表示收到FIN - 接下来服务端连续发了两次数据
PSH,客户端也响应了两个ACK - 服务端发出
FIN,表示数据已经发完,可以断开连接 - 客户端返回
ACK,正式断开连接
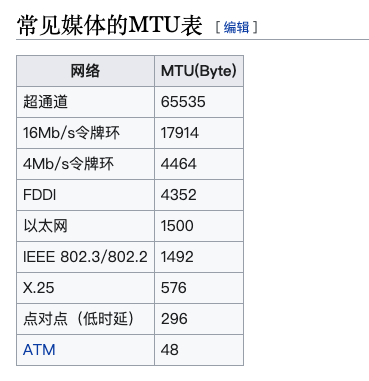
MTU与MSS
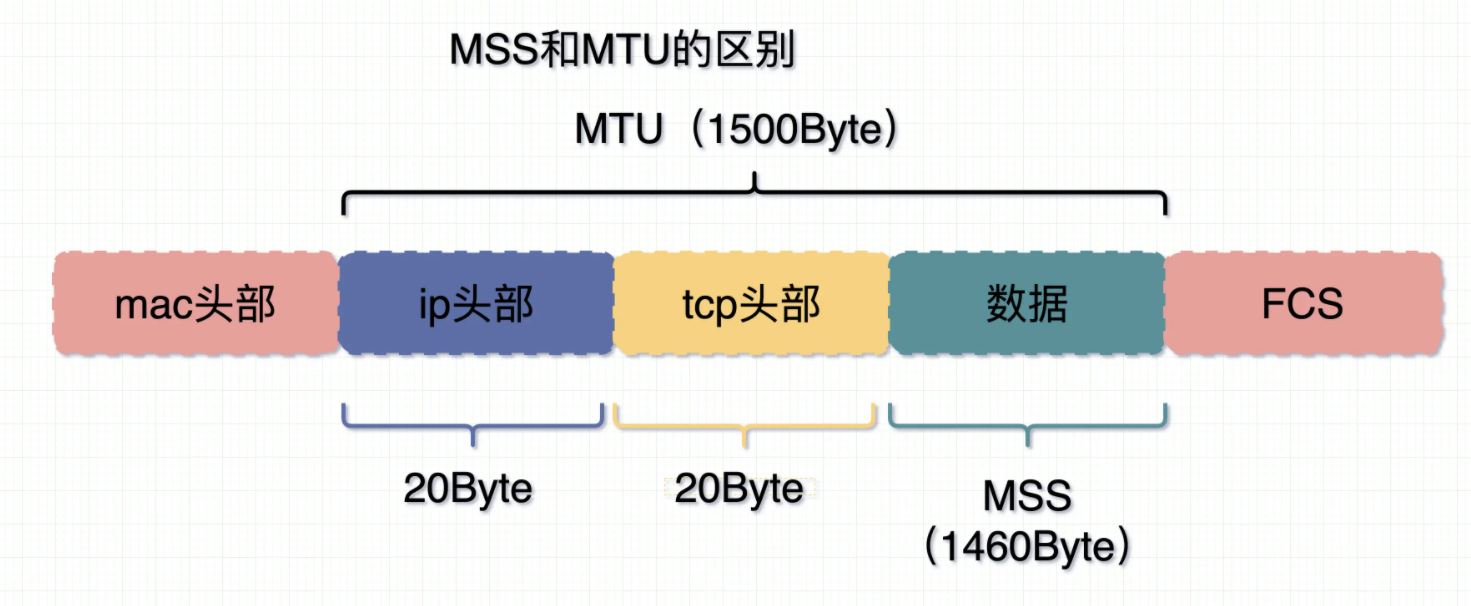
MTU: Maximum Transmit Unit,最大传输单元。即数据链路层能提供给网络层最大一次性传输数据的大小,在以太网下是1500,如果单次要发送的总长度超过这个值,就需要分包发送
MSS:Maximum Segment Size 。 TCP 提交给 IP 层最大分段大小,不包含 TCP Header 和 TCP Option,只包含 TCP Payload ,MSS 是 TCP 用来限制应用层最大的发送字节数。假设 MTU= 1500 byte,那么 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte
UDP
udp 用户数据报协议 User Datagram Protoco ,是一个无连接、不保证可靠性的传输层 协议。你让我发什么就发什么
使用场景: DHCP协议、 DNS 协议、 QUIC 协议等 (处理速度快,可以丢包的情况)

从抓包来看就比较简单,一次数据传递就是一条记录,不需要连接,速度很快
滑动窗口
- 滑动窗口:TCP是全双工的,所以发送端有发送缓存区,接收端有接收缓存区。要发送的数据都放到发送者的缓存区,发送窗口(要被发送的数据)就是要发送缓存中的那一部分
- 双方每次都会向对方确认自己的窗口大小,当为0的时候就停止发送。主要作用就是根据网络环境,进行流量控制,如果网络通畅的话窗口就大,反之就缩小
粘包
就是数据接收方将一个数据包和另一个数据包粘在了一起接收,然后错误得组装了消息,导致数据被错误得分割。
- 出现粘包的核心原因是,TCP是基于字节流的,也就是发送数据都是0101这样的二进制数据,而这些数据是没有边界的。即数据不是以整个消息为单位发出去的,而是以字节流发出去,就可能发生数据的切割和组装,而接收方没能正确还原,从而导致了粘包。
- Nagle算法的作用是充分利用带宽,只有当消息体量达到MSS时或者等待超时时才发送,这就容易导致粘包,比如msg1不足MSS,msg2的一部分到来了,与msg1相加超过了MSS,然后立即发送。此时接收方收到这样一个组合后的信息,就会错误得认为这是一个整体
- 但即使关闭了Nagle算法,也不能解决粘包问题,因为接收方是有接受缓冲区的,隔多久来取一次数据由接收方决定,和上面同样的原理,粘包还是可能发生
- 如何处理粘包,就是要给数据加上特殊标志以及校验字段,这样就没有风险了
- UDP是基于报文的,接收方必须一次接收完,边界是清晰的,所以不会有粘包问题
TCP 发送端发 10 次字节流数据,而这时候接收端可以分 100 次去取数据,每次取数据的长度可以根据处理能力作调整;但 UDP 发送端发了 10 次数据报,那接收端就要在 10 次收完,且发了多少,就取多少,确保每次都是一个完整的数据报。
- IP 层也切片,但是因为不关心消息里有啥,因此有不会有粘包问题。
HTTP
发展历程
- http/0.9 只能发送纯文本,仅有GET请求,响应后立即关闭连接
- http/1.0 引入
header概念,增加HEAD,POST方法 - http/1.1 加入
keep-alive,允许响应分块,加入缓存管理,加入PUT,DELETE等方法,加入管线化,加入请求体压缩(gzip) - http/2.0 加入
HPACK算法,压缩头部,减少数据传输量,允许服务器主动向客户端推送数据,强制通信加密HTTPS(https不是2.0的产物,而是2.0强制使用),加入多路复用 - http/3.0 基于UDP的QUIC协议
管线化(Pipelining)
在http/2.0以前,一个TCP连接只能同时处理一个请求,即请求的生命周期是不能重叠的。这样就相当于所有请求是串行的,进而发生队头阻塞。管线化允许并发请求,利用浏览器可以在同个域名建立6个TCP连接的特点, 并发多个请求,请求的发送不需要相互等待。但这样也并没有解决队头阻塞的问题
- 只支持简单请求的管线化,如GET,像POST就不支持
- 虽然请求是并发发送的,但是要求返回的顺序是串行的,即如果第一个请求被服务器处理了很久,那么后面的请求即使处理完了也会被阻塞 ,浪费服务器资源
- 一般情况也仅能实现6个并发,其实也不多,要增加那只能做域名分片
- 一般现代浏览器是把这个功能关闭的
HTTPS
摘要算法
- 可以将任意长度数据变成固定长度的摘要
- 相同的输入得到相同的输出,但是细微差别的输入会得到巨大差距的输出
- 无法从输出反推出输入
- 最常见的是
MD5
对称加密
加密和解密用的是同一把钥匙,网络中传输的都是经过加密的信息,但前提是双方都要有这个密钥, 这就需要在开头传递这个密钥,在这个过程中就有可能发生劫持和篡改(黑客可以直接拦截到这个密钥,然后对后面的数据直接解密),目前最常用的对称加密算法是AES, ChaCha20
非对称加密
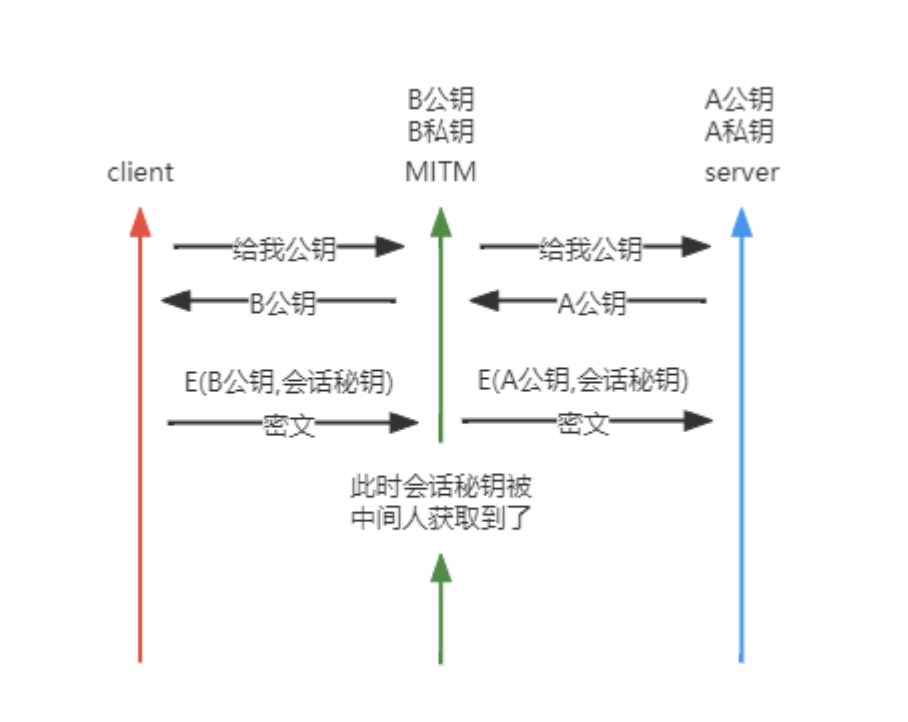
为了解决上面密钥传输使黑客能直接解密数据的问题,引入了公钥和私钥,公钥用来加密,私钥用来解密,或者相反。私钥只存放在本地,不会曝光在网络上
- 目前流行的非对称加密算法是RSA、ECDHE
- 非对称加密的性能消耗是很大的,所以一般用于建立连接,后续通过客户端生成会话密钥,通过公钥加密返回给服务端,服务端解密,然后双方后续都用对称加密(会话密钥),总的就是混合加密
- 这里的问题是,虽然可以阻止数据被解密,但是如果黑客在中间篡改了公钥,而客户端并不能发现,那么黑客就相当于用自己的密钥在中间做了一层代理,所有数据还是不安全的
数字证书
因为谁都可以发布公钥,所以我们需要验证对方身份。防止中间人攻击。
- 包含的信息
- 证书所有者的公钥
- 证书所有者的专有名称
- 证书颁发机构的专有名称
- 证书的有效起始日期
- 证书的过期日期
- 证书数据格式的版本号
- 等等
- 任何人都能给自己颁发数字证书,所以为了证书的真实性,必须要由授信的权威三方来颁发,就是CA
数字签名
类似我们人手工签名,就是为了验证发证书来的人不是就是证书的所有者, 包括生成和验签两个步骤
- 生成签名: 通过SHA-256等算法,对证书整体进行摘要(上面提到的),再用私钥给这个摘要加密,得到签名
- 验签过程:
- 将证书和签名一起发给客户端
- 客户端用CA公钥解密证书,得到公钥,然后解密发来的数字签名,得到服务器算出来的证书摘要
- 客户端用相同的摘要算法,再算一遍证书,得到摘要,跟上一步的摘要对比,如果相同就通过,否则就是验证失败
整个过程可以总结为,从服务端发来的证书A虽然是由CA颁发的,但也有可能是从中间人B的服务器发过来的,虽然证书是真的,但是发送方是假的,所以需要这个步骤来验证服务方的真实性
握手过程
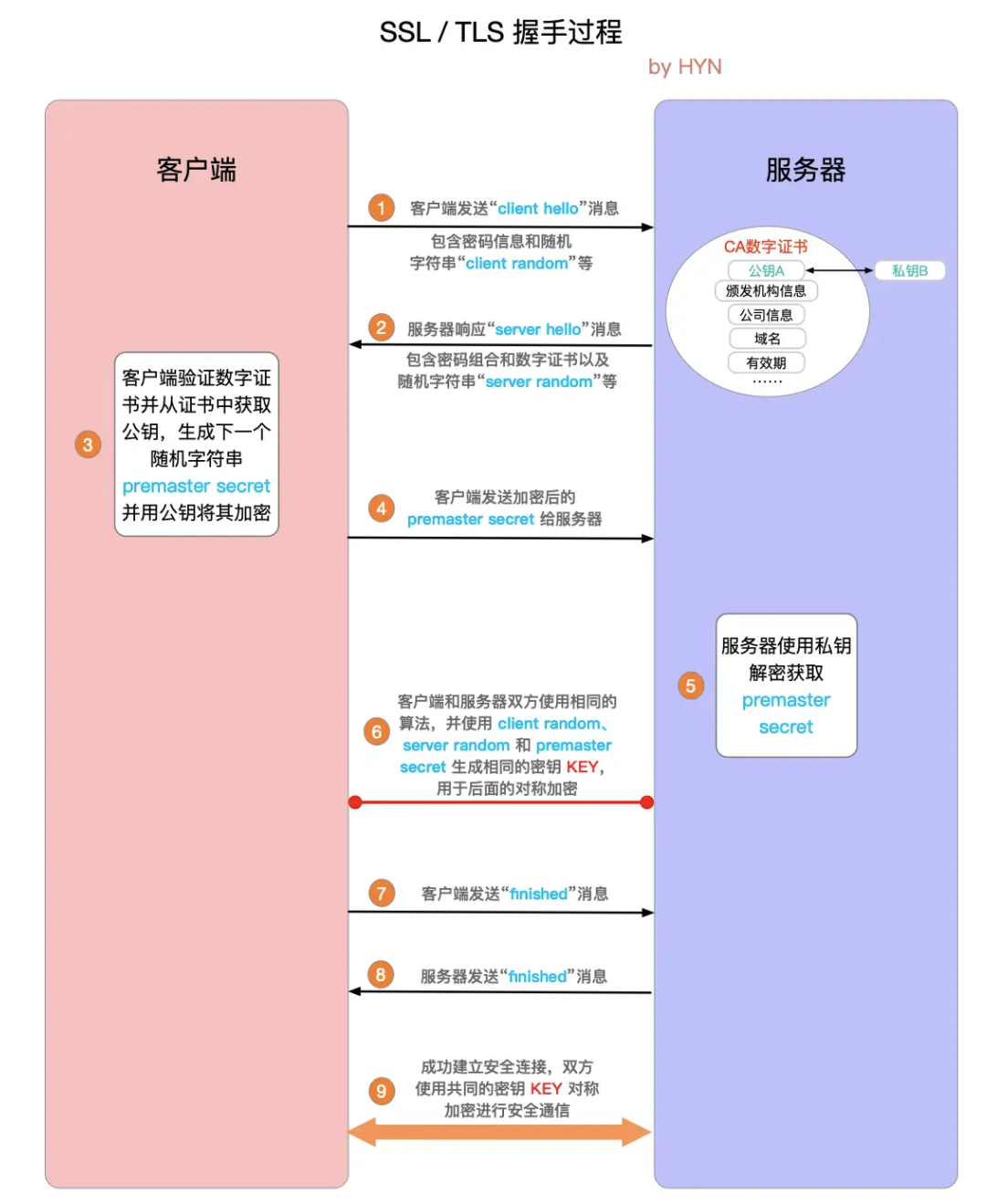
- 客户端发送
client hello,一个随机字符串client random和可用的加密算法 - 服务端返回
server hello,加密算法,数字证书,数字签名和一个随机字符串server random - 客户端验签,成功后得到服务端的公钥,生成又一个随机字符串,并用公钥加密返回给服务端,这个信息称为
premaster secret - 服务端用私钥解密得到
premaster secret - 此时双方都有
client random/server random/premaster secret,前两步协商好的加密算法,通过这三个参数,生成共同的密钥KEY,称为会话密钥,用于后续的对称加密 - 各自发送finished表示握手结束,之后就开始对称加密通信
HTTPS详解二:SSL / TLS 工作原理和详细握手过程
HTTP/2.0
HTTP/2.0 主要是解决了1.1没有解决的性能问题
- 1.1只对请求体做了压缩,没有对头部进行压缩
- 管线化的并发请求并不能解决队头阻塞,如果有阻塞,最终还是FIFO
多路复用
在一条TCP链接上可以乱序收发请求和响应,多个请求和响应之间不再有顺序关系
- 单个连接可以承载任意数量的双向数据流,单个连接上可以并行交错的请求和响应,之间互不干扰
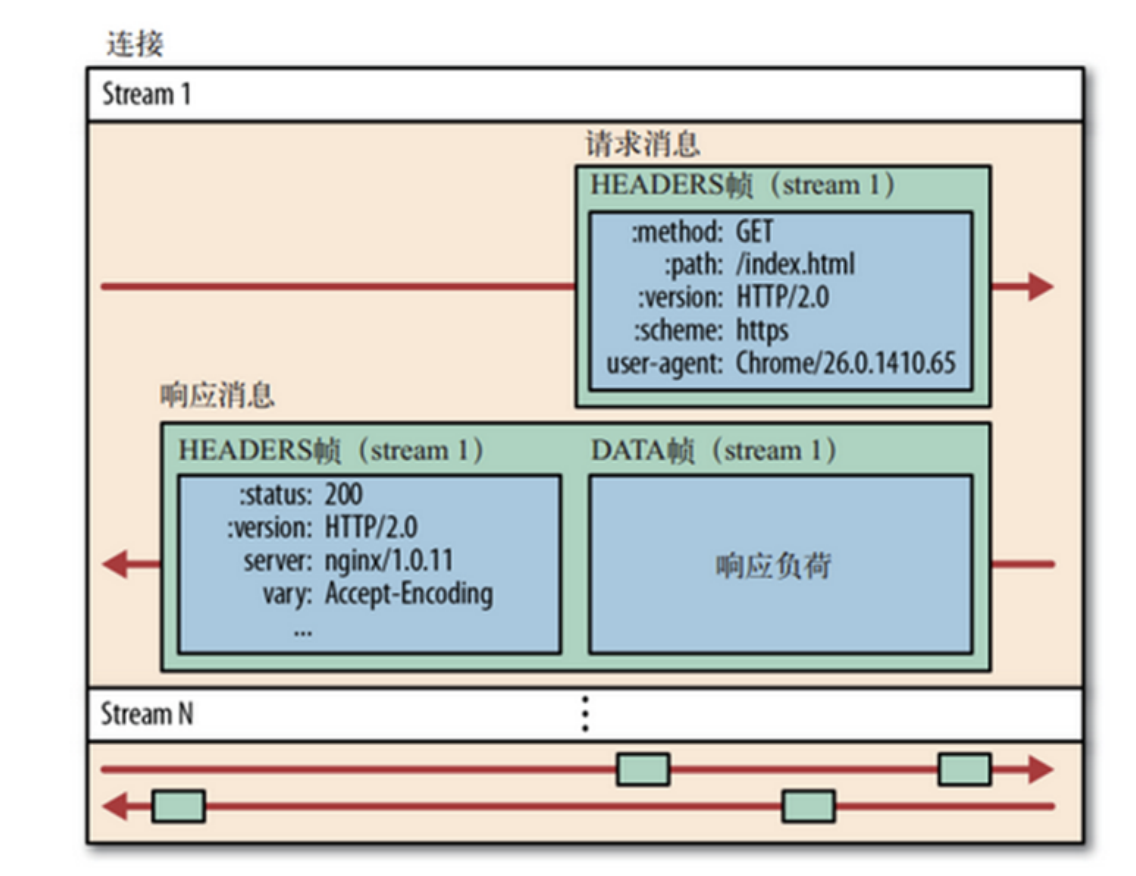
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。每个请求都可以带一个 31bit 的优先值,0 表示最高优先值,数值越大优先级越低
帧与流
帧的类型,我们主要用到的就是HEADERS和DATA
HEADERS frame
DATA frame
PRIORITY (设置流的优先级)
RST_STREAM (终止流)
SETTINGs (设置此连接的参数)
PUSH_PROMISE (服务器推送)
PING (测量RTT)
GOAWAY (终止连接)
WINDOW_UPDATE (流量控制)
CONTINUATION (继续传输头部数据)
流是指传输中的虚拟通道,虽然所有的请求都在共用一个TCP连接,N个请求可以理解为N个流的传输,虽然请求与请求间的数据发送是无序的,但是对单个请求来说,在一个流上,是有顺序的,请求可以分为N个二进制帧进行传输,每一个帧都有一个流ID,这样即使是大并发,也可以对请求进行分组。所以流可以理解为,有序的帧的集合
IP
为什么断网了还能ping通127.0.0.1?
因为127开头的ip表示回环地址,一旦访问回环地址,是不会经过真网卡的,而是把消息直接放到input_pkt_queue这个链表中,这个链表其实是所有网卡共享的,上面挂着发给本机的各种消息,指这条消息就好像是从外面被发进来一样被处理
同时机器也会记录本机的IP地址,即使是ping本机IP,最后也会被识别成回环地址,走的是lo0这个假网卡

ping 0.0.0.0会失败,都是如果用0.0.0.0:port去访问却没有问题,因为0.0.0.0它不指代某个IP,而是指代本机上的所有IPv4地址,比如访问0.0.0.0:8080 就等于是127.0.0.1:8080
为什么在家时的IP都是192.168开头的?
从原始设计来看IPv4总的IP数量只有42亿,这个世界一人分一个都不够,但是现实世界每个人都有多个电子设备,每个设备都会有一个独立的IP,这是怎么做到的呢?

这就是网段起的作用,一般10开头的网段属于公司级别的网段,可以支持1600w+个私有IP,而192.168开头的C类网段可以支持6w+的私有IP地址,基本满足小区或街道的数量需求。
这里的ABC类地址只会出现在局域网中,不会出现在广域网中
整个小区可以共用一个公网IP作为出口,小区内部其实就是一个局域网,总的就是一个做乘法的原理,一个广域网网地址就能衍生出N多个局域网地址。
子网掩码
子网掩码可以看做跟IP一样的32位的01组合,结构和IP完全一致,区别是子网掩码从高位开始只能一路是1,出现第一个0之后,后面都是0,11111111.11111111.10000000.0000000大致就是这样的结构
它的位可以和IP的位一一对应,从第一个0开始的对应IP的位置,就是子网的开始
子网掩码的作用
划分了IP的网络部分和主机部分,IP是32位二进制组成的,我们是看不出哪些部分代表网络部分的。比如10.234.xx.xx,我们认为所有10.234开头的IP都是属于一个网络所有,后面的xx.xx则是主机部分,也可以称为子网。区分两部分的好处有
- 通过划分网段,可以在子网中独立配置路由,安全策略等
- 控制广播范围,比如想广播一条信息给一个网络内的所有地址,如果没有子网掩码,那就要枚举出所有需要的IP地址,而掩码就能做到直接精确广播所有
避免IP地址的浪费,比如193.168.0.0这个网段,它下面只有4台主机,即193.168.0.0 ~ 193.168.0.3,如果把这个193.168.0.x这个网段都给它了,那么就等于浪费了
255 - 4个IP地址,如果给它一个子网掩码193.168.0.0/30即这个网段的前30位都是固定的,只有尾巴上的两位是可变的,就精确得控制了这个网段最多仅有4个IP地址