- Published on
机器学习
- Authors

- Name
- McDaddy(戣蓦)
基本概念
机器学习的本质就是让机器拥有找一个函数的能力
我们可以把所有的操作都抽象成一个函数
- 比如我要下围棋,那么输入就是当前棋盘的布局,输出就是下一步应该下在哪里
- 要去分辨一张图片是猫还是狗,那么输入就是图片,输出就是猫/狗/neither not
这里的关键就是能不能找到这个合适的函数
函数的类别
Regression回归:它的输出是一个scalar(标量)
比如,预测明天的PM2.5数值
Classification分类:从多个选项中,选出一个或多个正确值
比如,从一个邮件列表中找出垃圾邮件
下围棋也是这个类别的,只是选项是19 * 19个格子,ML的目标就是找到合适的函数得到正确的下一步位置
Structured Learning(创造): 这个是占据绝对多数的场景,因为一般我们不会只需要生成一个单一的值
输出有结构的结果,比如生成图片、视频、音频和文档
如何找到函数
这里以一个根据历史播放数预测明天的播放数这个场景作为例子
假设一个函数 y = b + wx1
其中y就是要预测的明天的播放量,x1是昨天的播放量,w和b是未知的变量
为什么要假设成这样一个函数,其实只是基于历史数据是可以影响未来数据这个基础假设上,简单推测出来一个线性函数,这的函数表达式可以理解为一个所谓的专家经验
其中w = weight权重, b = bias偏置,至于这两个值应该设置成什么就是需要通过机器学习来得到最正确的结果
从训练资料里定义损失函数 L(w, b) 损失:就是衡量参数效果是好是坏
我们先随机假设一个参数值组合,b = 0.5k w = 1,代入函数得到 y = 0.5k + x1
我们的训练资料是从17年到20年的所有播放量数据,我们把这个函数代入真实的数据中,比如17年1月2日,结果就是
0.5k + 4.8k = 5.3k这个和真实的1月2号的数据绝对值差距是5.3 - 4.9 = 0.4k, 那么这0.4就是这个参数组合下在这个实际训练数据上的一个损失
现在我们把这个函数套用到所有训练数据里面去,假设总共N天数据,下面的公式就可以得到所有数据点上损失的平均值
理论上讲我们肯定是希望L得到的结果越小越好,假设如果我们能穷举所有的w和b的可能值,就应该能绘制出下面这样一幅等高线图,其中颜色越深代码L值越大,越浅则值越小。所以接下来的任务就是找到那个使L结果最小的那个参数组合
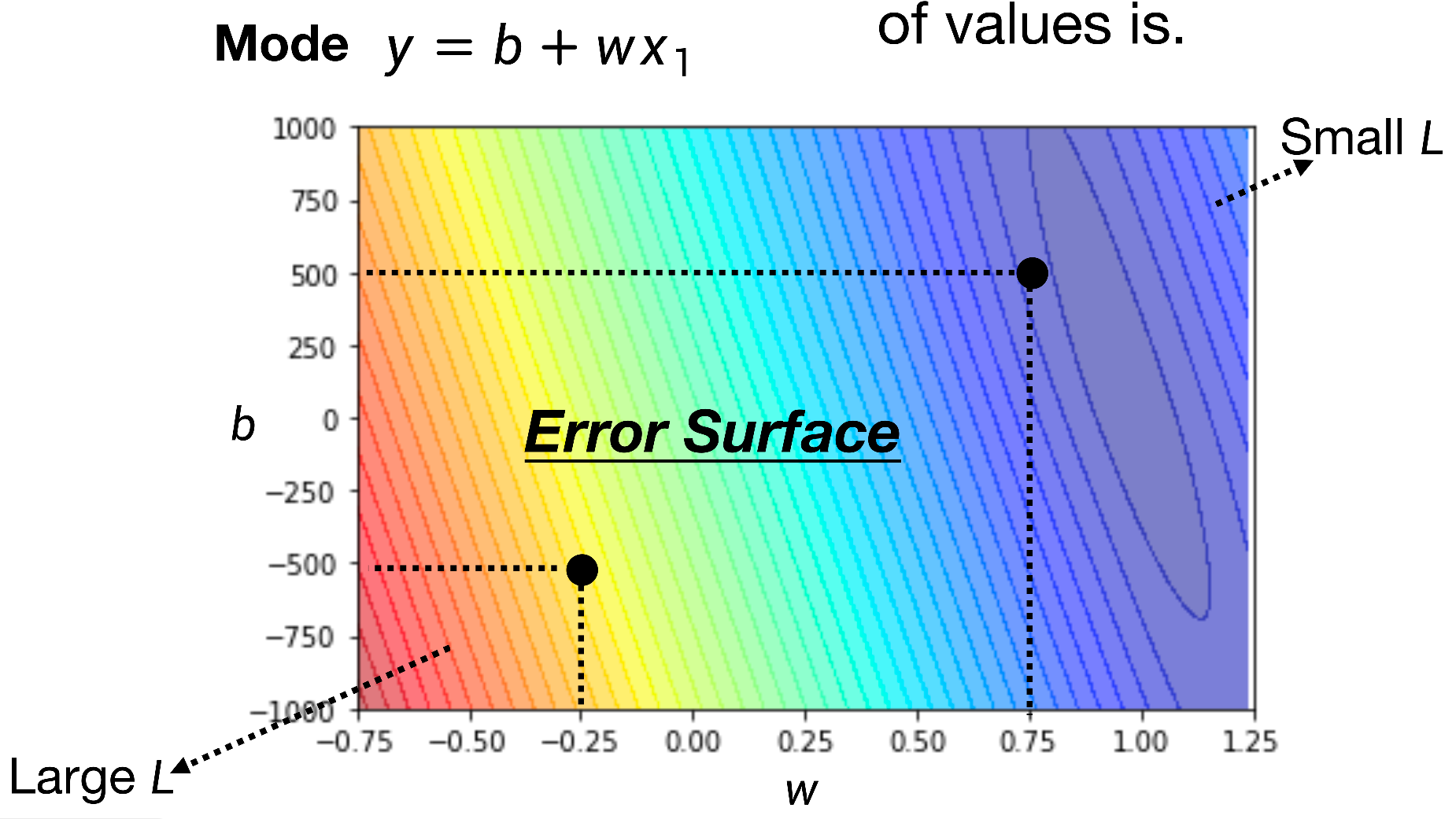
优化(梯度下降)
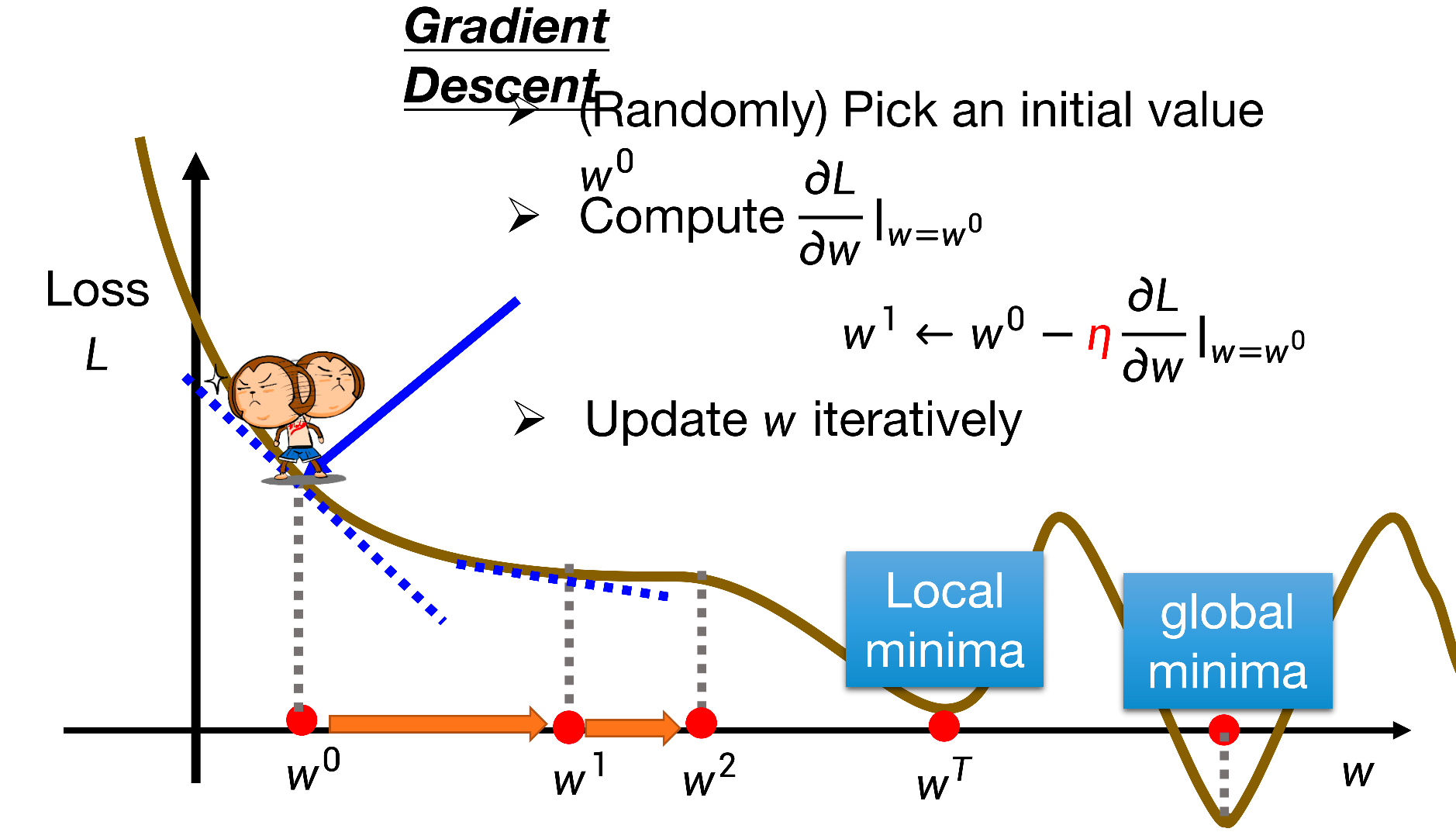
首先我们先不考虑参数b,只考虑一个参数w的情况,那么我可以通过公式,先任意选取一个w0开始计算,得到w0在整个损失函数曲线上的斜率。如果斜率为负数,说明还能向右移,相反则向左移,一旦达到0值,我们就认为找到了一个局部的最优解
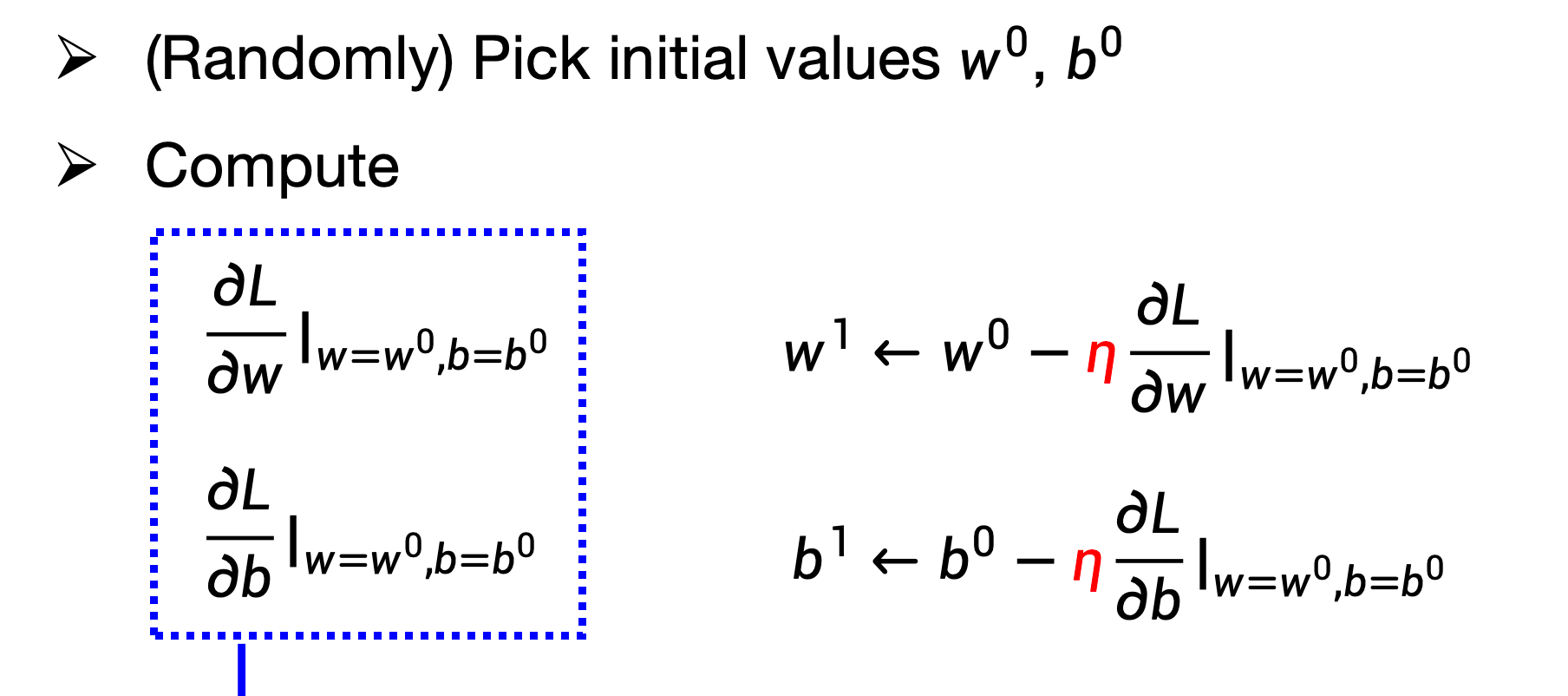
同理,把参数扩展到两个,比如初始下是w0, b0,可以算出各自的偏导数,然后根据结果优化成w1, b1
这个过程其实是非常复杂的,理想情况就是下面的这个过程
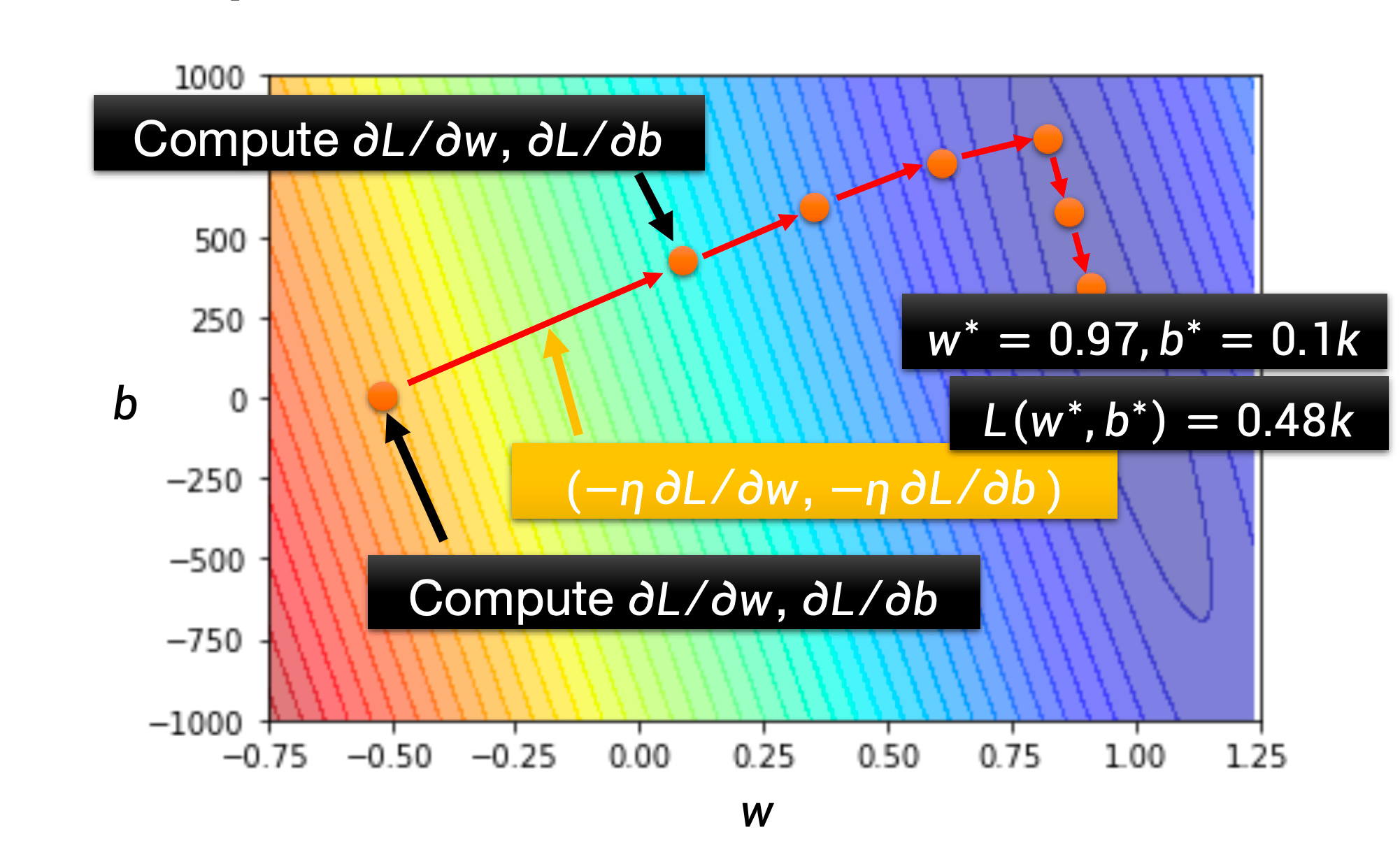
以上三个步骤的总称就是训练
