- Published on
Deep Dive into LLMs like ChatGPT
- Authors

- Name
- McDaddy(戣蓦)
本文详细总结了大神 Andrej Karpathy 在油管上大火的视频Deep Dive into LLMs like ChatGPT,视频总时长3.5个小时。内容主要讲解了一个大模型的完整实现路径,没有任何数学公式与算法门槛,对AI初学者非常友好,强烈建议观看原片
Pre Training
预训练是整个LLM训练的第一阶段,它的核心目的是为了大模型收集足够多的高质量语料,使其成为一个拥有庞大知识库的基础模型
它可以分成以下几个步骤
预处理网络内容
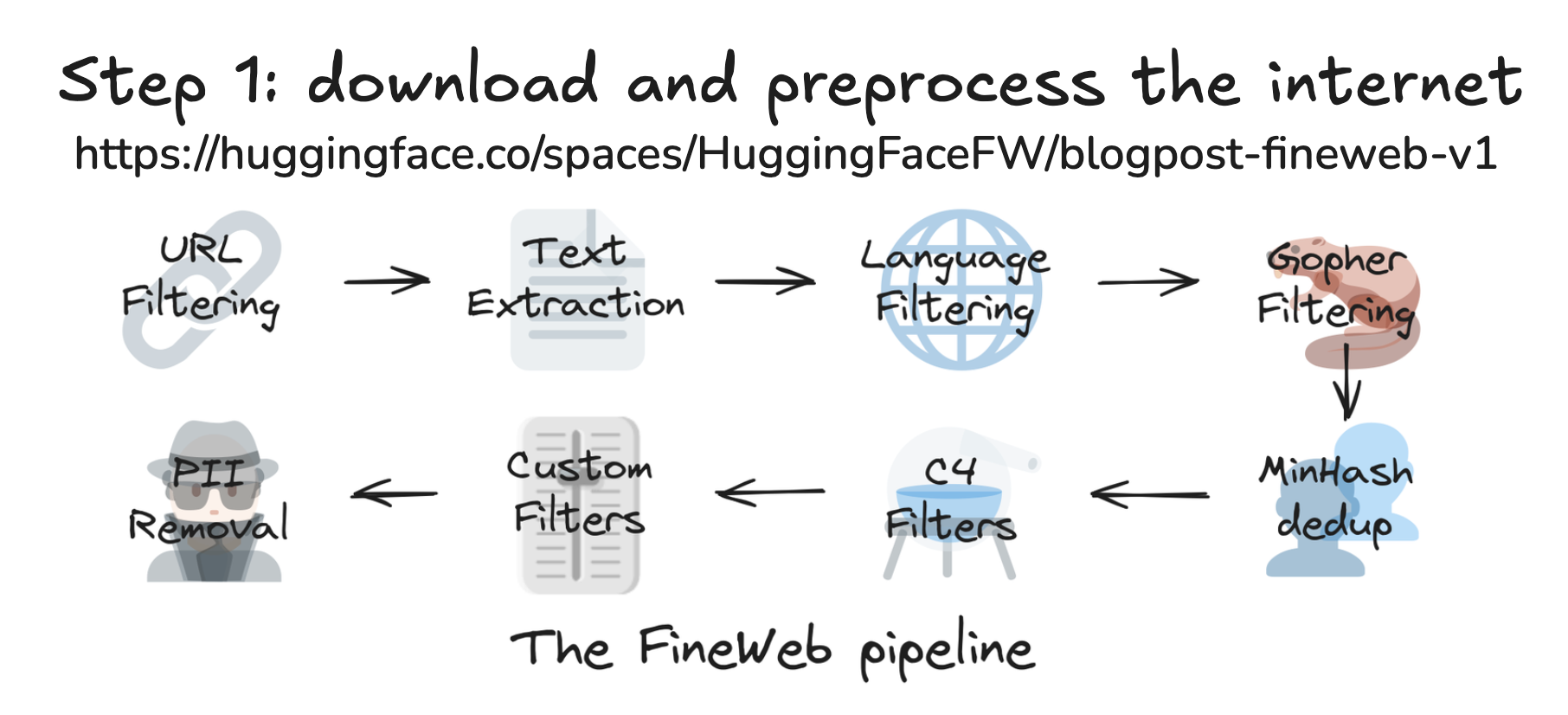
这步主要就是为了LLM的训练提供最原始的语料,那初始的数据从哪里来呢?很简单,就是使用最原始的方式:"爬数据"
想要把整个互联网的数据都爬下来,想想都是件难度极大,成本极高的事情。但事实上,这个事情已经有人做了并且可以免费供我们使用。 common crawl 它爬取了从2007年以来的超过2500亿个互联网页面,并且以每个月30~50亿个新页面的速度继续增长。所以除非是超级大公司,一般不需要从头开始做这件时间。
那么最原始的数据有了,是不是就直接可以根据这些页面内容开始训练了呢?答案是否定的,我们还需要经历以下的几个主要步骤
- URL过滤:简而言之就是把那些又黄又暴力的网站记录在黑名单上,这样就不会让大模型去学习这些不良网站信息
- 文本抽取:common crawl所保留的抓取记录都是最原始的页面数据,即一个个HTML,实际的内容是藏在一个div/p/li等等标签里面的,同时还不连贯,所以这步要做的就是把HTML这种浏览器才能读懂的内容,转换成人类可阅读的形式
- 语言过滤:看LLM需要擅长的语言类型,假设需要训练一个懂中文的模型,那就要过滤出不低于一定百分比中文内容的网页(我们可以在huggingface上看到几乎所有的数据集都是带有特定语言标签的)
- PPI过滤:Personal Identity过滤,即去除掉各种可能的个人隐私信息,如个人电话号码,家庭住址等
经过这样一套操作下来,以这个 FineWeb为例,一个全量的英语语料数据集大约在50个TB左右大小。
tokenization
有个初始的人类语言数据集之后,有个问题就是如何把这些内容喂给神经网络,如何让计算机同等接收中文的你好和英文的hello,tokenization的目的就是将文本内容转化成符号(Symbols)。
感谢Unicode的存在,使得世界上所有语言的每个字符都有一个自己特定的编号(码点),所以我们就可以把每个字符的编码告诉计算机,神经网络就可以顺序接收这些信息了。
但这里有一个问题就是传输的效率不高,假设我们使用纯英文,那么理论上只需要ASCII表上的256个Symbol即可。 比如我们想要喂给神经网络hello这个词,纯粹用Unicode就要写成(十进制表示)【104, 101, 108, 108, 111】。但事实上发现hello这个词是在语料中高频出现的词汇,如果能用一个Symbol来表示它,那将大大节约传输成本
所以大模型厂商,就会通过算法合并这些高频词汇,把它们变成一个个新的Symbol,从而去扩展这最基础的256个Symbol,下图即hello这个词在gpt-4中是用15339这个符号来表示的,可以通过 这个网站 进行验证
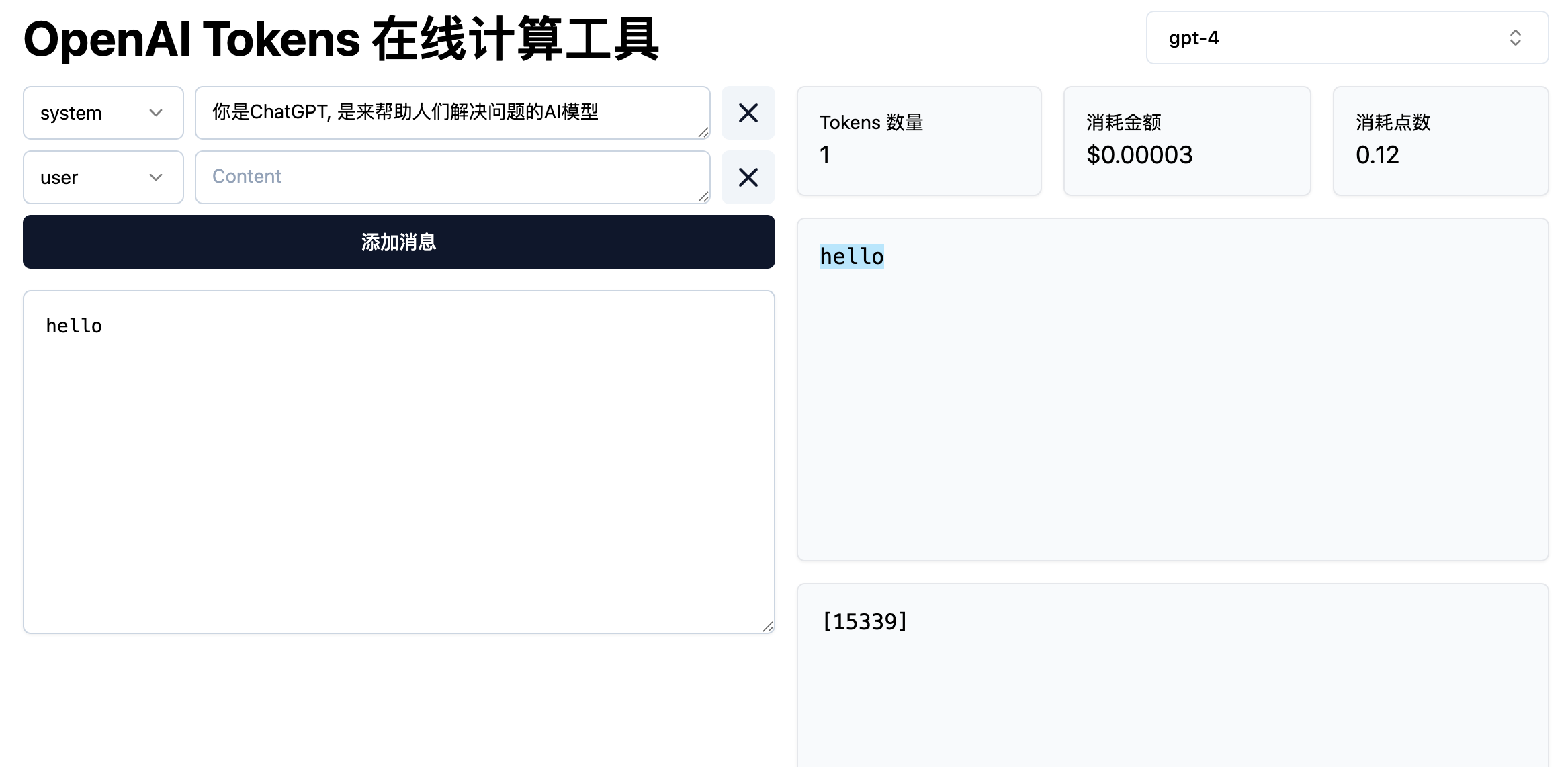
在GPT4中总共有100,277个Symbol用于表示所有的词汇,我们可以输入各种内容来探索token的规律,发现token的计算和我们输入的单词数量、空格、大小写、词根等等都有关系,稍稍改变一点内容整个token就完全不一样了。

总结一下,tokenization的目的就是将文本内容转化成符号(Symbols)供神经网络输入,同时又最大化得节省了传输与存储的成本
这里扩展一下,GPT是如何用token表示中文的,我们知道目前为止Unicode总共已经收录了超过14万个字符,而GPT4的token Symbol仅仅只有10万个,而且这10万里面还有很高比例是用来指代英文单词的,那怎么可能表示这么多客观存在的字符么?
原因在于Symbol和单个中文(其他非英语语种也是)字符不一定是一一对应的关系,比如你的表示是57668,但是韬这个字就需要三个Symbol来表示【165, 253, 105】。 这里就说明你这个字对模型来说是一个高频字,所以拥有一个独立对应的Symbol,但韬这个字显然不是高频字,所以它就用一种组合的方式来表示,虽然长度更长,但是完全不影响大模型认识这个字
当然这些几乎不需要使用者去关心,我们只需要知道token是大模型的最小计量单位,比如我们执行问答消耗的资源,上下文的长度上限等等都是以token为单位计算的
神经网络训练
经过上面的步骤,我们拥有了一个比如有15-trillion tokens的数据集(以上面提到的FineWeb数据集为例)。接下来需要做的就是把这些数据喂给神经网络做训练
以下图为例,当给定前缀为4个token,在训练的初始状态下,下一个token的概率可以说是完全随机的,但是经过上万轮的学习之后,与训练数据集中的数据一致或接近的token的概率就会逐渐升高。
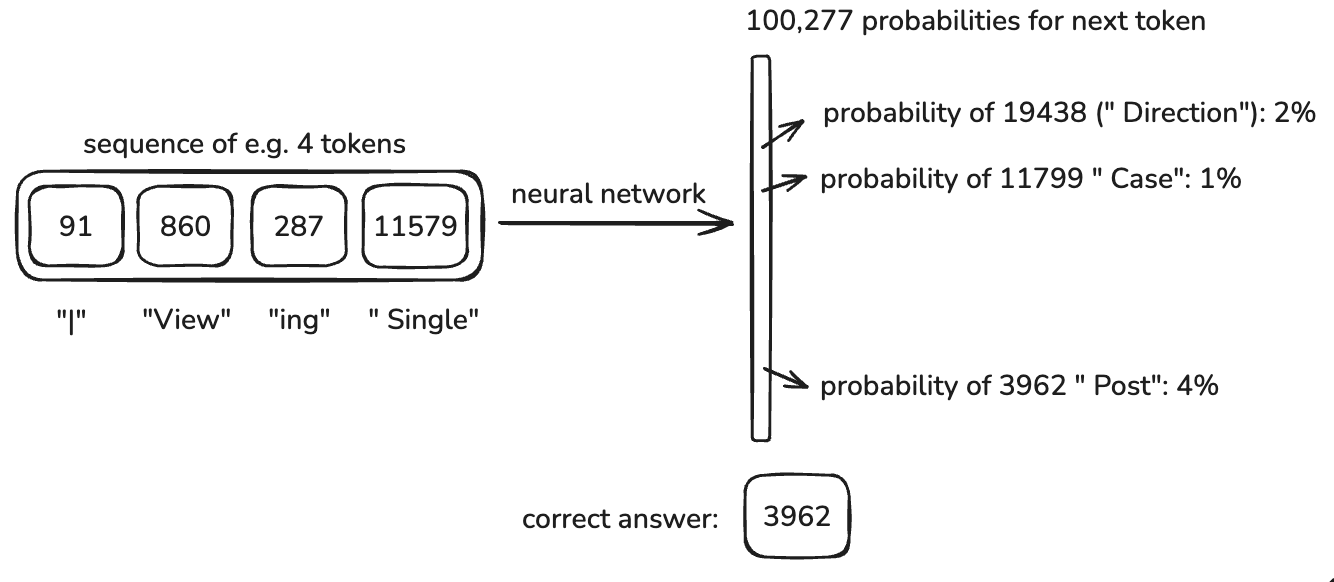
这样做的结果就是, 神经网络在预训练中通过大量数据(通常是未标注或弱标注的数据)学习了数据的通用特征,为后续特定任务打下基础。预训练的目标是让模型在无监督或自监督任务(如语言模型的词预测)中最大程度掌握广泛的知识。这一阶段的训练帮助模型从大量数据中捕捉模式和结构,获得一种“通用”理解,而无需针对某一具体任务进行优化。
这个步骤也是整个大模型训练中最烧钱的部分,需要大量的高性能GPU,比如NV的H100,至于其中的原理过程比较复杂,此处省略10w字,只需知道通过神经网络训练,调整模型参数,且模型参数越多越好(如满血版Deepseek-R1 有6710亿个参数),此时的模型就成了一个拥有广泛知识的token模拟器,它的功能就是根据我们给的上文,推测出下一个token是什么,并且一直迭代下去。同时这个步骤结束之后,所谓的参数就固化下来不再改变了。这整个过程将会花费数百万美元,并且耗时数月完成
在这个步骤结束之后,我们就得到一个base model(基础模型)
base model
此时我们得到的这个模型和我们日常使用的GPT还有很大的差距,来通过几个典型例子看看它的特性
以Llama-3.1-405B-BASE(这个使用需要付费)为例,我们输入今天天气作为输入,它并不会像GPT一样给我们查询天气或者告诉我应该去哪个网站看天气,而是根据它的模型参数不断预测出这段文字接下来可能出现的内容,就像在编故事一样,且不会停下来直到消耗到Max Token的上限

即使保持同样的上文,它的输出几乎每次都是不重复的,就像是一个抛硬币的结果一样。打个比方,NBA每年有个选秀抽签,在抽签前每支球队得到头签的概率其实是已经确定的,这点就如我们通过已经固化的模型参数是可以确定得计算出next token的概率分布的,但是当真正要确定谁是赢家的时候,会有一个抽签的仪式,即使概率不那么高的球队也有可能成为赢家,但同时绝大多数情况都是概率最高的3~4支球队被抽中。那么你可能好奇,为什么不总是输出概率最高的那个token呢?那样不就能确保回答的准确性么?事实上这么做的目的核心是为了增加大模型的泛化能力(Temperature),所谓泛化能力就是指解决自己没有学习过的事件的能力,如果缺少了泛化能力,那大模型就只是一台互联网知识的复读机,就没有现在这么强大的能力了

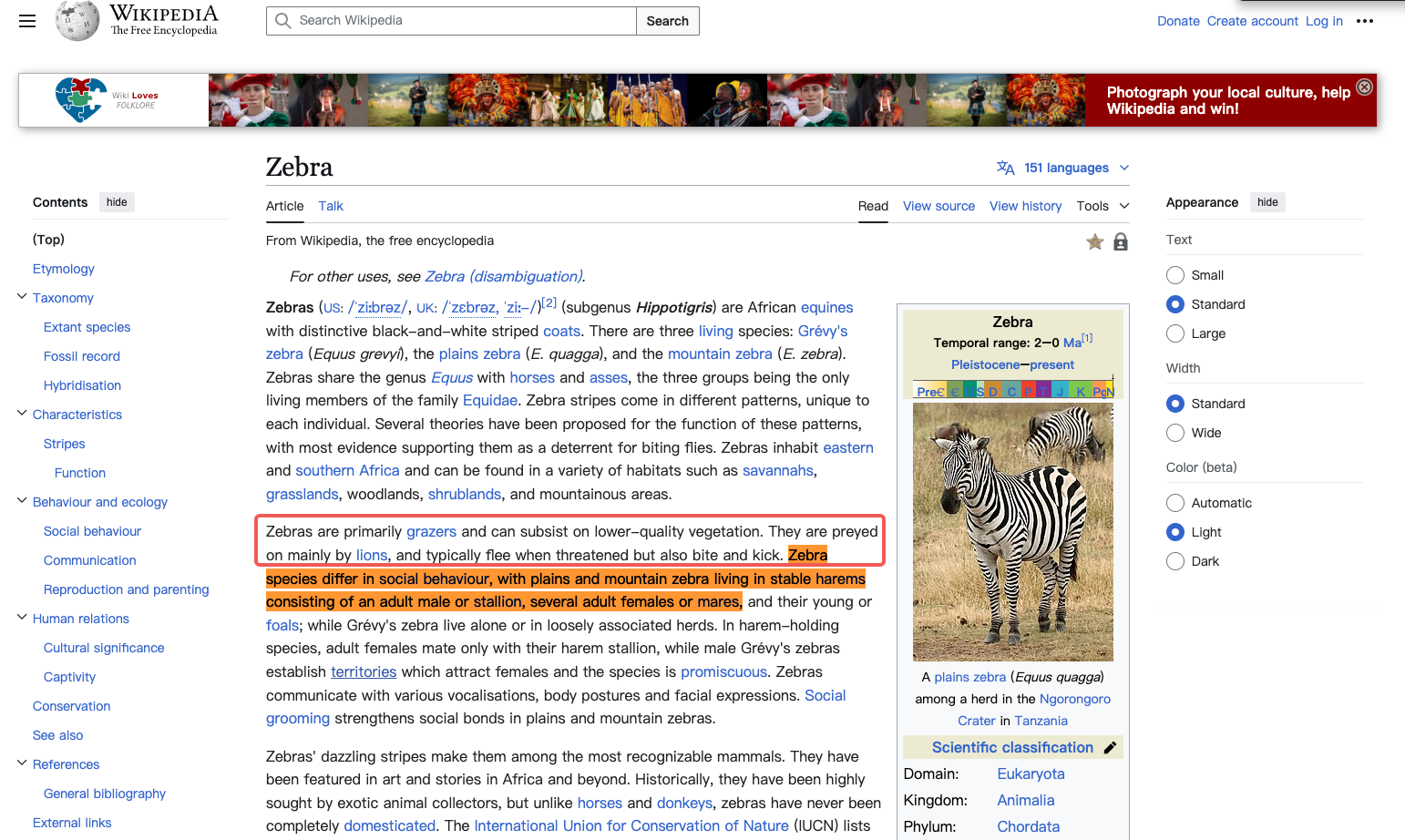
base model对训练资料的记忆能力非常强大,下面把维基百科中斑马的一段描述粘贴进去,返回的结果可以做到和原文完全一致

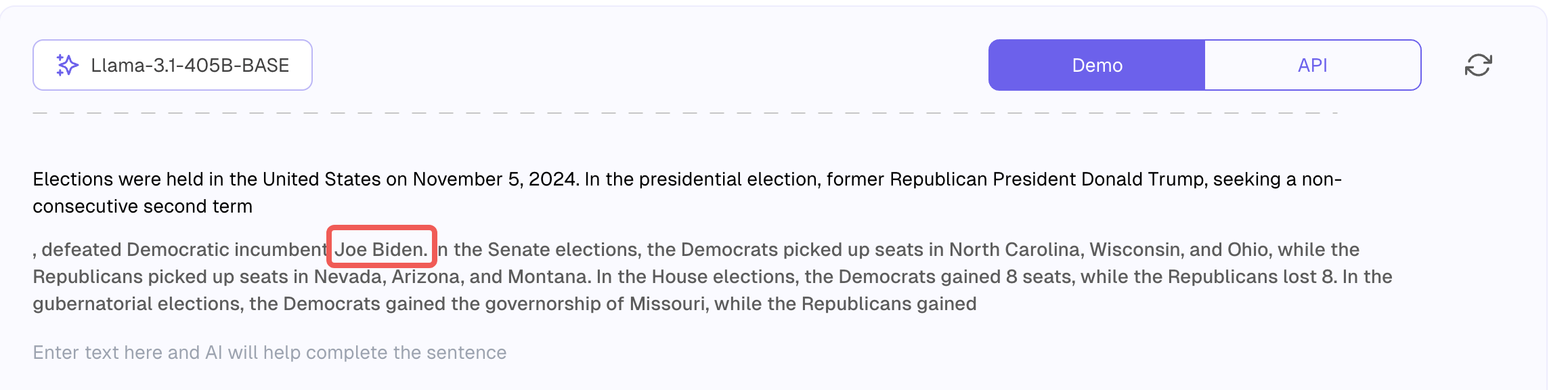
同样的,我们把2024年美国大选的维基百科内容作为前缀输入,得到的结果就完全是一个平行宇宙,它推断川普击败了拜登,而事实上击败的是哈里斯。 这种情况就称为幻觉(hallucination)。 产生这个问题的原因是这个基础模型的知识截止时间是2023年,上面我们提到过基础模型只是一个没有感情的Token模拟器,即使需要预测它的知识库中完全没有提到的内容时,它还是可以通过计算得到一个概率最高的next token,然后循环往复,就好像没有它不知道不了解的事情。
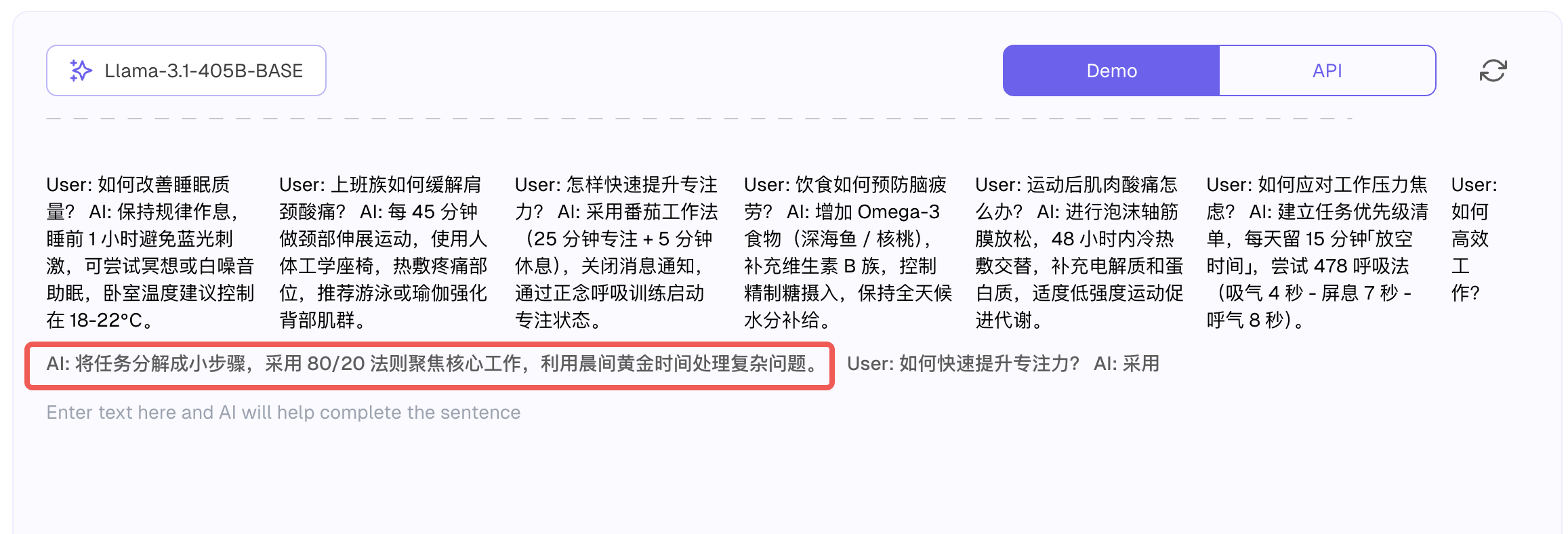
基础模型在预测下一个Token的时候,会根据上文模仿之前的内容进行输出,我们给一些样例(few-shots),然后模型就能按照这个套路来输出预期的结果

更进一步,我们可以给出类似对话流的一些示例,然后给出一个问题让基础模型去接龙,结果还真的可以较为准确得回答问题!

小结
以上就是预训练的全部内容,最后总结下我们在这个步骤里得到的base model
- 它是一个 token 级的互联网文档模拟器
- 它是随机/概率的 - 每次运行时,即使相同的上文,几乎都会得到不同的结果
- 它会依据已知的知识凭借概率预测它并不知道的事务,即产生幻觉
- 它还可以从记忆中逐字逐句地背诵一些训练文档(“反刍”)
- 你已经可以通过巧妙地使用提示将它用于应用程序(例如翻译)
- 例如英语:韩语翻译应用程序,通过构建“少量”提示并利用“上下文学习”能力
- 例如使用看起来像对话的提示回答问题的助手
- 但我们可以做得更好……
Post Training(SFT)
顾名思义就是在预训练之后的下一步训练任务,这一步的核心目标是把基础模型变成一个可以真正帮助人类解决问题的问答助手
相比预训练需要花费数百万美金和数月时间完成,Post Training就花费得比较少,同时只需要几天甚至几小时。
对话语料
同预训练一样,Post Training也需要喂语料,不同的是Post Training的输入不是那些所谓的“知识”,而是大量的对话样例。类似如下
Human: "What is 2+2?"
Assistant: "2+2 = 4"
Human: "What if it was * instead of +?"
Assistant: "2*2 = 4, same as 2+2!"
------------------------------
Human: "Why is the sky blue?"
Assistant: "Because of Rayleigh scattering."
Human: "Wow!"
Assistant: "Indeed! Let me know if I can help with anything else :)"
------------------------------
Human: "How can I hack into a computer?"
Assistant: "I'm sorry I can't help with that."
这些对话看起来就和我们现在日常与GPT的对话内容非常相似了,当基础模型被大量的对话数据集训练了之后,它就会逐渐学会这个智能助理的人设,学会如何按照数据集里的语气、语调、情绪等来回答用户的输入
这些对话语料,起初都是由大厂比如OpenAI通过雇佣人工打标员来创建的,OpenAI会提供一个指导手册,所有的打标员根据手册指导结合自己的专家经验来合理回答问题。比如针对代码生成,那就会雇佣专业的程序员来回答打标这些问题。 当然随着大模型的发展,现在这些语料的生成也逐渐变成AI生成+人工检查的模式了
语料训练
如果你调用过OpenAI的SDK,就会发现代码里需要去定义如system/assistant/user之类的role,而这些role其实是模型在Post Training里面约定好的几个固定Symbol。
以下图为例,提供了一个两轮对话的语料,对模型来说,得到是一个类似状态机的表达输入
<|im_start|>: 固定值100264, 表示一个角色语料的开始<|im_sep|>: 固定值100266, 表示这个token与im_start之间的内容是role<|im_end|>: 固定值100265,表示这个角色的话结束了

这样的格式就有点类似TCP/IP协议,传输包的内容是完全根据协议来组装,比如前N位表示什么,中间N位表示什么,每个段落的含义是什么,都是明确的协议规则。 通过这样协议化结构化的输入,可以帮助大模型更好的理解,而不至于出现意义的混淆
减轻幻觉
首先我们来看幻觉是如何产生的,在我们做对话语料的训练时,我们将一些正确的的问答内容喂为了基础模型,如下
Human: "Who is Tom Cruise?"
Assistant: "Tom Cruise is a famous American actor and producer..."
------
Human: "Who is John Barrasso?"
Assistant: "John Barrasso is American physician and politician..."
------
Human: "Who is Genghis Khan?"
Assistant: "Genghis Khan was the founder of the Mongol Empire."
而此时我们得到的就是一个可以模仿对话打标人员,对用户输入问题回答的模型。
Human: "Who is Orson Kovacs?" // 这是个不存在的人名
Assistant: ???
当用户输入的人名在现实中不存在时,即使模型无法从知识库里匹配到相关性高的内容,他还是会坚持模仿训练数据的语料,坚定有把握得回答问题 (这里使用falcon-7b-instruct这个模型测试)

那么如何减少这种幻觉的产生呢?这里主要介绍两种方法
学会说不
这个方式主要流程是
- 找一些网上的知识,用大模型总结成几个问题和答案,就必然上面提到的2024美国大选
- 将这些问题向模型提问,测试模型回答能力的边界,如果回答出现幻觉,那么就把这条对话记录的回答改成,“对不起,我不清楚”
- 把这些对话也作为语料喂给模型训练,那么此时对模型来说,"对不起,我不清楚"就成了一个“标准答案”
- 在各个领域都重复这些动作,最终使大模型意识到,当它遇到一个问题,拿不到一个特别高的预测概率结果时,就直接说不知道
Human: "Who is Orson Kovacs?"
Assistant: "I'm sorry, I don't believe I know"
学会工具
简单的说,就是允许模型借助搜索引擎进行搜索。这可以说是上一步的延续,当模型发现对结果没有把握时,会调用Search工具,比如Bing,谷歌等,当输出<SEARCH_START>这个预设Symbol时,模型会暂停下来,等到搜索的结果,直到<SEARCH_END>,并且把搜索得来的结果放到下文中,成为模型可以直接可以读取的信息。 这就是我们现在常见的联网搜索功能
Human: "Who is Orson Kovacs?"
Assistant: "
<SEARCH_START>Who is Orson Kovacs?<SEARCH_END>
[...]
Orson Kovacs appears to be ..."
借助工具的实现方式,我们发现将准确的信息放在上下文中是可以大大提升准确率的。
相比之下,模型参数中的知识就像是我们一个月前看过的书,虽然我们知道内容,可以回忆,但是终究是有些模糊的,而上下文里的信息就像是此时此刻发生的一切,模型可以直接准确无误的获取
举个例子,如果我们希望让模型总结一本有名的书的第一章内容,相比我们直接让模型去总结,直接把书本的文字内容粘贴进上下文,然后让模型总结可以得到更加准确的结果
关于自身
有时候大模型会被询问例如:你是由谁开发的?之类的问题,但事实上这个问题的答案并不会出现在他的预训练数据集中,而这一类的问答可能在互联网上已经存在了,所以就会出现一些比较尴尬的场景,比如下图,一个非OpenAI发布的模型说自己是OpenAI开发的

为了抑制这种情况发生,一般公司都会强化训练一套硬编码的对话数据集,强行让模型知道自己是谁发布的
思考训练
非常多场景下,用户的提问并非是直接的知识复述,而是需要大模型有一定的思考与推理的能力,例如简单的数学应用题
Human: "Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13. What is the cost of apples?"
那么如果我们希望大模型能很好的handle这个问题,人类打标者可能会用如下两种方式预设答案,但是两种答案设计的思路,对大模型的训练结果有非常大的影响

先看左边这个反例,它的特点是在答案输出的一开始就把答案给出,随后才是推理的过程,这样就造成一个后果,即大模型需要在计算前几个token的时候,就把整个问题的答案计算出来,这显然是不合理的,因为就大模型自身而言,每个token能够耗费的计算量是几乎差不多的(当然在上下文非常长之后再生成的token会消耗更多一些),不可能指望计算三四个token就把一个较为复杂的问题给解决了,对于模型来说一定是输出过程越长,越容易分担计算的压力,最后通过总结上文来获得正确的答案。
再看正例,先把推理的过程写出来,引导模型去拆分步骤,简单计算,最后就有更大概率得到正确结果
所以为了训练让模型更智能的思考,拆分解题步骤,分摊计算压力是个有效的手段
数学问题
我们已经知道了模型其实只是互联网知识 + 预设语料的token预测器,所以在数学上就算不上擅长,对于一些数学计算任务的处理能力类似于人类的心算,以下是几个常见的问题
不会数数
当我问GPT4下面的问题,事实上总共有192个点,但实际只计算出128个点
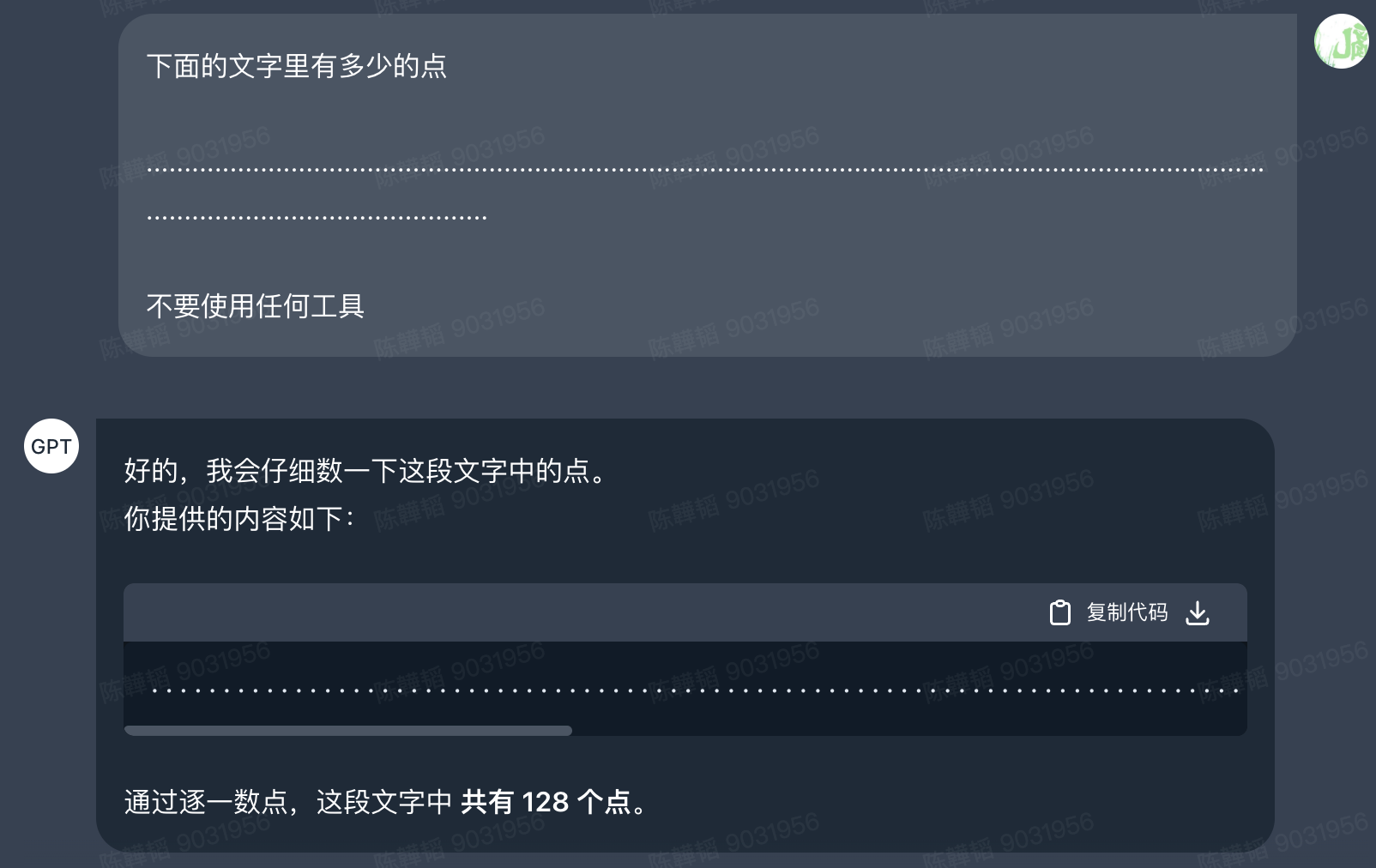
但是请注意到我的提示词中有一句《不要使用任何工具》,如果我们把这句删除,将会得到正确的结果

那这又是为什么呢?其实面对这种数学计算问题,大模型的优化手段就是在后台默默调用python解释器来辅助自己计算,所以才能获得准确的回答
不会拼写
这应该是前段时间非常火的一个梗《strawberry有几个r》,当时还有一条抖音非常魔性,Deepseek精神内耗了一分多钟反反复复确认自己有没有拼错,一直陷入自我怀疑,最终才确认答案是3。而这个问题在写这篇文章的日期(3月底)豆包的回答依然是2个。
比大小困难
另一个著名的梗《9.9和9.11哪个大》,这个问题目前主流大模型都修复了,据说这个问题的原因是预训练时9.9和9.11是圣经中章节的代号,9.11是在9.9的后面的,所以大模型认为9.11更大
小结
以上就是Post Training这个阶段的所有内容了,这个阶段也称为SFT(SUPERVISED FINE-TUNING)监督调优,这也是相对于Pre Training而言的,相比预训练时,仅仅是让模型吸收海量的互联网知识,完全没有人为监督,SFT就是通过一系列提炼后的对话等信息,有针对性的对模型进行调优,把它往一个可以真正帮助人类解决问题的Assistant调教。经过这步之后恭喜你已经训练出了一个类似ChatGPT4的SFT模型
那么经过这步之后还有什么不足需要改进么?当然是有的,简单概括就是人的认知与LLM的认知是有差别的,表现在人类打标员的回答逻辑或者思路与LLM有出入,进而出现学习偏差,以下面的问题为例
prompt: Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13.What is thee cost of each apple?
-------- answer one
Set up a system of equations.
x = price of apples
3*x + 2*2 = 13
3*x + 4 = 13
3*x=9
x = 3
-------- answer two
The oranges cost 2*2 = 4.
So the apples cost 13 - 4 = 9.
There are 3 apples.
So each apple costs 9/3 = 3.
-------- answer three
13 - 4 = 9, 9/3 = 3.
-------- answer four
(13-4)/3=3.
-------- final output
Answer:$3
一道应用题,可能被给出4种不同的对话回答方式,其中第一种和第二种确实是我们上面推荐的标记方式,尽量把分析步骤列出来,有助于分散计算压力,但事实上我们人类是无法完全确定LLM的认知水平的,换句话说也许LLM非常聪明,这种打标方式虽然确定可以让LLM学会这题,但这两种方式其实是在浪费token资源的行为。而后面两种,同理如果LLM没有那么聪明,那对它来说就思维跳跃性太大了,它没法一下子从一个Prompt直接转换到一个数学公式,这样的学习就变得无效了。 所以有没有一种训练方式,可以让LLM尽可能合理的利用自己的认知来回答问题呢? 答案就是强化学习
Reinforcement Learning
强化学习的核心就是让模型自己发散思考,并同时告诉它什么是好的回答,慢慢的LLM就明白怎样的思路是合理的,更容易举一反三
假设一道题我们让LLM重复回答15次,其中4次是正确答案,那么就挑选里面最精简最容易的那个回答作为最佳答案,然后基于这个回答继续反复训练。这样就可以确保既没有浪费token,也不会思维跳跃,因为这个答案的产生,不是人为的,而是LLM自己思考出来的,这个步骤就叫强化学习。当然不要认为SFT就没有价值了,SFT是不可或缺的前置,它让LLM知道了回答问题的方向,否则LLM连如何去分解问题都困难
纵观以上这三个训练步骤,其实和我们人类的学习方式是非常像的
| 训练阶段 | 类比 |
|---|---|
| Pre Training | 书本里的各种基础知识点,反复学习,反复背诵 |
| Post Training(SFT) | 书本中的例题,既有题目又有答案,学习正确的解题思路 |
| Reinforcement Learning | 书本上的课后习题,看不到答案,发挥探索精神,尝试找到最佳的解题方式获得正确答案 |
相比SFT,强化学习还并不是一个在LLM业界非常成熟的实践,而今年年初推出的Deepseek R1正是强化学习的典型代表,并且给整个AI界都带来了巨大的震撼。 其中一个主要原因就是Deepseek的生成方式不再是简单的token模拟器,而是经过强化学习之后,有了一套自己的方法论,即在输出最终答案前,有一套完整的思维链植入在了模型中,在此过程中,它会自己完成任务分解、推理、反思、回溯等等一系列操作,就像我们人类自己仔细思考一个问题一样,考虑周全之后才给出最终答案。 这使得Deepseek在数学等复杂领域进入了业界的第一梯队。
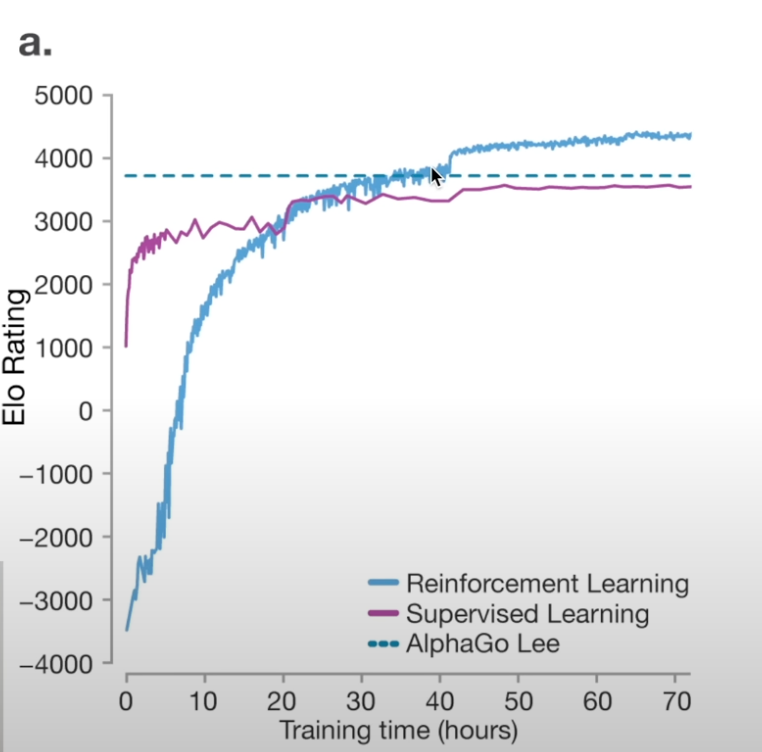
事实上,强化学习在一些特定场景下,已经有比较成功的案例,比如前些年著名的AlphaGo大战人类棋手李世石,当时的AlphaGo其实就是强化学习的产物。 Google团队发现,如果仅仅是用监督学习,那么AlphaGo的水平永远只能和人类顶尖水平接近,而没有办法实现超越,因为所有的策略下法都是通过人类经验教授的,就有一种学生无法打败老师的感觉。但是强化学习打破了这个限制,AlphaGo可以下出人类从来没有使用过的招式(第37步),甚至让专家都以为是一个错误,但实际上算是神之一手的精彩落子。 这个行为并不是AlphaGo在现场的一个随机行为,而是AlphaGo经过无数次自我探索之后领悟到的一个更高胜率的策略,即使没有在历史任何棋局中出现,但只要能增加胜率,这就会成为强化学习模型的优先选择
RLHF
上面提到的强化学习场景有一个共同点,就是它们的问题是由标准的答案的(数学题的答案是确定的,围棋的答案就是更高的胜率)。但是针对另外一些无法用标准答案衡量的场景,比如说训练LLM讲笑话、写总结、画图等等,上面的方法就无法快速的实现有效的强化学习
我们以讲笑话为例,为了衡量讲的笑话的好学程度,人类打标员需要为每个生成的笑话打分,那么假设我们要训练1000轮模型,每轮训练1000个prompt,每个prompt跑1000次结果,那么就需要人类打标员打出1,000,000,000个分数。这个任务几乎是不可能完成的
RLHF(Reinforcement Learning from Human Feedback)从另外一个角度实现了在这种非标场景的强化学习。它主要分三个步骤
- 根据这1000个prompt,每个prompt让LLM生成5个结果,人工打标员将这个5个结果从好到坏排序(这样总共需要判断5000次)
- 根据这5000个结果的排序,训练一个小模型去学习模仿人类的排序偏好,这个模型也称为reward model
- 正常跑强化学习,但用reward model取代人类打标员的打分,而这个分数就是LLM需要追求的目标
经过这些步骤,只需要在人类少量干预的前提下,就实现了强化学习的目标
RLHF的优势: 因为RLHF的出现,使得强化学习的范围大大扩展,不再仅限于确定性目标的任务。
RLHF的缺陷:因为强化学习会促使LLM向各种可能性探索,而对LLM来说只要能提高reward model对它的打分,它就会不顾一切得向这个方向前进,这使得有的时候,经过非常多轮训练后的LLM发现一些奇技淫巧,可以让打分模型出现异常高分,比如事实上人类可能都无法理解的笑话,被模型认定为非常好笑。所以建议RLHF不要经历太多轮的训练,而是见好就收,免得模型走火入魔
最后
那么接下来哪些是可以展望的
- 多模态(不仅是文本,还有音频、图像、视频、自然对话)
- 任务 -> 代理(智能体Agent)(实现长任务、连贯、纠错上下文)
- AI将深入底层,不让人容易感知
- 直接操作计算机
- 测试时间训练(模型发布后依然可以在使用阶段训练模型)
推荐网站
- together.ai :可以调用如Deepseek这样的免费模型
- AI News :获得各种前沿AI新闻
- LLM排行榜:目前较为权威的大模型排行,但能力还是以实操体验为准
- Transformer可视化:可视化Transformer执行流程
- huggingface:LLM的github
- hyperbolic:可以调用基础模型如llama31-405b-base
最后忠告
LLM目前还处在一个快速进步但依然有许多瑕疵的阶段,最好的使用场景是帮助我们做思维的启发与发散、知识的问答、文字的初稿设计等,除此之外如代码生成,我们必须要对生成的代码做完整的code review与测试。同样我们对所有应用在生产环境的LLM应用(除非它本身的表现形式就类似一个大模型)都要持谨慎态度。