- Published on
React v18全解析
- Authors

- Name
- McDaddy(戣蓦)
从JSX到js数据结构
Jsx看起来是HTML,但是在经过编译器的转化后,在浏览器中运行时其实是一段js代码。而这个过程一般都是通过编译工具的插件完成的,比如babel,vite的react插件等
以下就是通过babel转换source code的示例
const babel = require('@babel/core');
const sourceCode = `
<h1>
hello<span style={{ color: 'red' }}>world</span>
</h1>
`;
process.env.NODE_ENV = 'development';
const result = babel.transform(sourceCode, {
plugins: [
["@babel/plugin-transform-react-jsx-development", { runtime: 'automatic' }]
]
});
console.log(result.code);
// var _jsxFileName = "";
// import { jsxDEV as _jsxDEV } from "react/jsx-dev-runtime";
// /*#__PURE__*/_jsxDEV("h1", {
// children: ["hello", /*#__PURE__*/_jsxDEV("span", {
// style: {
// color: 'red'
// },
// children: "world"
// }, void 0, false, {
// fileName: _jsxFileName,
// lineNumber: 3,
// columnNumber: 8
// }, this)]
// }, void 0, true, {
// fileName: _jsxFileName,
// lineNumber: 2,
// columnNumber: 1
// }, this);
这里我们用了@babel/plugin-transform-react-jsx-development这个babel插件,专门用转换在development模式下的jsx,注意这里的runtime需要改成automatic否则默认是classic,如果用classic就会变成旧版的React.createElement的形式
结果转义的代码主要有以下作用
- 从
react/jsx-dev-runtime引入了一个叫jsxDEV的方法,如果是非dev模式下,会从react/jsx-runtime来引入jsxRuntime - 用jsxDEV这个方法包裹住一个数据结构对象,这里就是被解析后的jsx的数据结构表示
- 注意,在这里的children里还会包jsxDEV,也就是说所有的tag转义后最终都会被jsxDEV所包裹。但是当仅仅是个纯字符串的时候这个包裹会省略(这也是一种优化)
那么上面这段代码要在ESM的环境中运行,就必须安装react的模块了
构建虚拟DOM
如果我们把入口文件main.jsx改成如下内容
let element = (
<h1>
hello1<span style={{ color: "red" }}>world</span>
</h1>
);
console.log(element);
通过上面的内容,我们已经知道它会转变成的真实运行时代码,所以我们需要去实现react/jsx-dev-runtime这个模块
重点看下面的jsxDEV
- 它的第一个参数是这个元素的类型,这里是h1
- 第二个参数它的配置,可以理解为props,里面包含了children,key等受保护字段
- 最后返回一个ReactElement,就是我们所说的虚拟DOM
- $$typeof是一个特殊的字段,用来标识React虚拟DOM的类型
import hasOwnProperty from "shared/hasOwnProperty";
import { REACT_ELEMENT_TYPE } from "shared/ReactSymbols";
const RESERVED_PROPS = {
key: true,
ref: true,
__self: true,
__source: true,
};
function hasValidKey(config) {
return config.key !== undefined;
}
function hasValidRef(config) {
return config.ref !== undefined;
}
function ReactElement(type, key, ref, props) {
return {
//这就是React元素,也被称为虚拟DOM
$$typeof: REACT_ELEMENT_TYPE,
type, //h1 span
key, //唯一标识
ref, //后面再讲,是用来获取真实DOM元素
props, //属性 children,style,id
};
}
export function jsxDEV(type, config) {
let propName; //属性名
const props = {}; //属性对象
let key = null; //每个虚拟DOM可以有一个可选的key属性,用来区分一个父节点下的不同子节点
let ref = null; //引用,后面可以通过这实现获取真实DOM的需求
if (hasValidKey(config)) {
key = config.key;
}
if (hasValidRef(config)) {
ref = config.ref;
}
for (propName in config) {
if (
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName) // 过滤掉被保护的字段
) {
props[propName] = config[propName];
}
}
return ReactElement(type, key, ref, props);
}
上面代码最终结果如图
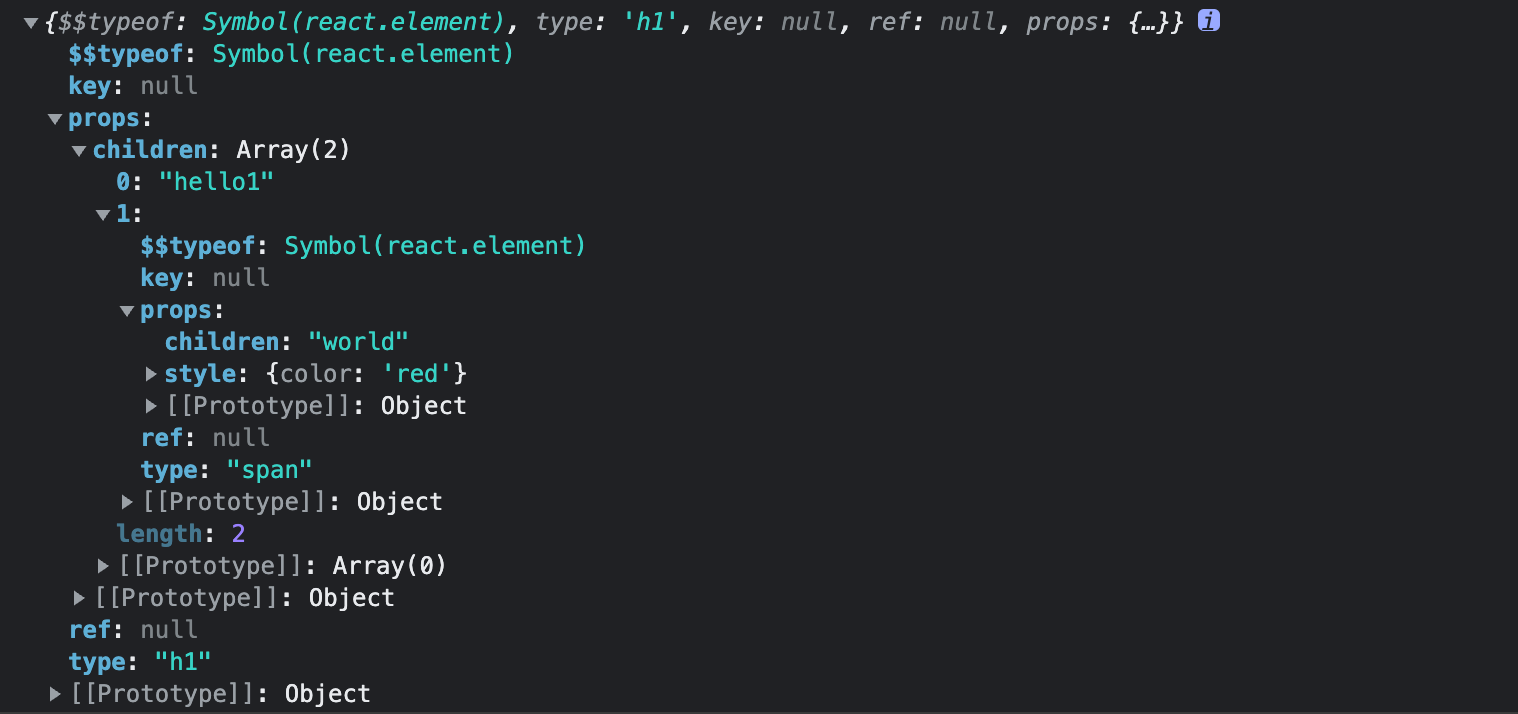
创建 ReactDOMRoot
这步对应React18中的创建根节点语法,const root = createRoot(document.getElementById("root"));
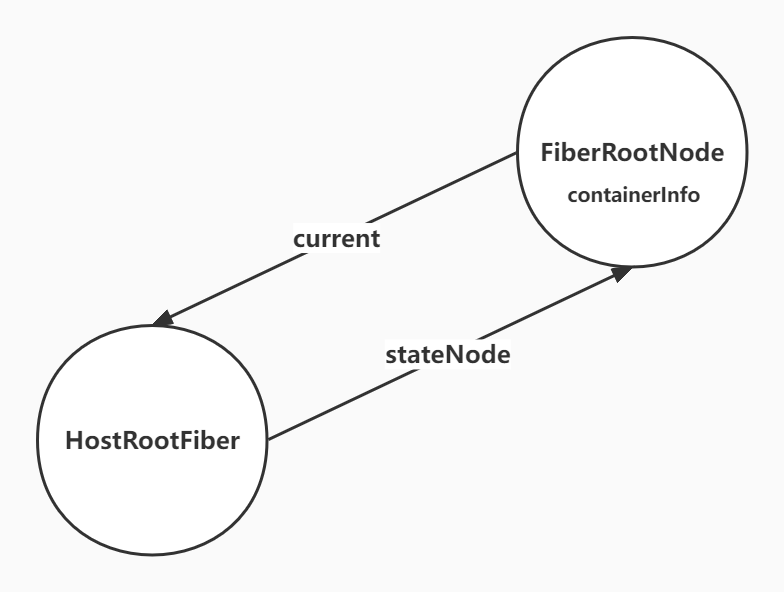
接下来开始构建这个React的Root,ReactDOMRoot主要包括以下几部分
- FiberRootNode:
- 包含一个containerInfo,其实就是根的真实DOM(div#root),
- 有个current属性,指向HostRootFiber
- HostRootFiber:
- 是一个特殊Fiber节点,
- 有一个stateNode属性,指向FiberRootNode,所以这是一个类型循环链表的结构
import { createHostRootFiber } from './ReactFiber';
import { initialUpdateQueue } from './ReactFiberClassUpdateQueue';
function FiberRootNode(containerInfo) {
this.containerInfo = containerInfo;//div#root
}
export function createFiberRoot(containerInfo) {
const root = new FiberRootNode(containerInfo);
//HostRoot指的就是根节点div#root
const uninitializedFiber = createHostRootFiber();
//根容器的current指向当前的根fiber
root.current = uninitializedFiber;
//根fiber的stateNode,也就是真实DOM节点指向FiberRootNode
uninitializedFiber.stateNode = root;
initialUpdateQueue(uninitializedFiber);
return root;
}
一个标准的Fiber Node的实现,这里注意这个tag,它是用来区分当前Fiber是Root还是原生元素或是组件的标志
export function FiberNode(tag, pendingProps, key) {
this.tag = tag; // Fiber类型 对应容器根节点/原生节点/纯文本节点/类组件/函数组件等
this.key = key;
this.type = null; //fiber类型,来自于 虚拟DOM节点的type span div p
//每个虚拟DOM=>Fiber节点=>真实DOM
this.stateNode = null; //此fiber对应的真实DOM节点 h1=>真实的h1DOM
this.return = null; //指向父节点
this.child = null; //指向第一个子节点
this.sibling = null; //指向弟弟
//fiber哪来的?通过虚拟DOM节点创建,虚拟DOM会提供pendingProps用来创建fiber节点的属性
this.pendingProps = pendingProps; //等待生效的属性
this.memoizedProps = null; //已经生效的属性
//每个fiber还会有自己的状态,每一种fiber 状态存的类型是不一样的
//类组件对应的fiber 存的就是类的实例的状态,HostRoot存的就是要渲染的元素
// 如果是函数组件,就是hook链表的头
this.memoizedState = null;
//每个fiber身上可能还有更新队列
this.updateQueue = null;
//副作用的标识,表示要针对此fiber节点进行何种操作
this.flags = NoFlags; //自己的副作用
//子节点对应的副使用标识
this.subtreeFlags = NoFlags;
//替身,轮替 在后面在DOM-DIFF的时候会用到
this.alternate = null;
// 用在数组中
this.index = 0;
}
最终就会得到这样一个对象
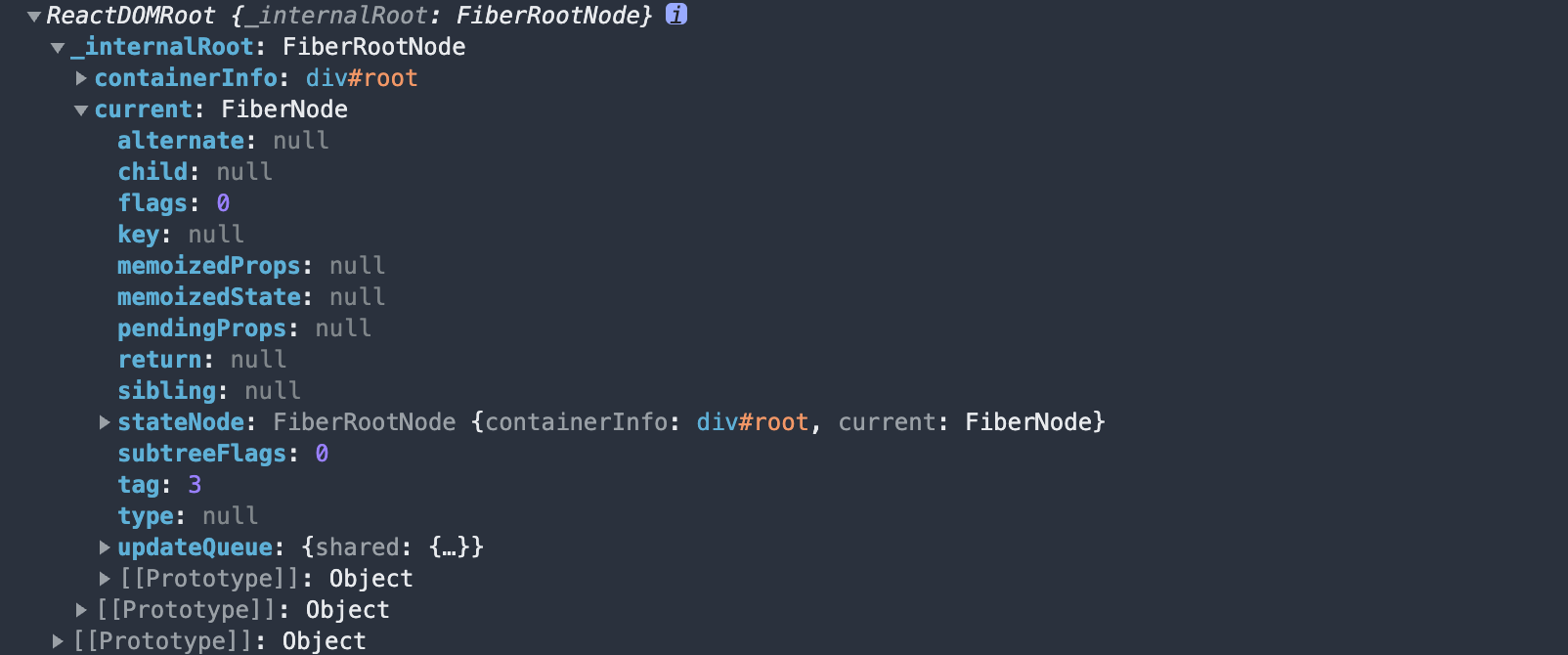
更新Root(初次渲染)
这步对应React18 渲染root的方法 root.render(element);
主要有以下这些步骤
- 创建一个update对象,里面包含一个payload就是传入的element,即表示接下来要去更新渲染这个element
- HostFiberRoot(本身就是个Fiber)上有个updateQueue属性,把上面的update添加到这个queue上面去,这个queue是一个单向循环链表
- 开始渲染,第一次渲染必然是同步渲染
- 根据当前的HostFiberRoot创建一个新的Fiber节点,新的节点基本和老的节点一样,其中alternate属性新老节点互相指向对方,这是为了最后渲染时做轮替用的,即双缓存结构,使页面一次性切换不卡顿
- 开始工作循环
工作循环
即workLoopSync方法,可以说是Fiber架构的核心方法之一
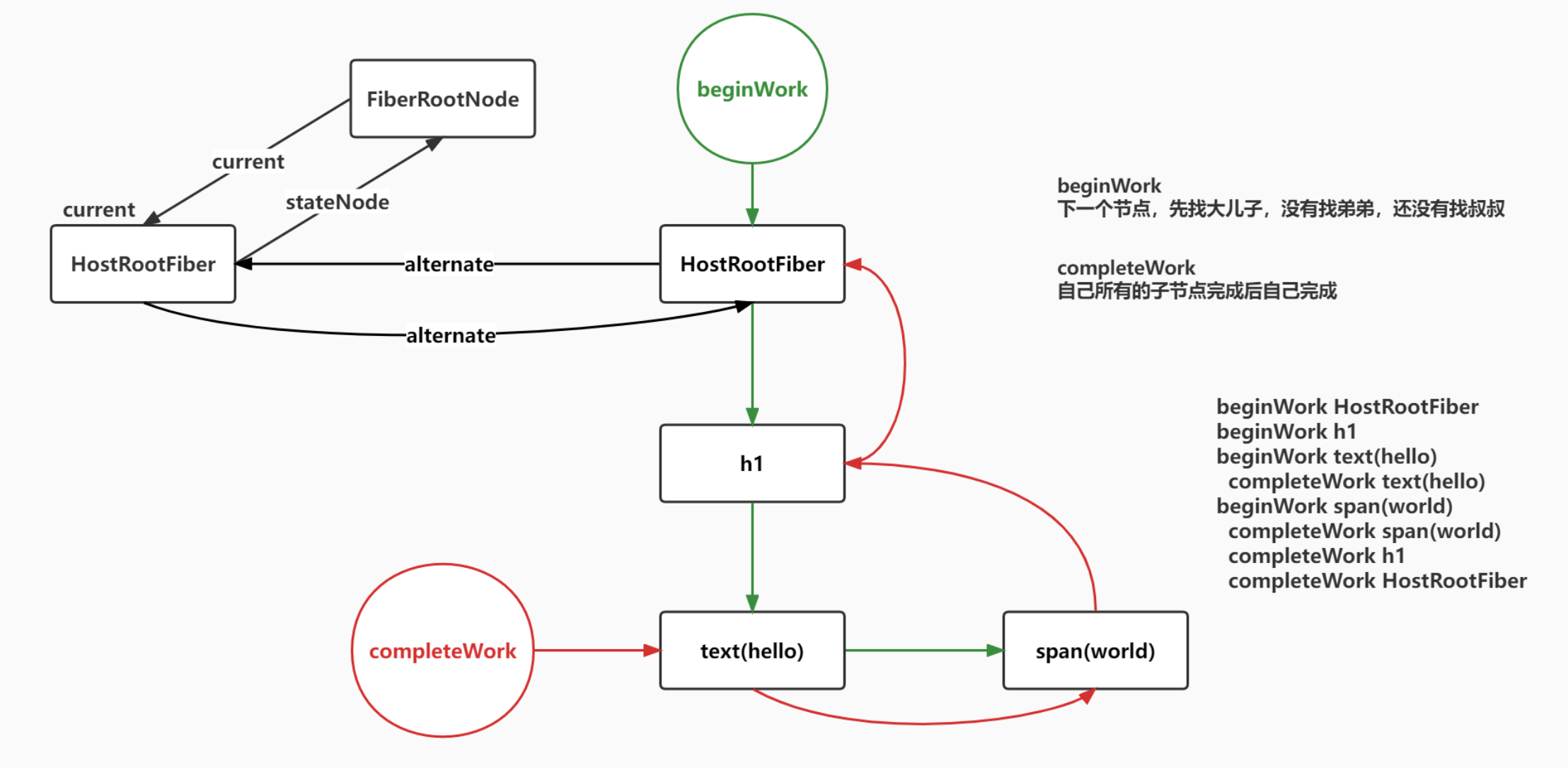
以下是Fiber链表结构
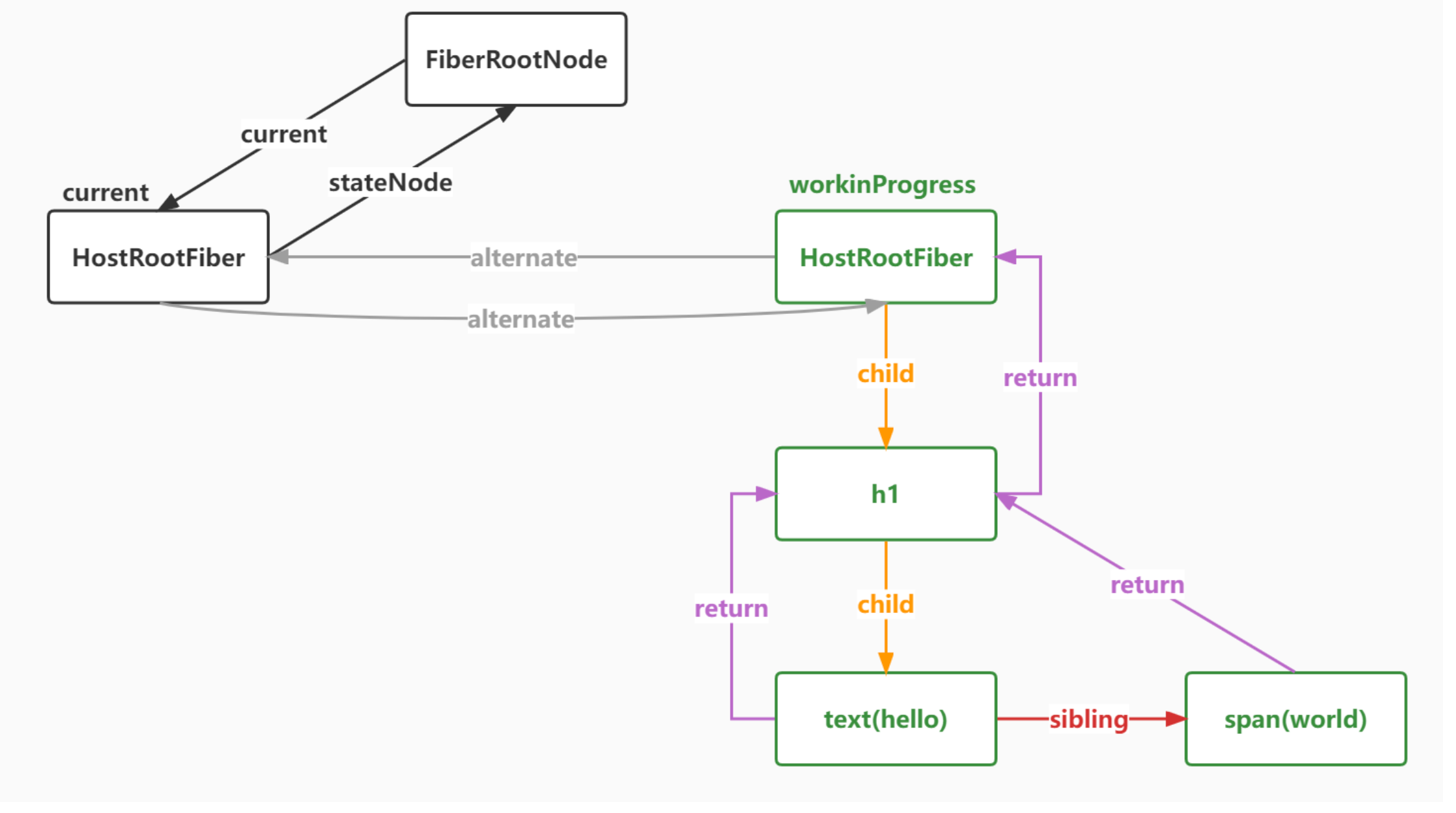
以下是遍历Fiber树的顺序,总结就是有儿子处理儿子,没儿子处理弟弟,否则处理父(叔)
现在的绿线是beginWork的路线,红线是compeleteWork的路线
每个节点都会被有且仅有一次的begin和compelete
全局定义一个workInProgress,也是一个Fiber,表示当前正在处理的Fiber节点
把当前的workInProgress传入工作单元函数执行,直到workInProgress为空为止
let workInProgress = null;
function workLoopSync() {
while (workInProgress !== null) { // 只要workInProgress不为null,就要执行工作单元
performUnitOfWork(workInProgress);
}
}
performUnitOfWork
处理每一个Fiber节点,目标是递归得把每个Fiber的结果 // TODO
unitOfWork:即新的刚创建Fiber节点,它的alternate就是当前已经存在的Fiber节点(如果是新插入的元素那也可能不存在)
beginWork: 根据新旧节点,得到当前节点的child和memoizedProps(对updateQueue的消化)
经过beginWork之后
- 如果发现下面还有子节点,那么把这个子节点继续赋值给workInProgress,然后开始下一个
performUnitOfWork循环 - 如果没有子节点,表示当前Fiber已经处理完成进入
completeUnitOfWork逻辑
如果
function performUnitOfWork(unitOfWork) {
//获取新的fiber对应的老fiber
const current = unitOfWork.alternate;
//完成当前fiber的子fiber链表构建后
const next = beginWork(current, unitOfWork);
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next === null) {
//如果没有子节点表示当前的fiber已经完成了
completeUnitOfWork(unitOfWork);
} else {
//如果有子节点,就让子节点成为下一个工作单元
workInProgress = next;
}
}
beginWork
目标是根据新虚拟DOM构建新的fiber子链表 child/return
beginWork的最终返回是当前节点经过处理后得到的可能得儿子,即实现了unitOfWork.child = xxx,这个xxx必然是一个Fiber或者null
这里通过不同的tag类型,有不同的处理逻辑,但最终都要协调子节点
- 如果是HostRoot
- 把当前Fiber上的updateQueue中pending的update整合起来,其实就是做了个merge,形成一个最终的状态放在memoizedState上
- 取出上面state中的element做为child来做协调,即DOM-DIFF
- 最后返回child给外层的
performUnitOfWork,来处理它的子元素
- 如果是HostComponent 即原生元素
- 查看pendingProps中的children是不是纯文本,如果是的话就没有再下层的儿子了
- 有儿子的话,做DOM-DIFF
- 如果是IndeterminateComponent即函数组件或类组件,通过执行函数,就可以得到它的children,然后做子节点的协调
export function beginWork(current, workInProgress) {
switch (workInProgress.tag) {
case IndeterminateComponent:
return mountIndeterminateComponent(current, workInProgress, workInProgress.type);
case HostRoot:
return updateHostRoot(current, workInProgress);
case HostComponent:
return updateHostComponent(current, workInProgress);
case HostText:
return null;
default:
return null;
}
}
function updateHostRoot(current, workInProgress) {
//需要知道它的子虚拟DOM,知道它的儿子的虚拟DOM信息
processUpdateQueue(workInProgress); // 最终目的是把update的payload信息放到memoizedState中,即 workInProgress.memoizedState={ element }
const nextState = workInProgress.memoizedState;
const nextChildren = nextState.element;
//协调子节点 DOM-DIFF算法
reconcileChildren(current, workInProgress, nextChildren);
return workInProgress.child; //{tag:5,type:'h1'}
}
function updateHostComponent(current, workInProgress) {
const { type } = workInProgress;
const nextProps = workInProgress.pendingProps;
let nextChildren = nextProps.children;
//判断当前虚拟DOM它的儿子是不是一个文本独生子
const isDirectTextChild = shouldSetTextContent(type, nextProps);
if (isDirectTextChild) {
nextChildren = null;
}
reconcileChildren(current, workInProgress, nextChildren);
return workInProgress.child;
}
协调子节点
分两种情况,reconcileChildFibers和mountChildFibers逻辑其实是一样的,只是是否跟踪副作用的区别
- 有老Fiber,比如RootNodeFiber必然存在,或者更新节点,意味着老fiber里面可能就有旧的儿子们了,所以要做一次DOM-DIFF
- 无老Fiber,那么意味着这些传进来的
nextChildren都是新挂载的
function reconcileChildren(current, workInProgress, nextChildren) {
//如果此新fiber没有老fiber,说明此新fiber是新创建的
//如果此fiber没能对应的老fiber,说明此fiber是新创建的,如果这个父fiber是新的创建的,它的儿子们也肯定都是新创建的
if (current === null) {
workInProgress.child = mountChildFibers(workInProgress, null, nextChildren);
} else {
//如果说有老Fiber的话,做DOM-DIFF 拿老的子fiber链表和新的子虚拟DOM进行比较 ,进行最小化的更新
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child, // 老fiber下面的老child
nextChildren // 新child
);
}
}
completeUnitOfWork
会走到这里有两种情况
- 虚拟DOM的叶子节点,它没有children了
- 节点的所有子节点都已经complete了,就会开始完成它本身
- 维护局部变量
completedWork completeWork:创建真实节点- 查看当前completedWork是否有兄弟节点sibling
- 如果有,则把sibling赋给workInProgress,跳出循环重新进入
performUnitOfWork开始处理sibling - 如果没有,此时说明当前节点既没有儿子也没有兄弟了,即是父Fiber的最后一个节点。 把returnFiber赋给completedWork,开始complete父节点
- 如果有,则把sibling赋给workInProgress,跳出循环重新进入
function completeUnitOfWork(unitOfWork) {
let completedWork = unitOfWork;
do {
const current = completedWork.alternate;
const returnFiber = completedWork.return;
//执行此fiber 的完成工作,如果是原生组件的话就是创建真实的DOM节点
completeWork(current, completedWork);
//如果有弟弟,就构建弟弟对应的fiber子链表
const siblingFiber = completedWork.sibling;
if (siblingFiber !== null) {
workInProgress = siblingFiber;
return;
}
//如果没有弟弟,说明这当前完成的就是父fiber的最后一个节点
//也就是说一个父fiber,所有的子fiber全部完成了
completedWork = returnFiber;
workInProgress = completedWork;
} while (completedWork !== null);
}
completeWork
目的: 给每个节点创建/更新真实DOM节点,并且append或者insert到自己的父节点的真实DOM上,同时把各种属性都设置上去
几个函数
- bubbleProperties: 传入当前fiber节点,通过收集自己的child以及child的所有sibling,归纳出自身节点的
subtreeFlags属性,代表自己子的副作用。不论什么类型的Fiber节点都需要调用 - createInstance: 创建元素类型(h1/div)的真实DOM节点,同时把当前Fiber和props作为两个属性缓存在DOM节点上,这样做就可以随时从Fiber上找到DOM(stateNode),也可以从DOM上立刻找到Fiber(domNode[缓存key])
- appendAllChildren:传入当前的真实DOM节点和Fiber,把当前Fiber的child以及child的所有sibling的
stateNode添加到真实DOM上去。 中间有细节注意:child或者sibling可以是非原生元素或纯文本,即函数组件或类组件,此时就需要一直往下找,直到找到原生节点为止才算有效的child - finalizeInitialChildren:就是把所有放在虚拟DOM上的pendingProps,赋值给这个真实DOM,比如style, className等,如果碰到children属性,同时还是字符串或者数字的话,那么就会用
node.textContent = text来设置纯文本内容
export function completeWork(current, workInProgress) {
const newProps = workInProgress.pendingProps;
switch (workInProgress.tag) {
case HostRoot:
bubbleProperties(workInProgress);
break;
//如果完成的是原生节点的话
case HostComponent:
///现在只是在处理创建或者说挂载新节点的逻辑,后面此处分进行区分是初次挂载还是更新
//创建真实的DOM节点
const { type } = workInProgress;
const instance = createInstance(type, newProps, workInProgress);
//把自己所有的儿子都添加到自己的身上
appendAllChildren(instance, workInProgress);
workInProgress.stateNode = instance;
finalizeInitialChildren(instance, type, newProps);
bubbleProperties(workInProgress);
break;
case HostText:
//如果完成的fiber是文本节点,那就创建真实的文本节点
const newText = newProps;
//创建真实的DOM节点并传入stateNode
workInProgress.stateNode = createTextInstance(newText);
//向上冒泡属性
bubbleProperties(workInProgress);
break;
}
}
commitWork
整个渲染过程主要分为两部分:
- 协调,即上面的
workLoop工作循环,简单讲就是把老的Fiber更新成新的Fiber,而新的Fiber上都已经准备好了要更新的真实DOM节点。因为有Fiber链表结构的存在,整个过程是可以打断的 - commit,把上一步总结好的Fiber一次性更新到UI上,这个步骤不可打断。通过之前的分析得到,当前节点和自己的子树中有没有需要更新的操作(flags/subtreeFlags)
function commitRoot(root) {
const { finishedWork } = root;
//判断子树有没有副作用
const subtreeHasEffects =
(finishedWork.subtreeFlags & MutationMask) !== NoFlags;
const rootHasEffect = (finishedWork.flags & MutationMask) !== NoFlags;
//如果自己的副作用或者子节点有副作用就进行提交DOM操作
if (subtreeHasEffects || rootHasEffect) {
commitMutationEffectsOnFiber(finishedWork, root);
}
//等DOM变更后,就可以把让root的current指向新的fiber树
root.current = finishedWork;
}
commitMutationEffectsOnFiber: 作用是按深度遍历的顺序,处理每个节点需要的DOM操作(插入/删除/更新)
- 看当前节点有没有subtreeFlags,有的话开始处理child,child处理完处理剩下可能得sibling。如果没有的话就直接跳过了,说明这个节点的子都不需要更新
- 当自己的child都处理完之后,开始处理自身,即根据自身flags把自身的DOM节点在最近的原生元素节点下插入更新删除(其中插入不一定是append,可能需要查找其最近的sibling来插入到它的前面)
DOM-DIFF
DOM-DIFF是beginWork中的一步,用来协调当前Fiber的子节点的更新状态
- 如果新儿子是个对象,且不是数组,即singleElement
- 调用
reconcileSingleElement方法,最终根据传入的child,返回一个新的Fiber。TODO - 把上一步得到的新child Fiber传入
placeSingleChild,本质就是打标,即flags属性,确定这个Fiber是要插入还是更新之类的操作 - 这里的shouldTrackSideEffects表示:是否需要去跟踪副作用,简单理解就是当前这个newFiber的父亲是不是本身就存在
- True ->
reconcileChildFibers, 比如挂载根节点下第一个元素时,RootNodeFiber是存在的,所以走的是reconcileChildFibers,需要单独去跟踪这个Fiber的插入/更新/删除副作用 - False ->
mountChildFibers,比如初次挂载时,除了最顶层节点外,里面的所有元素要挂载时,return(parent)其实也是刚刚创建的,它的alternate(老的Fiber节点)其实是不存在的。所以走的是mountChildFibers,即最终的挂载是跟随向上追溯第一个shouldTrackSideEffects为true的节点一起,而不需要单独去处理它的副作用了
- True ->
- 调用
function reconcileChildFibers(returnFiber, currentFirstFiber, newChild) {
if (typeof newChild === "object" && newChild !== null) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
return placeSingleChild(reconcileSingleElement(returnFiber, currentFirstFiber, newChild));
default:
break;
}
}
//newChild [hello文本节点,span虚拟DOM元素]
if (isArray(newChild)) {
return reconcileChildrenArray(returnFiber, currentFirstFiber, newChild);
}
return null;
}
function reconcileSingleElement(returnFiber, currentFirstFiber, element) {
//因为我们现实的初次挂载,老节点currentFirstFiber肯定是没有的,所以可以直接根据虚拟DOM创建新的Fiber节点
const created = createFiberFromElement(element);
created.return = returnFiber;
return created;
}
function placeSingleChild(newFiber) {
//说明要添加副作用
if (shouldTrackSideEffects) {
//要在最后的提交阶段插入此节点 React渲染分成渲染(创建Fiber树)和提交(更新真实DOM)二个阶段
newFiber.flags |= Placement;
}
return newFiber;
}
- 如果newChild是数组,// 目前还没有DIFF TODO
- 把数组中的每一个元素从虚拟DOM转成Fiber节点
- 把这个数组一字排开,组成一个链表,后一个是前一个的sibling,最终返回第一个节点,这样workInProgress得到的child就不会是一个数组,而是一个链表
function reconcileChildrenArray(returnFiber, currentFirstFiber, newChildren) {
let resultingFirstChild = null; //返回的第一个新儿子
let previousNewFiber = null; //上一个的一个新的fiber
let newIdx = 0;
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = createChild(returnFiber, newChildren[newIdx]);
if (newFiber === null) continue;
placeChild(newFiber, newIdx);
//如果previousNewFiber为null,说明这是第一个fiber
if (previousNewFiber === null) {
resultingFirstChild = newFiber; //这个newFiber就是大儿子
} else {
//否则说明不是大儿子,就把这个newFiber添加上一个子节点后面
previousNewFiber.sibling = newFiber;
}
//让newFiber成为最后一个或者说上一个子fiber
previousNewFiber = newFiber;
}
return resultingFirstChild;
}
对单节点的处理
单节点就是一个Fiber下面要创建的child对应的虚拟DOM是一个object,且不是一个数组
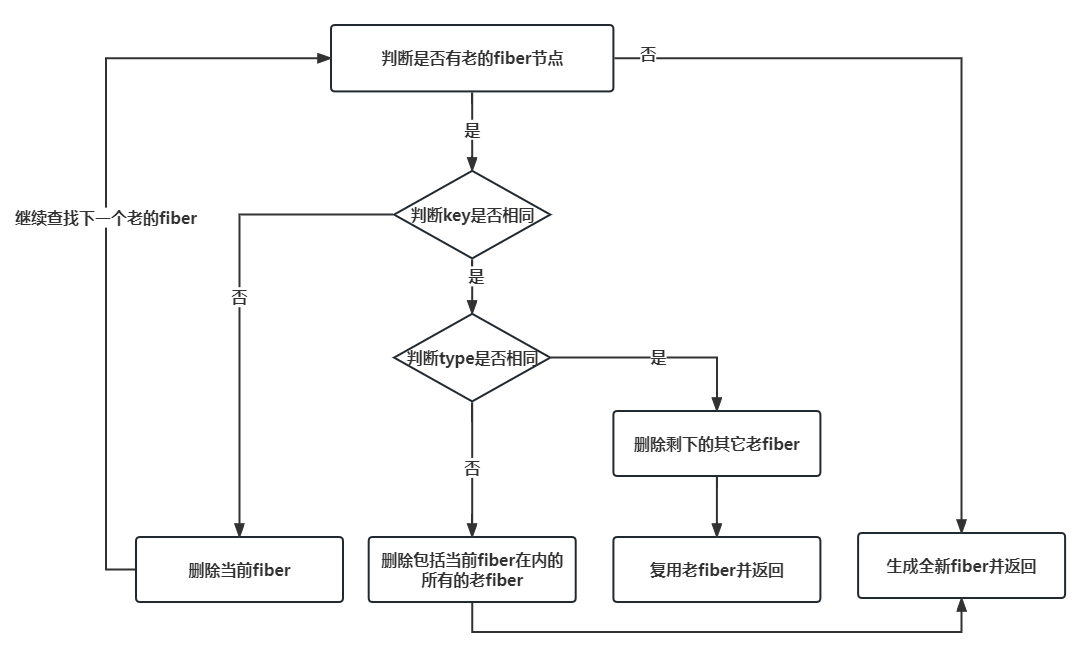
key相同,类型相同
如果只是属性不同,会在completeWork阶段对比属性差异进行更新
同时为了防止这个节点在上次渲染时是一个数组中的元素,虽然节点可以复用,但这个节点是上一个渲染数组的某一个元素,所以必须把它可能存在的后续节点都删除,这一步在所有可复用节点的情况下都要操作,如下情况,container下面的child是个数组,同时里面有个key=B是可以复用的,所以当发现新渲染的是一个单节点时,就要把之前的A和C都删除
return number === 0 ? (
<ul key="container" onClick={() => setNumber(number + 1)}>
<li key="A" id="A">A</li>
<li key="B" id="B">
B
</li>
<li key="C" id="C">C</li>
</ul>
) : (
<ul key="container" onClick={() => setNumber(number + 1)}>
<li key="B" id="B2">
B2
</li>
</ul>
);
Key相同,类型不同
- 删除包括当前fiber在内的已经可能存在的sibling
- 根据新的虚拟dom节点创建一个新的Fiber,并把它的return设为原先的父节点
key不同
把这个Fiber的父也就是它的return上加上一个
deletions属性(数组),表示这个child需要被删除用这个要被删除的child的可能存在的sibling去对比Key,如果Key相同(复用),走上面两条分支,这里return
根据新的虚拟dom节点创建一个新的Fiber,并把它的return设为原先的父节点
在commit阶段,对每个有
deletions的节点,进行遍历删除- 这里的删除,必须从要被删除的节点向上找到最近的Host节点(非function/class组件),然后再删除
- 在删除前,还要再遍历下要被删除的节点下面的儿子,如果有儿子则遍历先删除儿子。这样做的目的是让所有被删除的组件都能走到它的unmount生命周期函数
多节点DIff
就是不论上次渲染时单节点还是数组,当前这次新的虚拟DOM是数组
多节点DOM DIFF 的三个规则
- 只对同级元素进行比较,不同层级不对比
- 不同的类型对应不同的元素(不能复用)
- 可以通过 key 来标识同一个节点
主要有三轮遍历可能
第 1 轮遍历
- 如果 key 不同则直接结束本轮循环
- newChildren 或 oldFiber 遍历完,结束本轮循环
- key 相同而 type 不同,标记老的 oldFiber 为删除,继续循环
- key 相同而 type 也相同,则可以复用老节 oldFiber 节点,继续循环
第 2 轮遍历
- newChildren 遍历完而 oldFiber 还有,遍历剩下所有的 oldFiber 标记为删除,DIFF 结束
- oldFiber 遍历完了,而 newChildren 还有,将剩下的 newChildren 标记为插入,DIFF 结束
- newChildren 和 oldFiber 都同时遍历完成,diff 结束
- newChildren 和 oldFiber 都没有完成,则进行
节点移动的逻辑
第 3 轮遍历
- 处理节点移动的情况
节点移动
前两轮可以总结为
前后两个数组,从头部开始一一对比,只要key是相同的,就继续对比下一个,直到某一方没有元素了或者key对不上了
- 如果老的先结束,那么后面就直接添加剩下的新虚拟DOM节点
- 如果新的先结束,那么就把剩下的老Fiber都标记为删除
- key对不上了开始移动节点逻辑
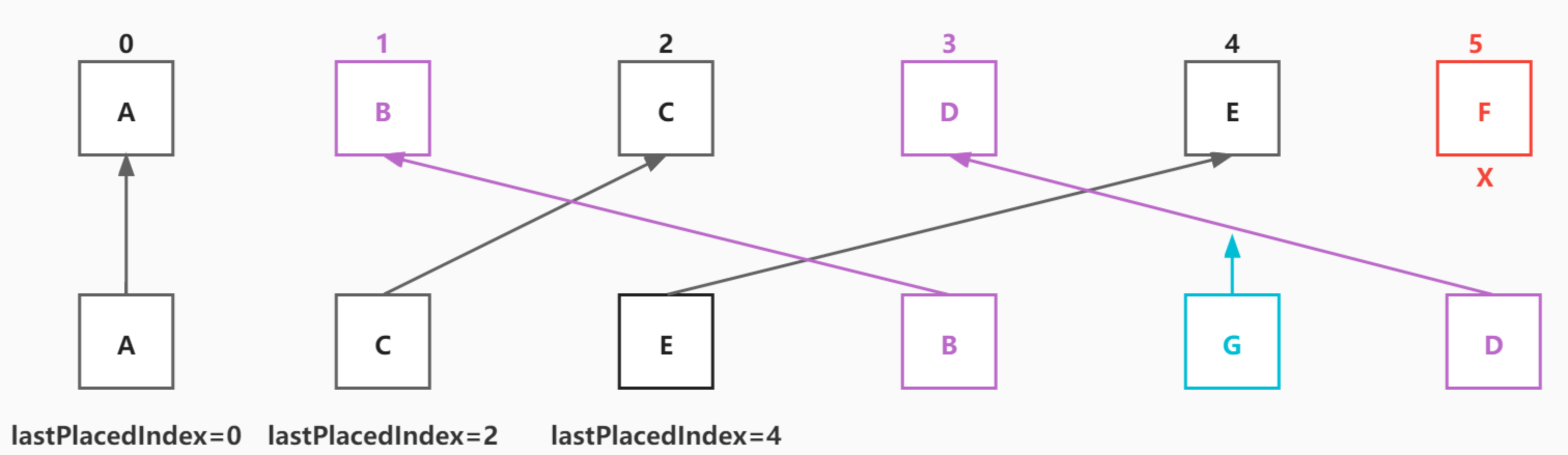
移动节点也是一个循环,从第一个对不上key的位置开始,从上图看就是从数组的第1位开始
- 把B到F这些老的fiber,用k-v的形式添加到一个map中,k就是key,v就是fiber
- 声明一个lastPlacedIndex,值为0,即最后能对上key的数组位置
- 从C开始循环新的虚拟DOM数组,发现C和E都在这个map中能找到相同key的老fiber节点,就通过老的fiber节点创建一个新的fiber节点,然后成为A的sibling。此时lastPlacedIndex指向4,即最后一个排列好的可复用的老fiber节点在老数组中的位置
- 循环到B,发现能找到可复用的老fiber,但是它在老数组的index是1,小于lastPlacedIndex4,这种情况就无法直接把B放在E后面(ACE可以直接放因为在DOM结构里面他们本来就是顺序的,只需要把不需要的DOM删除,就能保持这个结构),需要进行节点移动,此时B节点就要打上一个Placement的flag标志它需要移动(React中没有移动操作flag,移动就是插入,在插入时用
dom.insertBefore(child,beforeChild)来实现DOM节点的移动) - 循环到G,在map中找不到老fiber,直接创建一个新的fiber并成为B的sibling
- D同B,以上每次找到可复用的老fiber都会同时把它从map中删除,当遍历完新数组后,map中剩下的元素就是要删除的节点,这里就是F
从DOM-DIFF到页面更新
以上所有DOM-DIFF的操作,最终的成果就是把所有的更新体现在fiber链表中
- 新增的节点,fiber打上Placement的flag
- 删除的节点,在被删除节点的父fiber上会添加上deletions的数组,并打上ChildDeletion的flag
- 移动的节点,和新增一样
在completeWork阶段
- 会对新fiber的props和老fiber的memorizedProps做一个diff,如果发现有变化,就会在fiber上打上Update的flag。同时把需要更新的内容放在fiber的updateQueue属性上
在commitWork阶段
- 得到当前fiber,根据flag做相应操作,对真实DOM进行增删改
合成事件
所谓合成事件肯定是要相对于原生事件,那么它做了些什么呢?
- 把所有事件都由root进行代理,相当于所有的event都是注册在顶部元素的
- 整个
addEventListener行为只会发生一次(初次挂载时),接下来所有的事件注册都不需要额外绑定事件,减少内存开销 - 对浏览器的兼容,比如
stopPropagation、preventDefault在IE中的语法是不同的,React帮助抹平了这个差异
这个过程主要分以下几步
初次挂载时绑定所有事件
React在初次挂载时会收集所有可能的事件类型,最终集合到一个Set中,以click为例,这个过程会在div#root上注册两个事件绑定(此时注意即便是我们的代码里没有任何click相关的事件,这个过程也必须的),分别是
- click事件的捕获
- click事件的冒泡
绑定上去的事件回调,是一个创建出来的listenerWrap,这个wrap函数通过bind绑定了listener回调需要的三个参数
- EventName: 事件名,如
click - eventSystemFlags:表示冒泡或捕获的标志
- targetContainer:即div#root
// react-dom/src/client/ReactDOMRoot.js
export function createRoot(container) {
const root = createContainer(container);
listenToAllSupportedEvents(container); // 初始化时开始监听事件
return new ReactDOMRoot(root);
}
// react-dom-bindings/src/events/DOMPluginEventSystem.js
export function listenToAllSupportedEvents(rootContainerElement) {
...
// 遍历所有的原生的事件比如click,进行监听
allNativeEvents.forEach((domEventName) => {
listenToNativeEvent(domEventName, true, rootContainerElement); // 监听捕获
listenToNativeEvent(domEventName, false, rootContainerElement); // 监听冒泡
});
}
function addTrappedEventListener(
targetContainer,
domEventName,
eventSystemFlags,
isCapturePhaseListener
) {
// 创建一个listenerWrap,随后直接做addEventListener绑定
const listener = createEventListenerWrapperWithPriority(
targetContainer,
domEventName,
eventSystemFlags
);
if (isCapturePhaseListener) {
addEventCaptureListener(targetContainer, domEventName, listener); // addEventListener
} else {
addEventBubbleListener(targetContainer, domEventName, listener);
}
}
经过初始化之后,div#root上就有关于click的两个事件监听了。
事件触发
当在页面触发实际点击后,就会触发上面注册的listenerWrap,除了上面已经绑定的三个参数,最后一个参数是事件的原生事件对象nativeEvent
通过这个原生事件对象,可以拿到那个真实触发事件的DOM元素,即实际点击的button/div/span,然后通过internalInstanceKey在DOM上得到绑定在其上的Fiber对象。为什么要取Fiber节点?因为我们目前能获取到的只是某个DOM元素被点击了,不论这个元素是否有绑定onClick事件,我们都要考虑这个元素的父元素一直到root是否还有绑定onClick事件,这里就可以利用fiber.return一路向上遍历。
这个过程可以简单概括为(这个过程会执行两遍,第一次是捕获,第二次是冒泡,这里以捕获为例):
- dispatchEvent:拿到原生事件对象、目标对应的Fiber
- extractEvents:
- 通过事件类型,创建一个新的合成事件对象,比如click事件就是
SyntheticMouseEvent,在创建时nativeEvent是它的一个属性,同时会按需把一些nativeEvent的属性复制到合成事件上,比如click事件的clientX和clientY - 收集listener,从当前target DOM开始利用它对应的Fiber.return一路向上遍历,找到一路上有包含
onClickCapture的节点,把这些回调都放到一个listener数组中去,此时注意这个数组的顺序是先是子的事件回调,然后再是一路父级的回调
- 通过事件类型,创建一个新的合成事件对象,比如click事件就是
- processDispatchQueue:根据上面的listeners逐个执行
- 如果是捕获阶段:listeners数组从后往前执行,即从父到子的顺序
- 如果是冒泡阶段:listeners数组从后往前执行,即从子到父的顺序
- 中间会覆盖原生的
stopPropagation和preventDefault,模拟原生那样,如果调用就不会执行接下来的回调
// 这个就是上面listenerWrap的实际内容
export function dispatchEvent(
domEventName,
eventSystemFlags,
targetContainer,
nativeEvent
) {
//获取事件源,它是一个真实DOM
const nativeEventTarget = getEventTarget(nativeEvent);
const targetInst = getClosestInstanceFromNode(nativeEventTarget); // domNode[internalInstanceKey]
dispatchEventForPluginEventSystem(
domEventName, //click
eventSystemFlags, //0 4
nativeEvent, //原生事件
targetInst, //此真实DOM对应的fiber
targetContainer //目标容器
);
}
/**
* 把要执行回调函数添加到dispatchQueue中
* @param {*} dispatchQueue 派发队列,里面放置我们的监听函数
* @param {*} domEventName DOM事件名 click
* @param {*} targetInst 目标fiber
* @param {*} nativeEvent 原生事件
* @param {*} nativeEventTarget 原生事件源
* @param {*} eventSystemFlags 事件系统标题 0 表示冒泡 4表示捕获
* @param {*} targetContainer 目标容器 div#root
*/
function extractEvents(
dispatchQueue,
domEventName,
targetInst,
nativeEvent,
nativeEventTarget, //click => onClick
eventSystemFlags,
targetContainer
) {
const reactName = topLevelEventsToReactNames.get(domEventName); //click => onClick
let SyntheticEventCtor; //合成事件的构建函数
switch (domEventName) {
case "click":
SyntheticEventCtor = SyntheticMouseEvent;
break;
default:
break;
}
const isCapturePhase = (eventSystemFlags & IS_CAPTURE_PHASE) !== 0; //是否是捕获阶段
const listeners = accumulateSinglePhaseListeners( // 收集链路上所有事件回调
targetInst,
reactName,
nativeEvent.type,
isCapturePhase
);
//如果有要执行的监听函数的话[onClickCapture,onClickCapture]=[ChildCapture,ParentCapture]
if (listeners.length > 0) {
const event = new SyntheticEventCtor(
reactName,
domEventName,
null,
nativeEvent,
nativeEventTarget
);
dispatchQueue.push({
event, //合成事件实例
listeners, //监听函数数组
});
}
}
Hooks
useReducer
React其实维护了两套useReducer的逻辑,分别对应mount和update
当函数组件进入beginWork逻辑时,会调用renderWithHooks根据Hooks进行渲染
// 进入beginWork
// 几个维护在全局的变量
const { ReactCurrentDispatcher } = ReactSharedInternals; // 整个React全局维护一个ReactCurrentDispatcher
let currentlyRenderingFiber = null;
/**
* 一个hook有三个属性
* memoizedState: 这个hook上次保留的state值,或者初始值,
queue: 这个hook上存在的待更新的update队列
next: 注册在这个hook后面的下一个hook,
同时当前Fiber的memoizedState就是指向此Fiber下的第一个hook
*/
let workInProgressHook = null; // 用来指代Hooks链表中的最后一位,用于在mount阶段组建链表
let currentHook = null;
const HooksDispatcherOnMount = {
useReducer: mountReducer,
};
const HooksDispatcherOnUpdate = {
useReducer: updateReducer,
};
/**
* 渲染函数组件
* @param {*} current 老fiber
* @param {*} workInProgress 新fiber
* @param {*} Component 组件定义
* @param {*} props 组件属性
* @returns 虚拟DOM或者说React元素
*/
function renderWithHooks(current, workInProgress, Component, props) {
if (挂载阶段) {
ReactCurrentDispatcher = HooksDispatcherOnMount
} else {
ReactCurrentDispatcher = HooksDispatcherOnUpdate
}
const children = Component(props); // 执行函数得到children
return children;
}
比如我把组件写成这样
function FunctionComponent() {
const [number, setNumber] = React.useReducer(counter, 0);
return (
<button
onClick={() => {
setNumber({ type: "add", payload: 1 });
setNumber({ type: "add", payload: 2 });
setNumber({ type: "add", payload: 3 });
}}
>
{number}
</button>
);
}
当在执行const children = Component(props)这句话时,里面就会调用到React.useReducer,而此时这个useReducer就是在此之前去赋值的,每次调用一个useXXX都会生成一个新的hook对象,它的数据结构是这样
const hook = {
memoizedState: null,
queue: null,
next: null,
};
- memoizedState:hook的状态 上面例子里初始值就是0
- queue:存放仅针对本hook的更新队列,它的值指向所有更新(update)中的最后一个,指向最后一个的好处是,可以非常方便得得到整个列表的头尾元素
- next:指向下一个hook,一个函数里可以会有多个hook,它们会组成一个单向链表
mountReducer
即useReducer执行时的函数体。主要工作是新建一个hook同时把它添加到Hooks链表中,最后返回两个值,一个是hook的初始值,另一个是绑定了当前fiber和更新队列的dispatch方法。注意这里reducer参数并不会被用到,只需要用到初始值
function mountReducer(reducer, initialArg) {
const hook = 创建一个新的空hook并返回,同时把这个hook放在hooks链表的尾部;
hook.memoizedState = initialArg; // 给新的hook添加初始值
hook.queue = {
pending: null,
}; // 给新的hook添加一个空的更新队列
return [hook.memoizedState, dispatchReducerAction];
}
dispatchReducerAction
即触发action的函数。目标是每一次触发都新建一个update对象,然后把它入队到当前全局的queue里面去
其中fiber和queue是在mount时就绑定的(bind方法),运行时只会传入action
全局维护一个queue数组和一个queueIndex
如上面的例子,连续执行三次setNumber,即调用了三次dispatchReducerAction。会按照三个一组的形式存储
执行结束的结果就是
全局 concurrentQueue = [fiber1,queue1,update1,fiber2,queue2,update2,fiber3,queue3,update3]
其中queue是对当个hook来说是共享的,即这里的queue1,queue2,queue3是同一个对象(这里的fiber1/2/3也是同一个对象),假设后面还触发了一个useState的setState,那么queue4就是不同的队列queue了
concurrentQueue的使命就是在一个渲染周期里收集所有的更新动作
const concurrentQueue = [];
let concurrentQueuesIndex = 0;
/**
* 执行派发动作的方法,它要更新状态,并且让界面重新更新
* @param {*} fiber function对应的fiber
* @param {*} queue hook对应的更新队列
* @param {*} action 派发的动作
*/
function dispatchReducerAction(fiber, queue, action) {
// 更新对象
const update = {
action, //{ type: 'add', payload: 1 } 派发的动作
next: null, //指向下一个更新对象
};
//把当前的最新的更添的添加更新队列中
enqueueConcurrentHookUpdate(fiber, queue, update);
通知React从root开始更新
}
function enqueueConcurrentHookUpdate(fiber, queue, update) {
concurrentQueue[concurrentQueuesIndex++] = fiber; // 函数组件对应的fiber
concurrentQueue[concurrentQueuesIndex++] = queue; // 要更新的hook对应的更新队列
concurrentQueue[concurrentQueuesIndex++] = update; // 更新对象
}
虽然执行了三次,但是最后一步通知React从root开始更新并不会迫使React更新三次,而是保证在单位时间(requestIdleCall)中只会执行一次
updateReducer
即在非挂载阶段执行的useReducer的函数体。
经过上面的dispatchReducerAction操作,最后会通知React从root开始更新。此时再次执行React.useReducer(counter, 0)时(此时还是beginWork阶段),就是需要把之前触发的action累计计算出新的state来渲染
在beginWork阶段前会先做一步,把刚才存储的concurrentQueue拿出来组建更新队列,这步会把concurrentQueue按三位一组取出,
最终结果就是把之前的空queue({ pending: null })变成了{ pending: update3 -> update1 -> update2 -> ... }
function updateReducer(reducer) {
//获取新的hook
const hook = 从老fiber的memoizedState上得到的hooks链表上取出对应位置的hook,相当于做个拷贝
//获取新的hook的更新队列
const queue = hook.queue;
//获取老的hook
const current = 同位置的老hook;
//获取将要生效的更新队列
const pendingQueue = queue.pending;
//初始化一个新的状态,取值为老的状态
let newState = current.memoizedState;
if (pendingQueue !== null) { // 代表dispatchReducerAction被触发过,更新队列有内容
queue.pending = null;
const firstUpdate = pendingQueue.next; // 从第一个更新开始
let update = firstUpdate;
// 遍历整个更新队列,把State做一个reducer汇总
do {
const action = update.action;
newState = reducer(newState, action);
update = update.next;
} while (update !== null && update !== firstUpdate);
}
hook.memoizedState = newState; // 把计算出来的新state返回给函数组件
return [hook.memoizedState, queue.dispatch];
}
最后hook.memoizedState就是把这次渲染内所有queue上累积的update汇总后的结果。 然后把结果渲染到函数组件中
useState
useState其实就是一个套壳的useReducer
我们在useState中内置了一个reducer,action可以接受方法或者值
function baseStateReducer(state, action) {
return typeof action === "function" ? action(state) : action;
}
moutState
和useReducer基本一样,主要步骤就是
- 新建一个hook,然后从老的fiber的memoizedState中找到对应的老hook,所以React强调了hooks的顺序必须前后一致,不然新老fiber的memoizedState就找不到对应的hook了
- 给hook加一个空的queue, 但结构和useReducer不同
// useReducer
hook.queue = {
pending: null,
};
// useState
const queue = {
pending: null,
dispatch: null,
lastRenderedReducer: baseStateReducer, //上一个reducer
lastRenderedState: initialState, //上一个state
};
- 最后生成这个dispatcher
function dispatchSetState(fiber, queue, action) {
const update = {
action,
hasEagerState: false, //是否有急切的更新
eagerState: null, //急切的更新状态
next: null,
};
//当你派发动作后,我立刻用上一次的状态和上一次的reducer计算新状态
const { lastRenderedReducer, lastRenderedState } = queue;
const eagerState = lastRenderedReducer(lastRenderedState, action);
update.hasEagerState = true;
update.eagerState = eagerState;
if (Object.is(eagerState, lastRenderedState)) {
// 针对对象state,如果只是在原对象上改了属性,然后setState,是不会立即触发更新的,只有新对象才会立即触发更新
return;
}
//下面是真正的入队更新,并调度更新逻辑
const root = enqueueConcurrentHookUpdate(fiber, queue, update);
scheduleUpdateOnFiber(root);
}
当时setState触发,会取出lastRenderedState和lastRenderedReducer,然后计算出最新的state,剩下逻辑和useReducer一样
updateState
直接复用updateReducer
function updateState() {
return updateReducer(baseStateReducer);
}
useEffect
开始前先明确下useEffect和useLayoutEffect的区别,以下是网络答案
useEffect和useLayoutEffect都是 React 中的 Hook,它们的作用都是在组件渲染后执行一些副作用操作。它们的区别在于执行的时间和方式。
useEffect会在渲染完成后异步执行,也就是说它不会阻塞渲染过程。它的回调函数会在浏览器绘制完成后调用,因此它适用于大多数情况下。而
useLayoutEffect会在渲染后同步执行,也就是说它会阻塞渲染过程。它的回调函数会在浏览器绘制之前调用,因此它适用于需要在浏览器绘制之前同步更新 DOM 的情况。
总结一下
- useEffect是异步的,它是在渲染完成之后下一个宏任务(requestIdleCallback)才执行的
- useLayoutEffect是同步的,什么意思呢? 比如React在commit中改变了真实DOM,
div.style.color='red',这句话执行了之后,仅仅是DOM被修改了,但此时浏览器还并没有渲染。此时我是可以通过DOM直接查询到将要渲染的结果的DOM的准确数据的,所以此时同步获取DOM是可以避免一些问题的,- 假设我需要获取DOM的top属性,如果是在useEffect中获取,那如果渲染的过程中发生scroll了,top值就变了,这种不确定性就可能带来计算错误。如果假设你是想要同步得更新DOM的话,就会被异步发生的DOM改变给打的措手不及
- 另外Chrome浏览器的debugger是不会阻塞渲染的,即把断点打在
div.style.color='red'这行代码之后,可以看到页面已经变化了,虽然主线程代码停止了。 这里可以使用alert()api来替代,当使用alert时,渲染会阻塞。用这个方法可以证明useLayoutEffect是在渲染之前执行的 - 基于上面我们知道useLayoutEffect是在渲染前同步执行的,所以它不能做太多耗时的操作,否则就会让页面变卡
有两个Fiber新的Tag(类同前面的Placement、ChildDeletion等)
Passive: 表示普通的Effect,即告诉调度器,在本次渲染结束后要触发一个异步的任务(requestIdleCallback)来执行useEffect里面的函数
Layout: 等同Update
同时还引入了一个Effect Tag的概念,用来区别effect的类型和需不需要执行
- HasEffect: 有这个flag才需要执行effect,否则就不需要执行(比如前后deps一样)
- Passive:表示会在UI绘制后执行,类似于宏任务,用于useEffect
- Layout:表示积极的,会在UI绘制前之前,类似于微任务
mountEffect
- 创建hook,这步和useState一样
- 对当前fiber打上一个
Passive的标签,表示这个fiber上有useEffect - 构建这个hook的memoizedState,这里和useState的结构不同,它里面主要包括
- tag: effect的标签(HasEffect + Passive)
- create: 就是useEffect里面的回调函数
- destroy:销毁方法,这个方法在mount时是不存在的,因为还没执行create
- deps:依赖数组
- next:当前Fiber的下一个effect
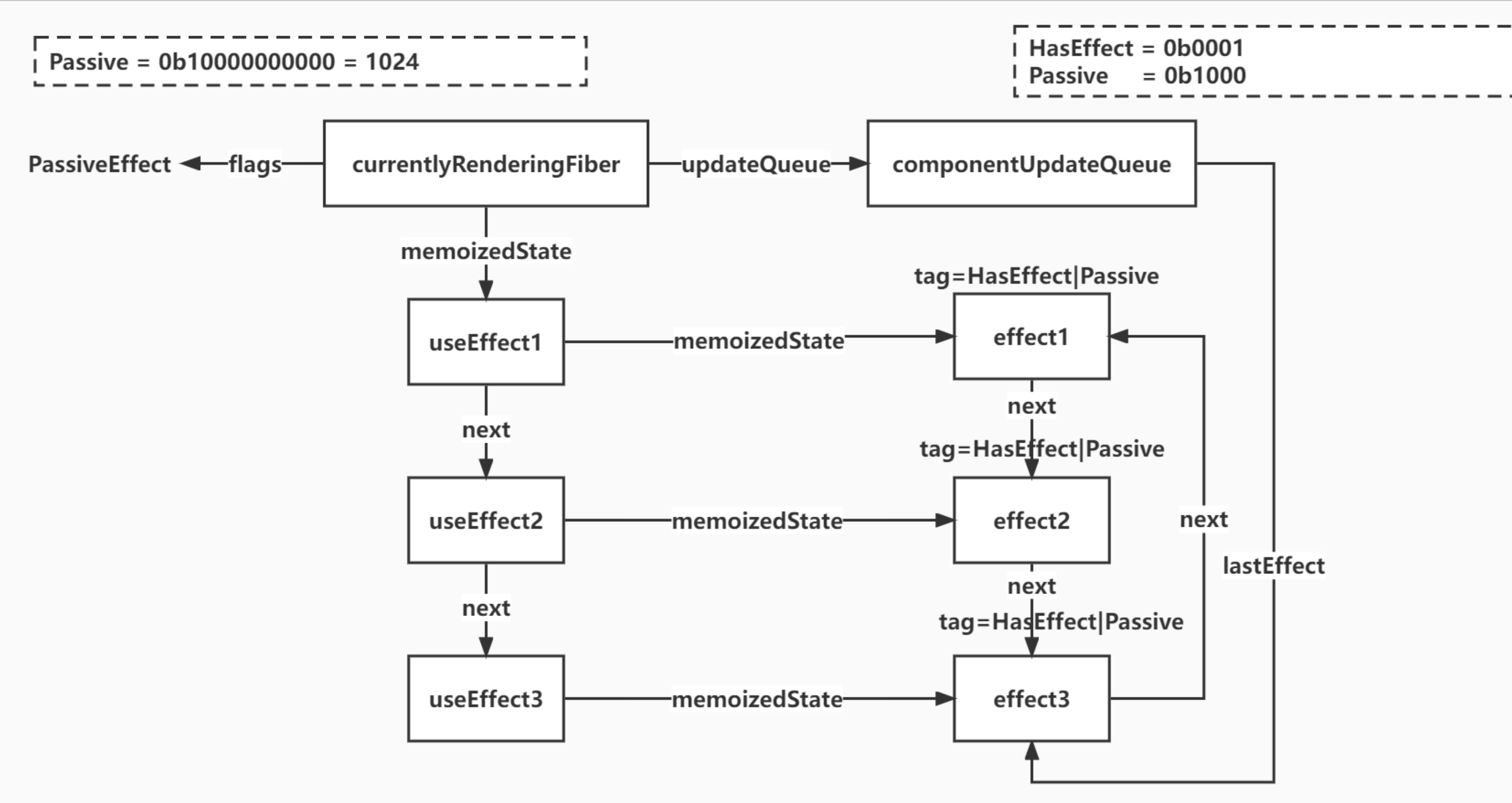
上图表示了:
- 当前fiber的memoizedState,其实就是它下面的hooks链表,里面可以包含useEffect和useState和其他各种hook
- 当存在useEffect时,fiber会被打上Passive的flag
- fiber的updateQueue,其实就是之前useState用来更新状态的updateQueue,里面有个新属性叫
lastEffect,指向最后一个effect,其实就是一个effect链表 - 每个useEffect hook的memoizedState都指向上面这个effect链表中的对应的那个effect
commitRoot
commitRoot是一次Workloop结束后,要commit到真实DOM的步骤,这里会先判断整个Fiber链上是否有包含Passive这个flag,如果有那就通过requestIdleCallback,schedule在渲染之后执行副作用,即flushPassiveEffect
function flushPassiveEffect() {
if (rootWithPendingPassiveEffects !== null) {
const root = rootWithPendingPassiveEffects;
//执行卸载副作用,destroy
commitPassiveUnmountEffects(root.current);
//执行挂载副作用 create
commitPassiveMountEffects(root, root.current);
}
}
在执行副作用时,会先执行umount副作用,后执行mount副作用
但是unmount函数是通过mount(create)函数return产生的, 所以当首次执行时,commitPassiveUnmountEffects不会产生任何作用。
在执行commitPassiveMountEffects时,做了以下的步骤
- 从根Fiber开始递归向下,找到如果就Passive的fiber就执行它的副作用,即Effect都是先执行子,后执行父
- 执行副作用时,取出fiber的updateQueue中的lastEffect,通过next拿到第一个effect,然后顺序执行链表,执行create函数得到destory函数,并赋值到effect对象上,供下次使用
- 在执行create前会判断effect的Tag是否有HasEffect这个tag,否则不执行。这里涉及到更新时deps的对比,如果相同就不会有这个tag。 首次渲染的话是必然会执行的
updateEffect
和mountEffect几乎一样,主要区别是有一个对比deps的过程,如果deps前后一样,那么就不会放HasEffect这个Tag,这样下次在commitRoot阶段遍历到这个effect的时候,就会跳过执行
useLayoutEffect
mount和update逻辑和useEffect几乎没差,只是用了不同flag而已。核心区别是在执行时机
useLayoutEffect的unmout函数会在commit函数组件时执行,此时连dom都没修改完,只是这个函数组件完成了修改(一轮workloop或者卸载)
mount(create)函数会在完成commit后,立刻执行,此时只是改变了dom,但浏览器还没渲染
简单描述Hooks原理
- Hooks是每个Fiber上的一个属性,放在memoizedState上
- Hooks是一个链表结构,后一个hook是前一个的next属性
- 一个hook上有三个属性
- memoizedState:上次渲染后的hook状态或者是初始值
- queue: 单个hook上的更新队列,比如在一个渲染周期中触发了N次setState操作,那就会放在这个queue上
- next: 下一个hook或null
- 每次页面update,都会通过老的hook来创建新的hook,所以hook在链表中的位置必须固定,不然创建出来的新hook就和老的无法对应
- 通过触发setState或Reducer操作,会触发重新渲染,在新的一轮渲染中,会做以下几件事
- 把每个hook中的queue里的update整合起来,最终合并计算出一个最终的state,这就是为什么连续触发
setState(num+1)最终结果只是加1的原因,在一次渲染计算中num始终是不变的 - 把上面的结果更新到hook的memoizedState上,这个结果也会作为state反馈到页面上
- 重置hook,即下次渲染又会从第一个hook开始做计算
- 把每个hook中的queue里的update整合起来,最终合并计算出一个最终的state,这就是为什么连续触发
任务队列
我们知道React Fiber的一大特性就是reconcile过程是可打断可恢复的。那么为什么需要打断呢?无非是两种情况
- 页面要进行布局绘制等操作了,因为js主线程与渲染进程互斥的关系,如果占着js主线程时间过长,肯定会影响渲染,使得页面卡顿(比如页面其实没有什么变化,但是用户在滚动页面或者resize页面,这个时候如果绘制不及时,页面就会感觉很卡)
- 有用户的操作,比如点击、输入等,如果用户的点击操作,在体感上得不到反馈,那肯定是糟糕的体验,所以用户操作的优先级肯定比普通渲染来得高,可以打断前面的reconcile过程
所以React为各种任务优先级设置了不同的任务过期时间
// Times out immediately 立刻过期 -1
var IMMEDIATE_PRIORITY_TIMEOUT = -1;
// Eventually times out 250毫秒
var USER_BLOCKING_PRIORITY_TIMEOUT = 250;
// 正常优先级的过期时间 5秒
var NORMAL_PRIORITY_TIMEOUT = 5000;
// 低优先级过期时间 10秒
var LOW_PRIORITY_TIMEOUT = 10000;
// Never times out 永远不过期
var IDLE_PRIORITY_TIMEOUT = maxSigned31BitInt;
每种任务在加入任务队列前都会设置自身的过期时间(当前时间 + 最大过期时间)。而进入队列就是一个加入最小堆的过程。通过最小堆,每次从堆顶拿到的都是过期时间最小的任务。利用最小堆,既节省空间(数组存放)又有良好的复杂度(O(1))
export function push(heap, node) {
const index = heap.length;
heap.push(node);
siftUp(heap, node, index);
}
export function peek(heap) {
return heap.length === 0 ? null : heap[0];
}
export function pop(heap) {
if (heap.length === 0) {
return null;
}
const first = heap[0];
const last = heap.pop();
if (last !== first) {
heap[0] = last;
siftDown(heap, last, 0);
}
return first;
}
function siftUp(heap, node, i) {
let index = i;
while (index > 0) {
const parentIndex = (index - 1) >>> 1;
const parent = heap[parentIndex];
if (compare(parent, node) > 0) {
heap[parentIndex] = node;
heap[index] = parent;
index = parentIndex;
} else {
return;
}
}
}
function siftDown(heap, node, i) {
let index = i;
const length = heap.length;
const halfLength = length >>> 1;
while (index < halfLength) {
const leftIndex = (index + 1) * 2 - 1;
const left = heap[leftIndex];
const rightIndex = leftIndex + 1;
const right = heap[rightIndex];
if (compare(left, node) < 0) {
if (rightIndex < length && compare(right, left) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
heap[index] = left;
heap[leftIndex] = node;
index = leftIndex;
}
} else if (rightIndex < length && compare(right, node) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
return;
}
}
}
function compare(a, b) {
const diff = a.sortIndex - b.sortIndex;
return diff !== 0 ? diff : a.id - b.id;
}
MessageChannel替代requestIdleCallback
因为目前 requestIdleCallback 目前只有Chrome支持,所以React就利用MessageChannel来模拟requestIdleCallback。而requestIdleCallback的核心目的就是把回调延迟到绘制操作之后执行
MessageChannel的回调执行是一个宏任务,下面示例代码中的onmessage回调执行,都是在主线程执行完后的下一个宏任务执行
var channel = new MessageChannel();
var port1 = channel.port1;
var port2 = channel.port2
port1.onmessage = function(event) {
// 我们在这里执行React的reconcile任务
console.log("port1收到来自port2的数据:" + event.data);
}
port2.onmessage = function(event) {
console.log("port2收到来自port1的数据:" + event.data);
}
port1.postMessage("发送给port2");
port2.postMessage("发送给port1");

其实MessageChannel和setTimeout差距不大,只是MessageChannel回调执行时机比定时器回调稍微更早一些,实际中用setTimeout效果其实应该也没差
React会在每一帧申请5ms的执行时间,所以上图的红色部分就是React申请的时间片,如果执行时间不到5ms且任务没有执行完,就会一直执行reconciler阶段的工作单元WorkUnit。否则的话就会放弃线程,让给浏览器做剩下的布局绘制等操作,确保页面没有卡顿
这里的5ms - 任务实际执行时间就可以理解为requestIdleCallback里的deadline.timeRemaining()
整个流程大致如下
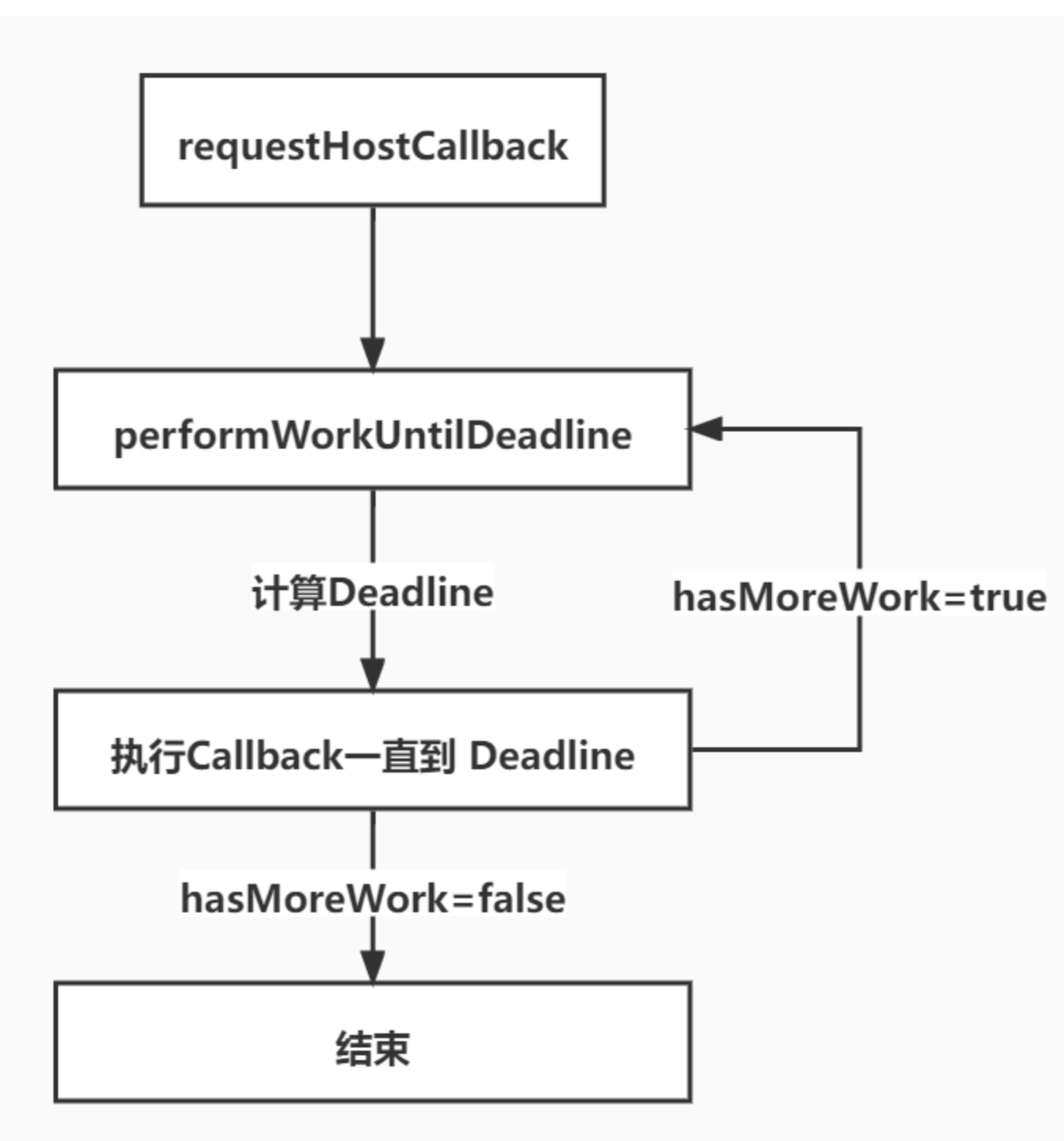
- 发起任务,比如在Workloop中发起更新或者需要执行副作用。
scheduleCallback(priority, callback),设置优先级和申请到时间片后执行的回调callback - 在
scheduleCallback中根据参数创建一个新的task,然后放进上面的最小堆队列中,最后调用requestHostCallback即用port2向port1发送一个空消息 - port1的onmessage回调即performWorkUntilDeadline会在下一帧被调用,然后开始执行一个工作单元
- 这个工作单元主要有以下步骤
- while循环从taskQueue里面取出当前优先级最高的任务,并计算到期时间
- 如果任务还未过期,但时间片到期了,则跳出while循环
- 如果时间片没有到期 或者 任务已经到期,取出第一步传入的回调开始执行,结束执行后,这个任务出队
- 当第二步跳出循环后,判断当前还有没有未完成的任务,如果有则返回
hasMoreWork为true,否则false
- 回到第三步的performWorkUntilDeadline,得到返回的hasMoreWork,如果为true,那就会再次用port2去发消息,告诉浏览器,下一帧再给我5ms,我还有工作要继续做。 然后下一帧又回到第四步从taskQueue里取任务执行。如果往复直到把taskQueue清空为止
Lane
- React中用lane(车道)模型来表示任务优先级
- 一共有31条优先级,数字越小优先级越高,某些车道的优先级相同

其中有几个主要的车道
export const TotalLanes = 31;
export const NoLanes = 0b0000000000000000000000000000000; // 表示没上车道
export const NoLane = 0b0000000000000000000000000000000;
export const SyncLane = 0b0000000000000000000000000000001; // 同步车道 优先级最高
export const InputContinuousHydrationLane = 0b0000000000000000000000000000010;
export const InputContinuousLane = 0b0000000000000000000000000000100; // 用户输入的车道
export const DefaultHydrationLane = 0b0000000000000000000000000001000;
export const DefaultLane = 0b0000000000000000000000000010000; // 默认车道
export const SelectiveHydrationLane = 0b0001000000000000000000000000000;
export const IdleHydrationLane = 0b0010000000000000000000000000000;
export const IdleLane = 0b0100000000000000000000000000000; // 空闲时的车道
export const OffscreenLane = 0b1000000000000000000000000000000; // 离屏的车道
const NonIdleLanes = 0b0001111111111111111111111111111; // 比空闲优先级高的车道集合
事件优先级
React会根据触发事件的类型来分配对应的优先级,比如click事件就是离散的输入事件优先级,拖拽就是连续事件优先级
同时各个事件优先级又和车道一一对应,比如离散输入事件优先级对应同步车道
//离散事件优先级 click onchange
export const DiscreteEventPriority = SyncLane;//1
//连续事件的优先级 mousemove
export const ContinuousEventPriority = InputContinuousLane;//4
//默认事件车道
export const DefaultEventPriority = DefaultLane;//16
//空闲事件优先级
export const IdleEventPriority = IdleLane;//
/**
* 获取事件优先级
* @param {*} domEventName 事件的名称 click
*/
export function getEventPriority(domEventName) {
switch (domEventName) {
case "click":
return DiscreteEventPriority;
case "drag":
return ContinuousEventPriority;
default:
return DefaultEventPriority;
}
}
调度优先级
Schedule Priority,即作用在任务队列上的优先级。 上面在任务队列提到每个优先级都有一个过期时间。
事件优先级最终都要映射到调度优先级上,比如离散事件优先级对应ImmediateSchedulerPriority,而ImmediateSchedulerPriority的过期时间是-1,即这个任务一旦进入队列就会立即被执行,不会等待
这里5种事件优先级可以直接映射到4种调度优先级上
switch (lanesToEventPriority(nextLanes)) {
case DiscreteEventPriority:
schedulerPriorityLevel = ImmediateSchedulerPriority;
break;
case ContinuousEventPriority:
schedulerPriorityLevel = UserBlockingSchedulerPriority;
break;
case DefaultEventPriority:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
case IdleEventPriority:
schedulerPriorityLevel = IdleSchedulerPriority;
break;
default:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
}
为什么要有三种优先级概念
因为车道总共有31条,非常得细分,而最终映射到的调度优先级只有4种优先级,所以要怎么把31条车道收敛到4种调度优先级上就是个问题。
解决策略就是,取出lane和事件优先级对比,如果lane的值更小,那么就对应这个优先级,否则和下一级的优先级对比
比如当前的lane值是8
- 和DiscreteEventPriority(1)比,它更大,不匹配
- 和ContinuousEventPriority(4)比,它更大,不匹配
- 和非空闲(非常大的数字)集合的优先级比,它小,所以它就是默认事件优先级
- 如果比空闲的优先级数字还大,那就是空闲优先级
export function lanesToEventPriority(lanes) {
//获取最高优先级的lane
let lane = getHighestPriorityLane(lanes);
//如果
if (!isHigherEventPriority(DiscreteEventPriority, lane)) {
return DiscreteEventPriority;//1
}
if (!isHigherEventPriority(ContinuousEventPriority, lane)) {
return ContinuousEventPriority;//4
}
if (includesNonIdleWork(lane)) {
return DefaultEventPriority;//16
}
return IdleEventPriority;//
}
渲染流程
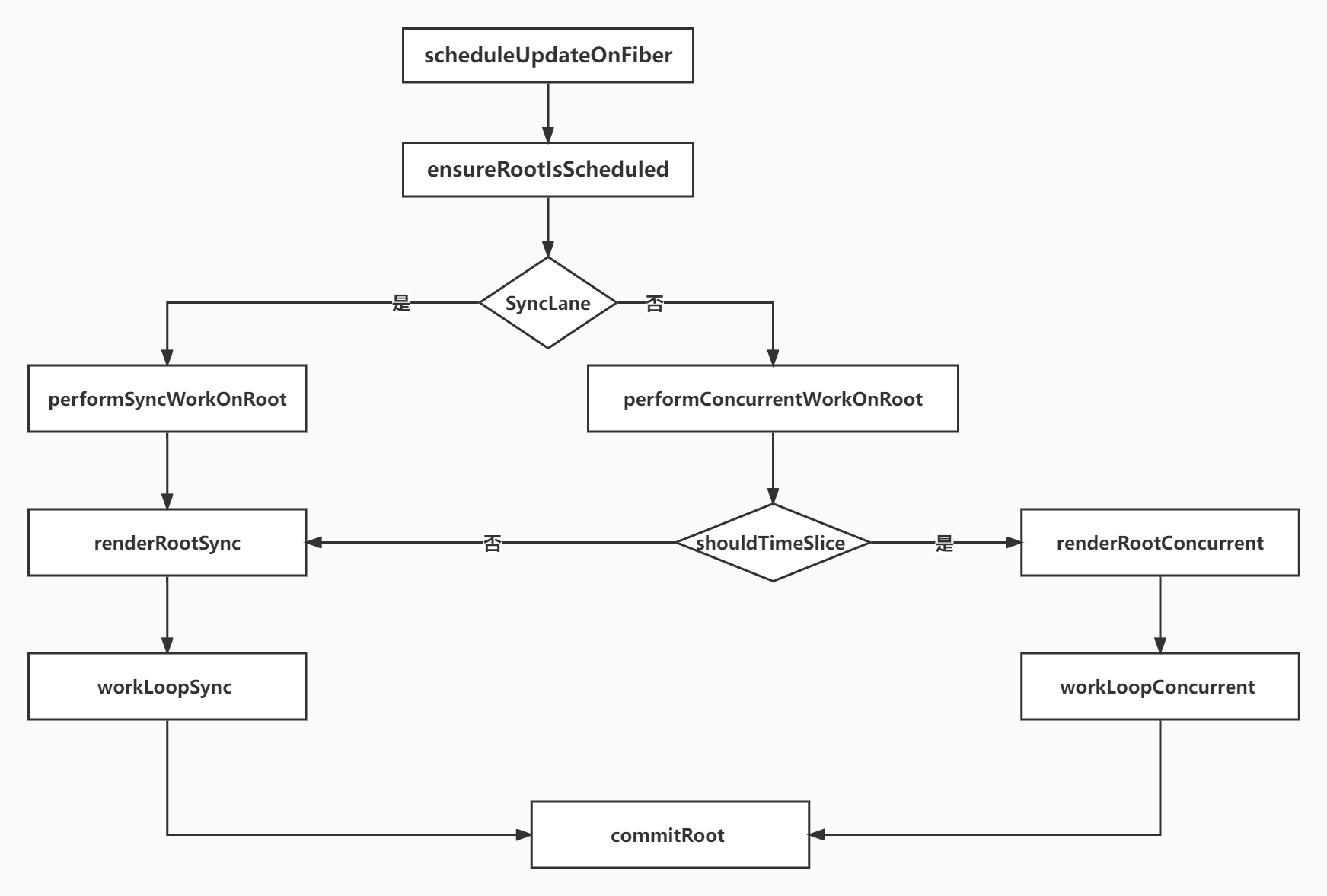
每次触发渲染,会判断当前的lane是什么,比如初次渲染就是DefaultLane
- 如果是SyncLane,那就不会schedule callback来申请下一个时间片去执行渲染,而是直接同步开始render
- 否则就要判断下是否需要申请时间片,申请时间片需要满足三个条件
- 当前车道没有阻塞性优先级的lane,比如
InputContinuousLane这样的用户输入 - 没有已经过期的车道
- 时间片没有过期,即当前总执行时长没有超过5ms
- 当前车道没有阻塞性优先级的lane,比如
- 满足时间分片的条件,就会执行
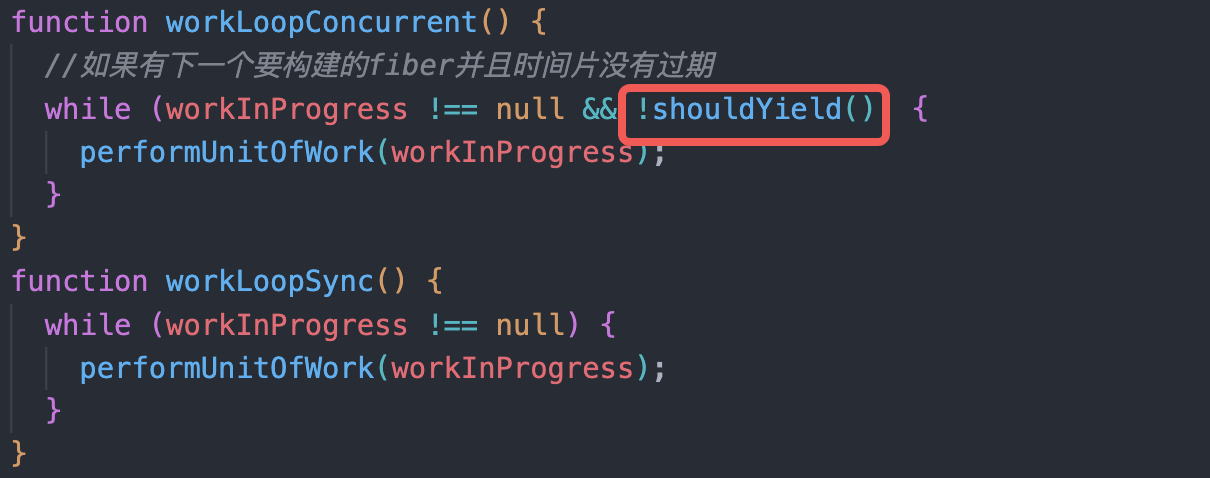
renderRootConcurrent - 这里同步和异步的区别如下图,就是同步没有一个时间片结束的判断。这样在同步的模式下,即使时间片结束也会坚持执行完
高优先级打断低优先级原理
在极端情况下,比如在useEffect中执行了一次setState之后,连续执行1000+次的用户点击,因为setState的优先级是默认,用户点击是离散更高。 假设setState和点击都是修改同一个state。 这样的结果就是必须等1000次点击执行完毕后才去执行这个setState,而setState传入的是函数,就会依据1000次点击之后的state来做计算,这样得到的结果就必然是错误的。
React做到高优先级打断低优先级的原理简单来说就是保留现场+恢复现场
保留现场
判断当前更新的优先级是否低于当前渲染的优先级
- 如果确实低优,那就会被跳过,然后把这个update克隆一份,放到hook的baseQueue这个属性上
- 如果不低,则会正常执行,但会查看下当前baseQueue上有没有内容,如果有的话要接在后面
经过这个过程,会得到一个从第一个被打断的低优更新开始到最后一个更新的Queue
恢复现场
每次更新完成后(commit结束),React都会再调用一次ensureRootIsScheduled,用来确保还有没有执行的update被执行
当高优更新都执行结束之后,终于轮到低优更新。判断上面保存的baseQueue是不是空
如果不为空,那就从baseQueue的队首开始执行,这里会把那些高优先级的Update囊括在一起重新一起计算一遍,以保证最终的结果是正确的
车道过期
root上根据渲染开始时间记录了31个车道的过期时间,逻辑是同步车道和用户输入车道过期时间为当前时间+250ms, 默认车道+5000ms
假设同时有setState和click被触发,那么setState这种默认车道就会被打断,优先把车道让给高优先级的Input车道
每次ensureRootIsScheduled都会查看root上的31个车道有没有已经过期的,如果有过期的话,就不会再去申请时间片,而是直接做同步渲染。
过期时间
综上,我们看到三个过期时间的概念
时间片过期时间:指每个时间片分配的时间,即5毫秒,超过这个时间就应该让出线程,等待下次时间片执行,但是这仅针对并发模式有效,如果是同步模式下不会申请时间片
任务过期时间:这个是指根据任务的优先级计算出来的过期时间, 等于任务入堆时间 + 优先级timeout,它的作用就是配合shouldYieldToHost判断当前从最小堆中取出的任务是否需要执行
如果任务没有过期且时间片到期,那就跳出工作循环,把线程让出,此时当前任务肯定是还没做的,那么这个任务就会被安排在下次申请时间片之后执行
如果任务到期或者时间片没有到期,说明任务过期已经不能等待了,或者时间片还有富余,此时就会继续执行任务,直到当前任务执行结束,再次进入循环判断
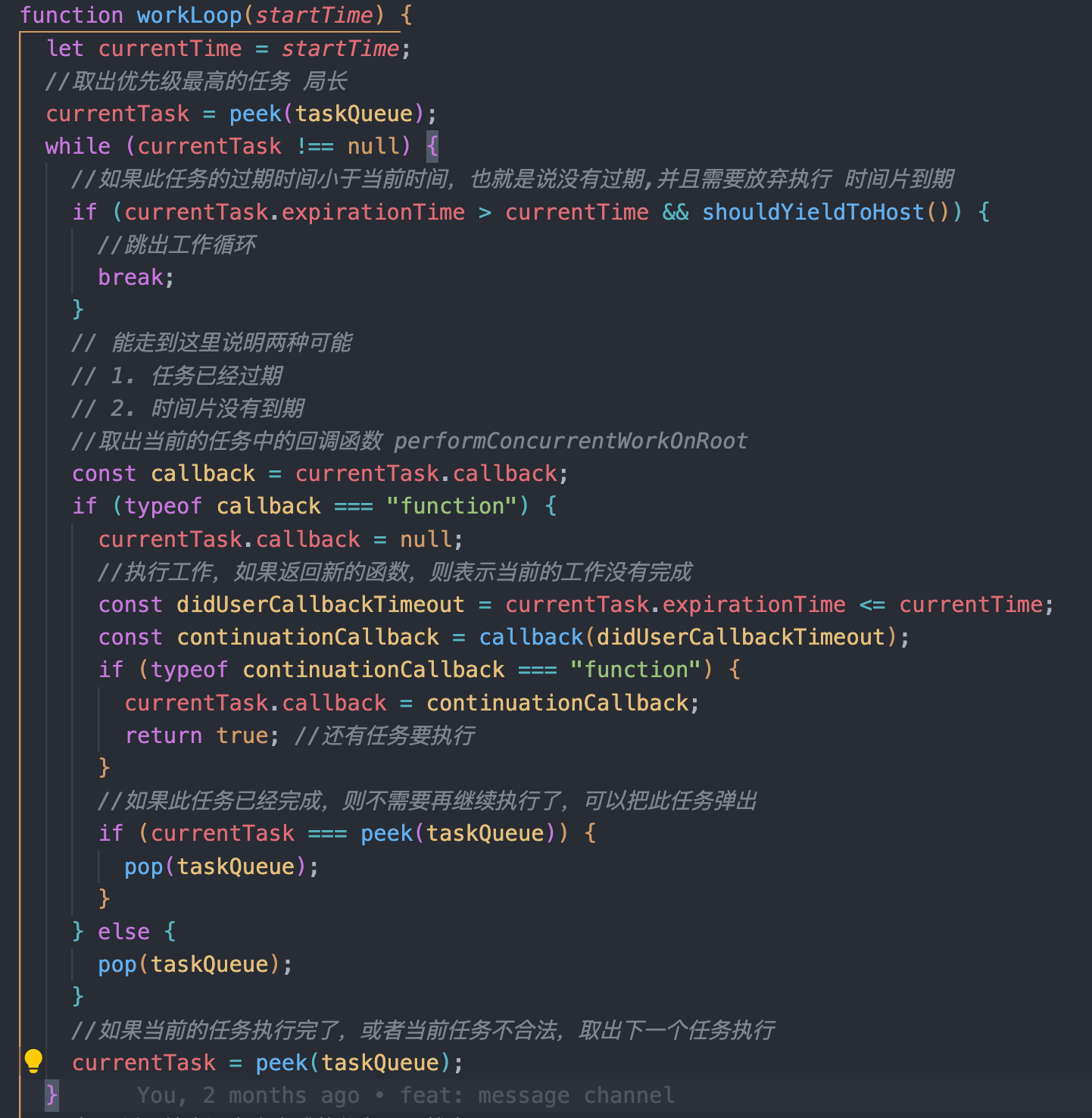
一旦通过此判断,就会执行
performConcurrentWorkOnRoot, 然后调用workLoopConcurrent,在其中每处理一个工作单元(fiber),都会再判断下时间片是否到期,如果到期就会中断这个任务
车道过期时间:车道的概念是在任务之下的,在一次任务执行中,会有一个renderLane的概念,即这个渲染的车道优先级,有且仅有比这个优先级更高的update才能被执行,否则就会被跳过。那么因为有31个车道,当root执行高优先级的渲染时就会跳过低优的update,此时这些低优的车道就会无限排队,直到被饿死。
所以这里就要给每个车道一个过期时间,如果过了这个时间还没执行此车道,那么就直接将这个车道放到同步车道中进行同步执行,即没有时间片的概念,不管花多少时间都会一把把它执行完。
概念总结
任务
一个任务其实就是由ensureRootIsScheduled触发schedule调度产生的一个渲染单元,一次任务可以简单理解为从根Fiber开始处理整个fiber链的过程 + commit。 其中处理整个Fiber链的过程又分为同步和异步两种模式,同步是不可被打断的,而异步可能因为时间片到期而被打断
在一个任务的执行过程中,可能会有各种新的事件触发ensureRootIsScheduled,这样堆里就会有新的任务加入,但一定是执行完了当前任务,才会从最小堆里找出过期时间最近的那个任务开始执行,所以从这个角度来说,任务一定是顺序执行的
任务+时间片的本质就是为了确保5ms的任务执行时间,不阻塞渲染。
车道
上面说了任务一定是顺序执行的,但同样setState为什么useEffect的执行会后于click呢?
首先两个任务之间,它们处理的Fiber其实是互为替身的关系(alternative),就是说他们的属性是有继承关系的,其中包括baseQueue和baseState这两个属性,上面已经说过他们的作用,本质就是用来做高优先级打断低优先级的现场保存和恢复工作的。也就是说一次任务可能因为renderLane优先级高,导致低优先级被跳过,只执行高优先级的,这样执行完整个fiber链,对任务来说确实是结束了,但是对Fiber来说还有未执行的update,所以会再调度一次ensureRootIsScheduled,向堆里push一个新的任务,用来执行完低优先级的更新
对于每个单独的update来说,它都有一个lane的属性来区别update应该在哪个车道进行更新
问题
假设页面上有1w个div,有1w个count state 0一一对应,此时通过一个useEffect把所有count都+1(写法是
setCount((s) => s + 1)),假设处理1w个元素的时间超过5ms。 那页面上的更新会先渲染一批再渲染余下吗? 答:页面不会分批更新,所有的+1结果还是最后统一渲染的(commit),虽然时间片到期了会打断fiber链的处理,但它的目的只是不阻塞渲染进程,React会判断一次任务完全结束,即fiber.return为null的时候,就是处理完了整个fiber链之后,才会开始commitRoot这个动作。 这样做也是符合原子性和一致性原则的同上假设,如果在useEffect中setState后立即触发一个click事件,将所有count - 1,那么页面会如何显示 答: 页面会分批更新,虽然useEffect的setState先触发,但是优先级低,此时相当于最小堆里被push了一个任务,同时又触发了一个同步任务,会先执行同步任务即click的setState,跳过useEffect中的setState,任务结束后commit root,页面显示-1,同时重新schedule一个任务,第二批任务通过保留和恢复更新queue的方式,重新计算了值,最后渲染到页面上为0。所以最终结果是保持一致性的