- Published on
不定期更新的有意思的面试题
- Authors

- Name
- McDaddy(戣蓦)
遍历list同步异步问题
问题:写出下面的输出
let list = [1, 2, 3]
let square = num => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(num * num)
}, 1000)
})
}
function test() {
list.forEach(async x => {
const res = await square(x)
console.log(res)
})
}
test()
结果是一秒后同时输出1 4 9, 如果想每隔一秒输出一行怎么改,且不能改square
async function test() {
for(let i of list) {
const res = await square(x)
console.log(res)
}
}
test()
为什么list.forEach不能同步执行呢?可以看到它的实现,本质上它只是执行了这个callback但是完全没有await,所以就直接略过了
Array.prototype.forEach = function (callback) {
// this represents our array
for (let index = 0; index < this.length; index++) {
// We call the callback for each entry
callback(this[index], index, this);
}
};
总结:list.forEach/map等都是异步执行函数的,但使用for…of/in就可以同步执行
JavaScript: async/await with forEach()
宽松等于和严格等于
经典面试题(a == 1 && a == 2 && a == 3)
实现的核心就是利用宽松等于的类型转换,当==时
- 左右两边必须有至少一种原始类型, 如果是
obj1 == obj2那么他们typeof的类型是相同的,所以不会发生类型转换,直接开始强等,这里和obj1 === obj2等价 - 左右两边会隐式转换成相同的原始类型,比如这里右边是原始类型number,那么左边也会被隐式转换成基本类型。转换的过程是
ToPrimitive(input, PreferredType?)
- 如果input是原始类型,那就直接返回input。
- 如果input是Object类型,那就调用valueOf方法,如果返回原始类型,那就返回这个结果
- 如果还不是那就调用a.toString方法,如果返回的是基本类型(toString可以人为重写,所以不一定返回的就是string类型),就是返回这个结果
- 如果都不是就会抛出一个
TypeError,表示转化失败。 - 如果
PreferredType是string,那么第二步和第三步位置互换
最终解法:
const obj = function () {
this.value = 0;
}
obj.prototype.valueOf = function () {
this.value += 1;
return this.value;
}
const a = new obj()
if(a == 1 && a == 2 && a == 3) {
console.log(true);
}
宽松比较的十步流程
- type x 和 type y 是否相等,即typeof左右是否相等,如果相等则直接变成
===强等返回结果 - x是null且y是undefined,返回true
- x是undefined且y是null,返回true
- 如果x是number,y是string,返回 x == toNumber(y)
- 如果x是string,y是number,返回 toNumber(x) == y
- 如果x是Boolean,返回 toNumber(x) == y
- 如果y是Boolean,返回 x == toNumber(y)
- 如果x是string、number或symbol,y是object,返回x == toPrimitive(y)
- 如果x是object,y是string、number或symbol,返回toPrimitive(x) == y
- 返回false
总结一下:
- 对象之间对比宽松对比等于严格对比,比的是内存地址
- null和undefined 永远宽松相等
- string和number对比永远是string转成number然后比
- 布尔类型会转成number(1/0),然后对比,例子:
[] == 0 [] == false - String、number、symbol和对象对比都强制对象做toPrimitive,过程见上面部分
- 最后一步涵盖大多数场景,比如
obj == null 123 == null funcA == obj
最近又看到了扩展,如何实现(a === 1 && a === 2 && a === 3),当严格相等时是不会有任何隐式转换的,所以上面那套机制就肯定不成立, 这里就只能利用对象的getter来实现了
const nodeObj = {};
let value = 0;
Object.defineProperty(nodeObj, 'a', {
get: function () {
return value += 1;
},
})
if(nodeObj.a === 1 && nodeObj.a === 2 && nodeObj.a === 3) {
console.log('强等 true');
}
[] == 0 // true
[0] == 0 // true
[1] == 0 // false
[] == [] // false 因为对象和对象比,只比地址
[] == ![] // true 因为!优先级大于==,![]会做一个强制转换Boolean([])结果是true,取反就是false,然后根据上面第7步,右边是boolean先转为number false -> 0, 0再和[]比较就是true
[1 < 2 < 3, 3 < 2 < 1]
// 从左到右执行,1 < 2 返回true, true < 3 -> 1 < 3 返回true
// 3 < 2 返回false, false < 1 -> 0 < 1 返回true
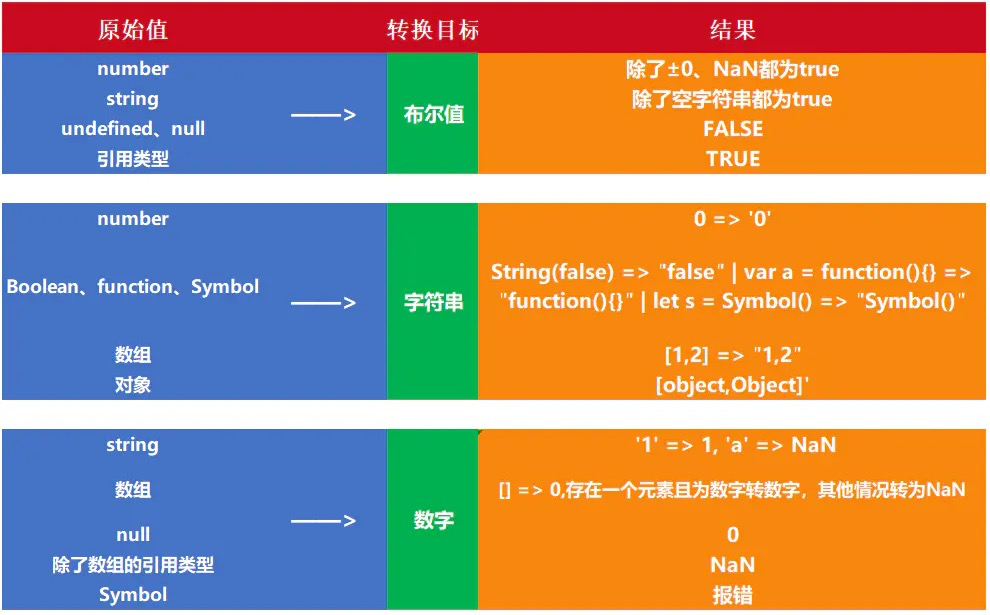
附:类型转换表
连续等号问题
var a = {n: 1}
var b = a
a.x = a = {n: 2}
console.log(a.n, b.n);
console.log(a.x, b.x);
两个原则:
.的优先级是高于=的=的运算顺序是从右到左
运算过程:
b = a 此时b和a共用一个引用
.运算符优先级高,所以先执行a.x 其实就是b.x=运算符从右到左计算,a = { n: 2 }时,a的引用改变,而b没变a.x = a 就是 b.x = a 即
b.x = {
n: 2
}
b就是
{
n: 1,
x: {
n: 2
}
}
a 就是
{
n: 2
}
扩展:问, 连续等号var a = b = 1中b的作用域是什么
// 实际执行伪代码
b = 1;
var a = b
所以b前面是没有var或者let之类的限定符的,没有var的就是绝对的全局变量,即使放在函数里面也是全局变量
(function() {
var a = b = 3;
})();
console.log(typeof a === 'undefined'); // Error a is not defined, 但是用typeof时还是undefined, 所以是true
console.log(typeof b === 'undefined'); // false b 是全局变量
再扩展:关于运算符优先级,new 运算符总是会找到离他最近的()
new Person().getName()
new Person.getAge()
优先级排序,从高到低
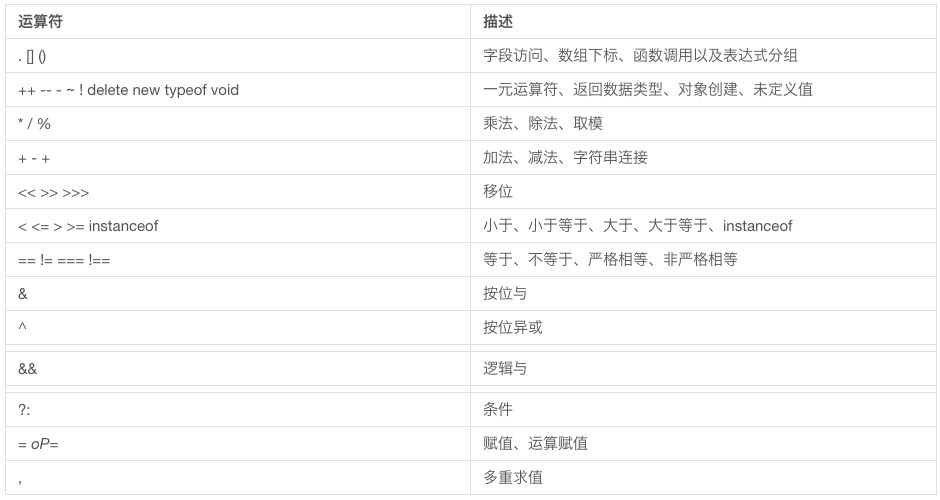
根据上面的图再扩展
var val = 'smtg';
console.log('Value is ' + (val === 'smtg') ? 'Something' : 'Nothing');
结果是Something,不会带上前面的Value is。 原因就是+操作符大于条件运算符,所以这个表达式就变成了('Value is ' + (val === 'smtg’)) ? 'Something' : 'Nothing'
const name = 'TianTianUp'
console.log(!typeof name === 'string') // false
console.log(!typeof name === 'object') // false
!优先级大于===, 所有!typeof name 就是false, 然后false对比字符串也是false
Array
sort
const array = [98, 10, 8], 然后调用array.sort(),结果得到[10, 8, 98]
原因是sort默认是会把内容都转成string然后再排序,因为’10’ < ‘8’,所以得到上面的结果。 所以数字排序必须加比较函数
array.sort((a, b) => b - a < 0);
forEach
const nums = [1, 2, 3, 4, 5, 6];
let firstEven;
nums.forEach(n => {
if (n % 2 ===0 ) {
firstEven = n;
return n;
}
});
console.log(firstEven); // 6
原因是在Array.prototype.forEach的源码中,传入的fn只是按顺序执行,即使return了也只是return当前的Callback,不会中断整个循环
if (!Array.prototype.forEach)
{
Array.prototype.forEach = function(fun /*, thisp */)
{
"use strict";
if (this === void 0 || this === null)
throw new TypeError();
var t = Object(this);
var len = t.length >>> 0;
if (typeof fun !== "function")
throw new TypeError();
var thisp = arguments[1];
for (var i = 0; i < len; i++)
{
if (i in t)
fun.call(thisp, t[i], i, t);
}
};
}
作用域问题
var a = 0,
b = 0;
function A(a) {
A = function (b) {
console.log(a + b++)
}
console.log(a++)
}
A(1)
A(2)
第一个A(1)的答案很简单,直接执行function A,输出a++ 还是1
第二个A(2)就有点意思了,首先肯定能确定的是第二次走的A是内层的function,因为A被第一次执行之后被重新定义,所有输出的是a + b++,b肯定是2, 问题关键在于a是什么,直观的想就是直接去外层找作用域,如果找到最外层0就错了, 实际应该找外层A的闭包a,在第一次执行已经变成了2,所以输出4。
词法作用域,一定一定要一层层找。
奇怪的知识
void 0 值就是undefined
undefined在浏览器不是保留字, 所以可以let undefined = 1,这是不会报错的,所以一般用void 0 来判断undefined
Math.min() 为什么比 Math.max() 大?
Math.min没参数时返回infinity, Math.max没参数时返回-infinity
Symbol() 可以作为Object的key,但是无法被遍历
let a = {}
let b = Symbol(1)
a[b] = 2
Object.keys(a) // []
a.hasOwnProperty(b) // true
a[b] // 2
事件循环
求下面的输出结果
new Promise((resolve) => {
console.log(1)
resolve()
}).then(() => {
console.log(2)
new Promise((resolve) => {
console.log(3)
resolve()
}).then(() => {
console.log(4)
new Promise((resolve) => {
console.log(5)
resolve();
}).then(() => {
console.log(7)
}).then(() => {
console.log(9)
})
}).then(() => {
console.log(8)
})
}).then(() => {
console.log(6)
})
这道题和普通事件循环题目不同在于这题还考察了同样是微任务加入微任务队列的顺序。整个执行过程大致如下
- 第一个loop,同步执行log1,执行到then,此时微任务队列加入then的callback(log2), 微任务队列中有【2】
- 第二个loop,清空微任务队列,执行log2, 同步执行log3, 执行到then产生新微任务,将4加入微任务队列,然后2的后面的then将6加入队列, 此时微任务队列有【4,6】
- 第三个loop,清空微任务队列,执行log4,同步执行log5,到then产生新微任务,将7推入队列,然后4的then同样产生微任务,将8加入队列,然后继续执行log6,6后面没有后续。 此时微任务队列有【7,8】
- 第四个loop,清空微任务队列,执行log7,then将9推入队列,然后log8, 此时微任务队列有【9】
- 第五个loop,清空微任务队列,执行log9
- 所有最终就是123456789
- 还有一个基本点就是,上一个then执行了才会执行到下面一个then
2020/09/24 重新理解这道题
同步执行1 resolve —> then 2 可以开始执行 3 是同步代码 4因为3的resolve加入队列 6因为2的then的同步代码结束了,自动resolve从而加入队列 —> 执行4 5 同步代码 7 因为5的resolve加入队列 8因为4的同步代码结束自动加入队列 —> 执行6 —> 执行7 9自动加入队列 —> 执行 8 —> 执行9
核心: 同步代码结束之后清算异步代码。加入队列, then什么时候能进入等待队列,看上面一个then中的resolve执行了没
如何处理项目中的异常捕获行为
代码执行的错误捕获
- try/catch
- 能捕获到代码执行的错误
- 无法处理异步中的错误
- 使用try……catch包裹,影响代码可读性
- window.onerror
- 无论是异步还是非异步错误,onerror都能捕获到运行时错误
- onerrer主要是来捕获预料之外的错误,而try/catch则是用来在可预见情况下监控特定的错误,两者结合使用更高效
- window.onerror函数只有在返回true的时候,异常才不会向上抛出,否则即使是知道异常的发生控制台还是会显示:
Uncaught Error:xxxxx - 当我们遇到404网络请求异常的时候,onerror是无法帮助我们捕获到异常的
- window.addEventListener('error',function,boolean)
window.addEventListener("error",(msg,url,row,col,error)=>{},true) - window.addEventListener('unhandledrejection') 捕获Promise错误,当Promise被reject处理器的时候,会触发unhandledrejection事件;这可能发生在window下,但也可能发生在Worker中。这对于调试回退错误处理非常有用
为什么Class继承时必须写super?
class的本质还是语法糖,这个问题也可以直接理解为class是如何实现继承的。可以通过rollup编译出来的es5代码来解释
// ES6 class
class Animal {
public name!: string; // 不写public默认也是公开的
public age!: number;
constructor(name: string, age: number) {
this.name = name;
this.age = age;
}
}
class Cat extends Animal {
constructor(name: string, age: number) {
super(name, age);
console.log(this.name,this.age); // 子类访问
}
}
// ES5
// undefined && undefined.__extends 主要是因为undefined不是保留字,可以给undefined赋值,比如undefined = function (){}
var __extends = (undefined && undefined.__extends) || (function () {
// 继承静态属性
var extendStatics = function (d, b) {
extendStatics = Object.setPrototypeOf ||
({ __proto__: [] } instanceof Array && function (d, b) { d.__proto__ = b; }) ||
function (d, b) { for (var p in b) if (Object.prototype.hasOwnProperty.call(b, p)) d[p] = b[p]; };
return extendStatics(d, b);
};
// d == Cat b == Animal
return function (d, b) {
extendStatics(d, b);
function __() { this.constructor = d; } // 定义一个叫__的临时函数,里面内容就是把constructor赋值成Cat
d.prototype = b === null ? Object.create(b) : (__.prototype = b.prototype, new __()); // Cat.prototype,当Animal为null的时候创建一个空对象,否则__的prototype = Animal的prototype。 而Cat.prototype赋值为new __()
};
})();
var Animal = /** @class */ (function () {
function Animal(name, age) {
this.name = name;
this.age = age;
}
return Animal;
}());
var Cat = /** @class */ (function (_super) {
__extends(Cat, _super);
function Cat(name, age) {
var _this = _super.call(this, name, age) || this;
console.log(_this.name, _this.age); // 子类访问
return _this;
}
return Cat;
}(Animal));
class的继承本质上还是一个组合寄生继承(详见原型链那篇),几个重要的点
- 要继承父的prototype,是为了继承父的原型方法,如果不继承prototype,那么只能把方法写成实例方法,这样每次new都要产生一个新的独立内存的方法,这是不必要的,所以我们写原型方法都是a.prototype.say = function()。使用纯原型链继承的问题是实例变量无法做到隔离,因为如果子继承是child.prototype = parent.prototype, 这样父的实例变量就丢了,所以必须要是child.prototype = new parent(), new parent()的__proto__是指向parent.prototype的,所以该拿的都能拿到,但是父上的实例变量在new parent时就生成了,所以所有的子实例都是共享同一份。
- 要调用父的构造函数,是为了拿到父的实例变量,因为实例变量是不共享的。所以每次都要调用父的构造函数,把父的实例属性赋值到子的this上,这样就做到了隔离。 如果纯构造函数继承,就会造成不继承prototype的问题
- 回到这个问题,调用super实际上就是调用parent的构造函数,这是组合继承必须要做的,为的就是拿到父上的实例变量。
Tree Shaking的原理是什么?
- ES6的模块引入是静态分析的,故而可以在编译时正确判断到底加载了什么代码。 此完成了哪些模块不需要加载
- 分析程序流,判断哪些变量未被使用、引用,进而删除此代码。 此完成了单个模块中哪些变量或代码块可以被移除
但是事实上,使用webpack打包很多情况下是做不到完美的tree shaking的,原因是什么呢?
原因是代码中含有副作用, 比如下面这段,即使这个函数没有被调用,他依然还有副作用
function go (url) {
window.location.href = url
}
副作用的定义:
一个函数会、或者可能会对函数外部变量产生影响的行为。
而且不仅仅是显式得用set去改变一个外部变量是副作用,即使是去获取一个外部变量的某个属性,如window.location也是副作用,因为getter和setter是不透明的,编译器不知道触发了getter会不会有修改外部变量的风险,为了保守所以就不会shaking掉这部分代码
接下来的问题是譬如Antd, Lodash这样的库为什么不能天生支持tree shaking?
因为这些库的都是编译好的,通过umd导出一个统一入口文件,其中用到了Object.defineProperty,它是有副作用的,所以就会导入所有的内容,所以现在antd都会去找它的es文件夹,是通过esModule导出的,可以做到按需加载,否则就必须通过插件实现
手写一个深拷贝
const cloneDeep = (target, cache = new Map()) => {
if (typeof target !== "object" || typeof target === 'function' || target === null) {
return target;
}
const cacheTarget = cache.get(target);
if (cacheTarget) {
return cacheTarget;
}
let cloneTarget = Array.isArray(target) ? [] : {};
if (target instanceof RegExp) {
cloneTarget = new RegExp(target.source, target.flags);
} else if (target instanceof Function) {
cloneTarget = function () {
return target.call(this, ...arguments);
};
} else if (target instanceof Date) {
cloneTarget = new Date(target);
} else {
for (const key in target) {
if (Object.hasOwnProperty.call(target, key)) {
const item = target[key];
cloneTarget[key] = cloneDeep(item);
}
}
}
cache.set(target, cloneTarget);
return cloneTarget;
};
const target = {
field1: 1,
regex: /ss/g,
func: () => {
let a = 1;
},
field2: undefined,
field3: {
child: "child",
},
field4: [2, 4, 8],
f: {
f: { f: { f: { f: { f: { f: { f: { f: { f: { f: { f: {} } } } } } } } } } },
},
};
const clone = cloneDeep(target);
console.log("clone: ", clone);
Reflect到底有啥用?
Reflect存在的价值
- 将一系列Object上面的方法移到Reflect上,将来这些方法在Object上将不存在,比如
Object.defineProperty - 操作更优雅,比如
Object.defineProperty如果出现错误就会报错,而Reflect.defineProperty就只是返回false - 让操作对象的编程变为函数式编程,比如
if(‘a’ in obj)是命令式的,Reflect.has(obj, ‘a’)是函数式的 - 保持与Proxy的方法一一对应
useEffect中的return是什么时候执行的
useEffect中的return有两种执行实际
- 组件卸载
- 当前effect执行前,用来清除上一个effect,下面的demo是个非常好的例子
在return方法中,其实相当于是可以修改上一个闭包中的值,与当前effect的闭包是隔离开的。
数组转树
核心:
- 用一个map来存储所有节点的id与node的值
- 当第二次遍历时,通过pid找到map中的父,直接添加child。如果是根元素,直接push到root中
[
{"id":1,"pid":0,"name":"上海市"},
{"id":2,"pid":1,"name":"杨浦区"},
{"id":3,"pid":1,"name":"静安区"},
{"id":4,"pid":2,"name":"营口路"},
{"id":5,"pid":3,"name":"北京西路"},
{"id":6,"pid":2,"name":"长海路"},
{"id":7,"pid":3,"name":"长寿路"},
{"id":8,"pid":4,"name":"1号楼"},
{"id":9,"pid":4,"name":"2号楼"}
]
function list_to_tree(list) {
let map = {}, node, root = [], i;
for(i = 0; i < list.length; i++) {
map[list[i].id] = i
list[i].children = []
}
for(i = 0; i < list.length; i++) {
const node = list[i]
if(list[i].pid !== 0) {
list[map[node.pid]].children.push(node)
}else {
root.push(node)
}
}
return root
}
实现InstanceOf
const myInstanceOf = (obj, target) => {
if (!(obj && ["object", "function"].includes(typeof obj))) {
return false;
}
let proto = Object.getPrototypeOf(obj);
while (proto) {
if (proto === target.prototype) {
return true;
}
proto = Object.getPrototypeOf(proto);
}
return false;
};
const obj = {};
console.log(myInstanceOf(obj, Object));
实现new操作符
const _new = function (func, ...args) {
// 步骤1和步骤2
let obj = Object.create(func.prototype);
// 也可以通过下面的代码进行模拟
/**
let Ctor = function () {}
Ctor.prototype = func.prototype
Ctor.prototype.constructor = func
let obj = new Ctor()
*/
// 步骤3
let result = func.apply(obj, args);
// 步骤4
if (
(typeof result === "object" && result !== null) ||
typeof result === "function"
) {
return result;
} else {
return obj;
}
};
CSP
本质就是一个白名单功能,告诉浏览器去限制什么样的资源能加载执行什么不能。
开启方式
- http头
- html meta标签
除此之外,还能控制比如,https的情况下能不能加载http,http的资源是不是自动升级为https等等
杂题
如何让const创建的对象内部也不能被改变
通过Object.defineProperty递归修改每个属性的writable
Reflect是做什么的
用来跟proxy一一对应的,比如proxy改了默认的get行为,Reflect上会有原来的默认行为,所以我们一般都会看到Reflect是用在Proxy的调用中的。
同时将一些命令式的方法改成了函数式的,比如a in obj -> Reflect.has(obj, 'a'). delete obj[name] -> Reflect.deleteProperty(obj, name)
commonJS与esm总结
- esm是Ecma的标准,commonjs是一种模块化的实现
- esm的import和export都是引用,commonjs都是值的拷贝
- esm的运作分为三步
- Construction 寻找文件路径,下载所有文件并解析成一个module record
- Instantiation 在内存中分配地址,给所有的export,但此时仅仅是有一个引用,并没有真正赋值(比如export const a = 1, 此时a存在,但是没有被初始化,同暂时性死区),同时将import和export做一个接线,即import和export都指向同一块内存引用
- Evaluation 真正跑初始化代码,将导出都赋上初始值
- 以上三步,因为第一步往往很慢,所以这三步常被称为异步执行,相反的commonjs的
require永远是同步执行的 - 其中第二第三步,都会在第一步的基础上做一个深度优先的后续遍历,做到先初始化子节点,然后初始化根节点
- 两边都有缓存机制,commonjs缓存的是一个模块的拷贝。esm维护一个叫module map的东西,也确保一个模块不会被加载两次
- esm不能用变量来做import,而commonjs可以
- 关于循环引用
// a.js
const { b } = require('./b.js')
console.log('this is a', b);
exports.message = '888';
// b.js
const { message } = require('./a.js');
setTimeout(() => {
console.log(message);
// const { message: m2 } = require('./a.js');
// console.log(m2); // 这样是能打出message的
}, 1000);
console.log(message);
module.exports = {
b: 123,
};
结果执行node a.js 输出
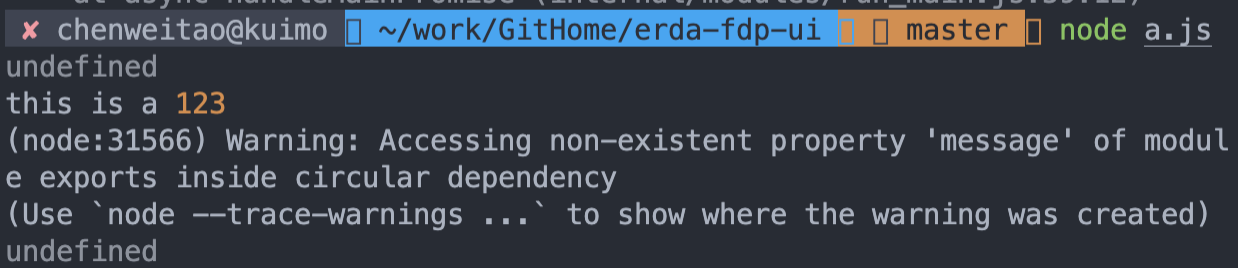
说明顺序是:
- 加载然后执行a.js,从第一行开始同步加载b.js,
- b.js第一行又要去加载a.js,但此时发现缓存里面已经有a.js的缓存,所以不会去再初始化a
- 继续初始化b,当打印message时,a的初始化还没完成,所以打印
undefined - 最后导出b,回到a.js的初始化得到已经初始化好了的b并且打印出来,最后再导出了message
- 最后在b的setTimeout中,虽然1秒后a已经初始化结束,但是它得到的a拷贝没有变化,所以打出来的还是undefined
// a.mjs
import b from './b.mjs'
console.log('this is a', b);
const message = '888';
export default message
// b.mjs
import message from './a.mjs'
//setTimeout(() => {
//console.log(message);
//}, 1000);
console.log(message);
const b = 123;
export default b;
在没有setTimeout的情况下输出
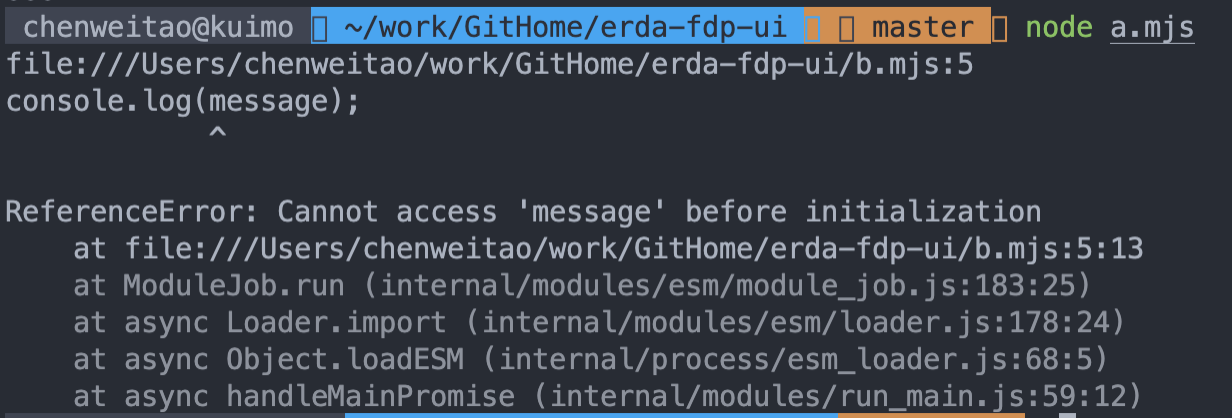
这就类似我们let的暂时性死区,这个导出的变量是存在的,但是还没有被初始化,结果直接报错。
如果改成setTimeout

这个结果就不会报错,也不会有警告。因为esm的import和export都是活的link,当初始化结束后,import就能得到最新的结果
WeakSet特点与作用
特点:
- 只能存放对象,基本类型不能放
- 当存放的对象没有被引用时,垃圾回收会直接把它回收,而不用管它还在这个set中
- 因为垃圾回收的时机不可控,所以遍历的前后元素可能不同,所以它不可以被遍历
作用:
- 用来存放DOM节点,如果存放在普通set中, 如果节点被删除,这个引用依然存在,就会导致内存泄露
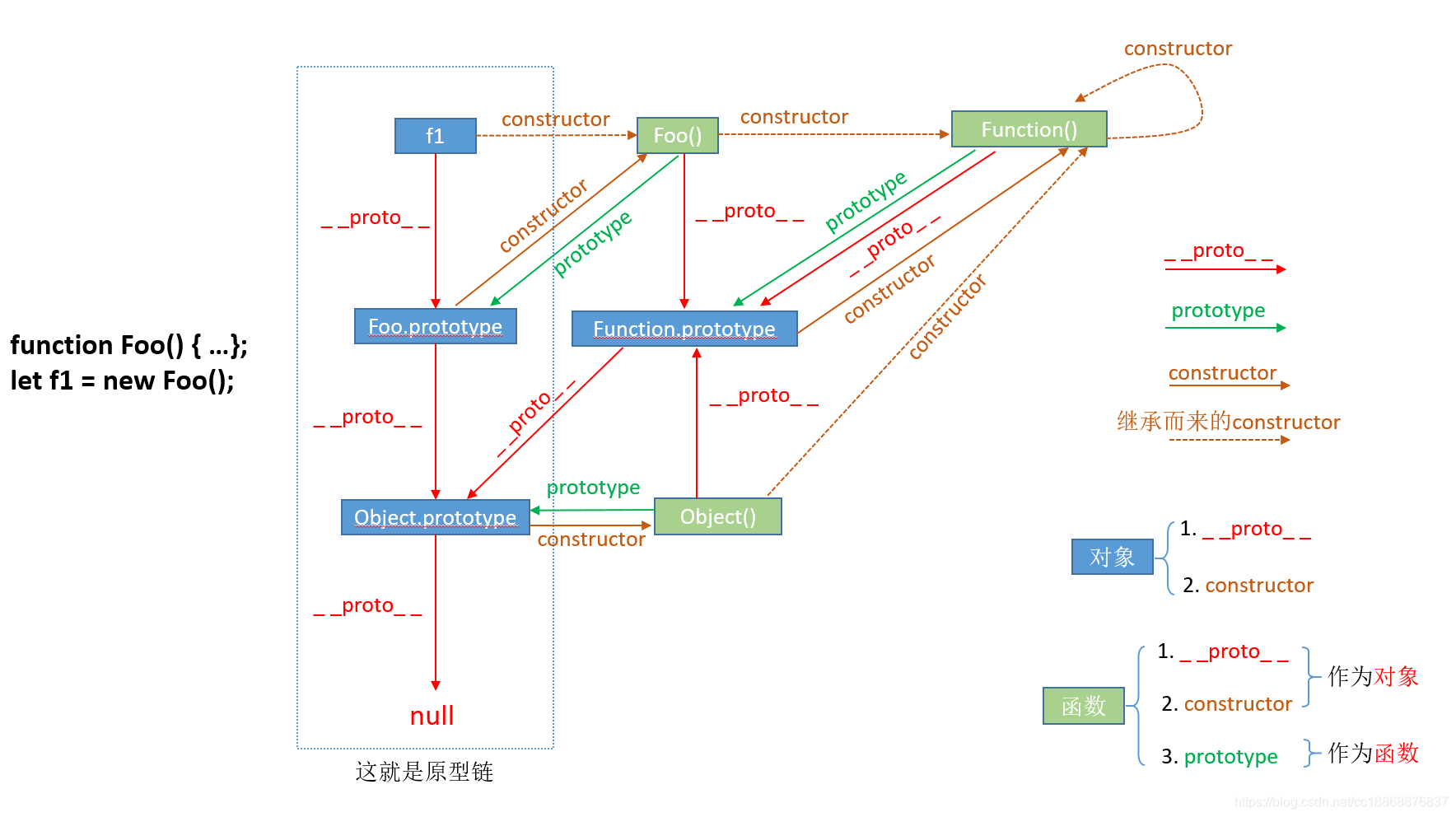
原型链
React Vue异同

Fiber
- 16以前dom更新都是递归实现,过程是无法打断的,导致了组件数量大时,长期占用主线程导致了页面卡顿
- 思想
- 利用浏览器空闲的时间来做对比dom的操作
- 更新任务要做到可以打断,用循环替代递归
- 大任务分割成小任务
- 原理
- 利用message Channel的postmessage来模拟ric, 以调度任务,原理是两个port配合raf
- 实现组件调用栈,就是把组件的更新顺序用链式的结构串联起来,这样更新到哪儿都可以随时暂停,恢复等操作
- Fiber数据结构
return父节点,可以用来回溯child所有子节点sibling兄弟节点stateNode对应的dom节点expirationTime过期时间effect变更
- fiber树本质是一个链表
- 树上每产生一个新的节点都会检查是否有更高优先级的任务,没有的话继续执行树的构建,否则会丢弃当前生成的树,等高优先任务结束后,空闲时重新执行一遍
优化提速
打包优化:
- 升级webpack5,开启本地缓存
- thread-loader
- terser plugin开启多进程 或者使用esbuild plugin
- include/exclude/alias 加速模块搜索
- 选择合适的source-map,
eval-cheap-module-source-map - speed mesure plugin但是webpack5 有问题
- bundle-analysis 分析包大小
- 开启tree shaking, 只要开启production mode即可 配合terser plugin
- 添加
extensions减少匹配后缀的时间 - terser plugin + mini-css-extract-plugin + 资源压缩
- splitChunk,提取公共模块
加载优化:
- 骨架屏
- SSR
- 开启gzip + HTTP2
- 缓存策略
- PWA
- CDN
- preload(写在html里面,提前加载) + prefetch(闲的时候加载)
代码层:
- 虚拟列表
- 防抖节流
- useMemo
- 懒加载 suspense + lazy
- 升级React18
- 减少重排
场景编程题
实现一个fetchWithRetry
关键点:
- 需要用到递归,当失败的时候递归调用
- 需要单独抽出一个函数来做递归,原因是如果直接递归整个fetchWithRetry,那么每次递归用的都是自己的resolve和reject,即使调用了最外层也接受不到了
function fetch(i) {
return new Promise((resolve, reject) => {
setTimeout(() => {
// resolve(i);
reject(Error(i));
}, 1000);
});
}
function fetchWithRetry(param, n) {
return new Promise((resolve, reject) => {
const run = () => {
fetch(param)
.then((res) => {
resolve(res);
})
.catch((e) => {
if (n > 0) {
return run(param, --n);
}
reject(e);
});
};
run();
});
}
fetchWithRetry(22, 3)
.then((res) => {
console.log('res: ', res);
})
.catch((e) => {
console.error('error', e);
});
// 第二个重点,当new Promise之后,即使在里面return了一个promise,但没有调用resolve或者reject这个promise就不会改变状态
// 所以下面的s是不会打印的
const p = new Promise((resolve) => {
return Promise.resolve(1);
});
p.then((s) => {
console.log('s: ', s);
});
实现可以控制并发数的池
function Pool() {
this.limit = 3;
this.queue = [];
this.runCount = 0;
}
Pool.prototype.add = function (task) {
this.queue.push(task);
};
Pool.prototype.exec = function () {
while (this.runCount < this.limit && this.queue.length) {
const p = this.queue.shift()();
this.runCount++;
p.then(() => {
this.runCount--;
this.exec();
});
}
};
function fetch(i) {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('done');
resolve(i);
// reject(Error(i));
}, 1000);
});
}
const taskPool = new Pool();
taskPool.add(() => fetch(1));
taskPool.add(() => fetch(2));
taskPool.add(() => fetch(3));
taskPool.add(() => fetch(4));
taskPool.add(() => fetch(5));
taskPool.add(() => fetch(6));
taskPool.add(() => fetch(7));
taskPool.add(() => fetch(8));
taskPool.add(() => fetch(9));
taskPool.add(() => fetch(10));
taskPool.exec();
preload与prefetch的区别
preload
- preload 是写在服务端返回的HTML中的。用法如下,必须要加
as来告诉浏览器你要加载的是什么类型的资源,否则就会被认为是普通的xhr,浏览器会按照as中的类型来按优先级下载
<link rel="preload" href="https://tiven.cn/js/test.js" as="javascript">
- 什么时候用? 就是页面加载完成后必须会用到的资源,让浏览器提前加载指定资源(加载后并不执行),需要执行时再执行。如果不确定是否一定会用到的资源,不要用preload
- 比如同样是加载script,普通script标签是会阻塞渲染的,但是preload不管成功与否是不会阻塞的
- 如果跨域需要带上
crossorigin
prefetch
<link rel="prefetch" href="./js/01.js">
- 是告诉浏览器,接下来跳转的页面可能需要用到的资源,所以它下载下来可能用到也可能不会用到
- 它的优先级非常低,是在浏览器闲时才会触发
两者的核心区别:
- preload针对当前页,或者说根html,是必须用到的资源。而prefetch针对即将打开的页面,资源不一定用到
- preload优先级高,prefetch优先级低
samesite问题
什么是samesite?
samesite是一个Cookie的属性
SameSite=None:无论是否跨站都会发送 Cookie
SameSite=Lax:允许部分第三方请求携带 Cookie
SameSite=Strict:仅允许同站请求携带 Cookie,即当前网页 URL 与请求目标 URL 完全一致
它的出现主要是为了杜绝CSRF攻击,原理就是原本的CSRF攻击就是利用了http请求自动会带上cookie,在伪造网站或邮件中引诱用户点击操作,而操作后因为带上了cookie就通过了身份验证。而开启了samesite之后,不管是脚本,接口还是iframe都无法去发送这个cookie了,从而从本质上解决了CSRF问题
第二,这也限制了广告插件的存在,网页广告插件的原理就是,如以下场景
- 在百度中搜索耳机,此时埋在百度中的alimama插件就会把我们搜索的信息发送到ali的服务器,并附带上能标识当前身份的cookie(domain是alimama)
- 当打开淘宝时,这个插件依然存在,通过cookie它就能识别到当前这个人就是刚才搜耳机的那个,并通知淘宝。接下来就能刷到相关的推荐了
由于不能发送三方cookie了,所以这种广告行为也就很难实现了
同站不同于跨域,同站只需要一级域名相同即可
未来规划
- 夯实基础,钻研技术栈,大前端,从简历中也能看出我的技术探索精神和能力
- 尝试不同的可能,ToB/ToC/移动端/图形化/产品 等
- 从个人稳定性出发,想要做好一个产品,因为这样是最能提升个人成就感的
- 管理路线是根据在团队中的权重自然演进的,一切都是以技术能力为基础的,不会刻意而为
- 大平台成长性好的平台发展,因为我认为个人的发展和团队以及产品是相辅相成的,往往都是互相带动的
亮点:
- 结合我多年后端的经验做了很多项目的改进
- 前端微服务化
- 推进ts
- pnpm完善前端的包管理
- nestjs扩大前端版图
- 综上,提升项目的健壮性同时也做到不引人更多地bug
问题:
- 产品大概是做什么的
- 目前团队配置是怎样的?前端多少人,前后端产品测试的比例,是否有UED
- 未来半年的规划是怎样的?对我这个岗位的期望是怎样的
- 如果成行,那我现在有什么技术栈方面,或者软技能方面需要提前准备的