- Published on
【笔记】- NodeJS基础
- Authors

- Name
- McDaddy(戣蓦)
node.js 不是语言而是⼀个 JS 的服务端运⾏环境,简单的来说,他是在 JS 语⾔规范的基础上,封装了⼀些服务端的运⾏时对象,让我们能够简单实现⾮常多的业务功能。如果我们只使⽤ JS 的话,实际上只是能进⾏⼀些简单的逻辑运算。node.js 就是基于 JS 语法增加与操作系统之间的交互。
NodeJS解决了什么问题
Node在处理高并发,I/O密集场景有明显的性能优势
- 高并发,是指在同一时间并发访问服务器
- I/O密集指的是文件操作、网络操作(XHR)、数据库,相对的有CPU密集,CPU密集指的是逻辑处理运算、压缩、解压、加密、解密
- 做中间层,解决浏览器跨域问题
- 前端工程化,npm/webpack等工具的基础
NodeJS的单线程
JS的单线程指的是主线程是单线程,这个JS还是可以利用多核来运行的,比如我们的定时器、网络请求等待都是调用了其他线程来实现的。由于主线程是单线程的原因,开发者不需要关心锁的问题,并且节约内存(因为像Java那样多线程,每个线程都是需要内存开销的),不需要切换执行上下文。缺点就是因为单线程,如果处理CPU密集型(大运算量)就会出现阻塞
NodeJS的底层依赖
- V8引擎:用来对JS语法进行解析,有了它才能基于JS来做开发,理论上讲把V8换成别的语言的引擎那也可以用别的语言来开发node,quickJS是一个相比V8更加轻量的JS执行引擎,对嵌入式的设备更友好,也许会成为将来的实现。
- libuv:c 语⾔实现的⼀个⾼性能异步⾮阻塞
IO 库,用来实现nodeJS的事件循环。 - http-parser/llhttp:用来处理底层http请求、报文、解析等内容。
- openssl: 处理加密算法,各种框架运⽤⼴泛。
- zlib: 处理压缩等内容。
NodeJS中的全局对象
浏览器中的this是window,服务端中的this指代的是global。但是默认我们访问的模块中的this都是被内容更改的,指向module.exports
NodeJS的全局属性
- setTimeout
- setInterval
- clearInterval
- clearTimeout
- queueMicroTask
- setImmediate
- process
- Buffer
- console
NodeJS的事件循环
本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
| 执行延迟到下一个循环迭代的 I/O 回调。
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
| 仅系统内部使用。
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘
| 检索新的I/O事件;执行与 I/O相关的回调 ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ setImmediate() 回调函数在这里执行。 └───────────────┘
│ ┌─────────────┴─────────────┐
│ │ check │
│ └─────────────┬─────────────┘
| 一些关闭的回调函数
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
每一个阶段都对应一个事件队列,当event loop执行到某个阶段时会将当前阶段对应的队列依次执行。当该队列用尽或达到回调上限,事件循环移动到下一阶段
pending callbacks / idle, prepare / close callbacks 都是系统内部调用,使用者无法控制
i/o 文件读写自动会放到poll阶段中处理
process.nextTick不属于事件循环的一部分
以下代码执行的结果是有两种可能的, timeout和immediate都有可能第一个输出,原因是当主线程结束,timers队列有一个callback,check队列也有一个callback,大多数情况下都是immediate先输出,因为setTimeout的0实际上不会是真的0,是会有一定延迟的,此时timers阶段的callback事实上还没到点,所以就跳过开始loop后面的,直到check阶段输出immediate,但多次运行这段代码,就有可能延迟小,timeout先输出。
setTimeout(() => {
console.log('timeout')
}, 0);
setImmediate(()=>{
console.log('immediate')
});
同样的代码放在I/O的回调中,无论运行多少次都是immediate先输出,因为I/O回调属于poll阶段,当它结束之后,直接进入check阶段,所以不可能先输出timeout
const fs = require('fs');
fs.readFile('./note.md',function () { // I/O 轮询时会执行i/o回调 如果没有定义setImmediate会等待剩下的i/o完成 或者定时器到达时间
setTimeout(() => {
console.log('timeout')
}, 0);
setImmediate(()=>{ // 不是特别重要的任务 可以放到setImmediate
console.log('immediate')
});
})
在NodeJS中如果不需要设延迟时间的情况下,都可以用setImmediate来替代setTimeout
以下代码输出顺序为nextTick -> promise -> timeout。 原因是process.nextTick是微任务,它的执行时机是主线程执行栈执行完毕后(同步代码执行完毕)立即执行,同样是微任务但是优先级高于promise.then
setTimeout(() => {
console.log('timeout')
}, 0);
Promise.resolve().then(()=>{
console.log('promise')
})
process.nextTick(()=>{ // 当前执行栈中执行完毕后 立即调用的
console.log('nextTick')
});
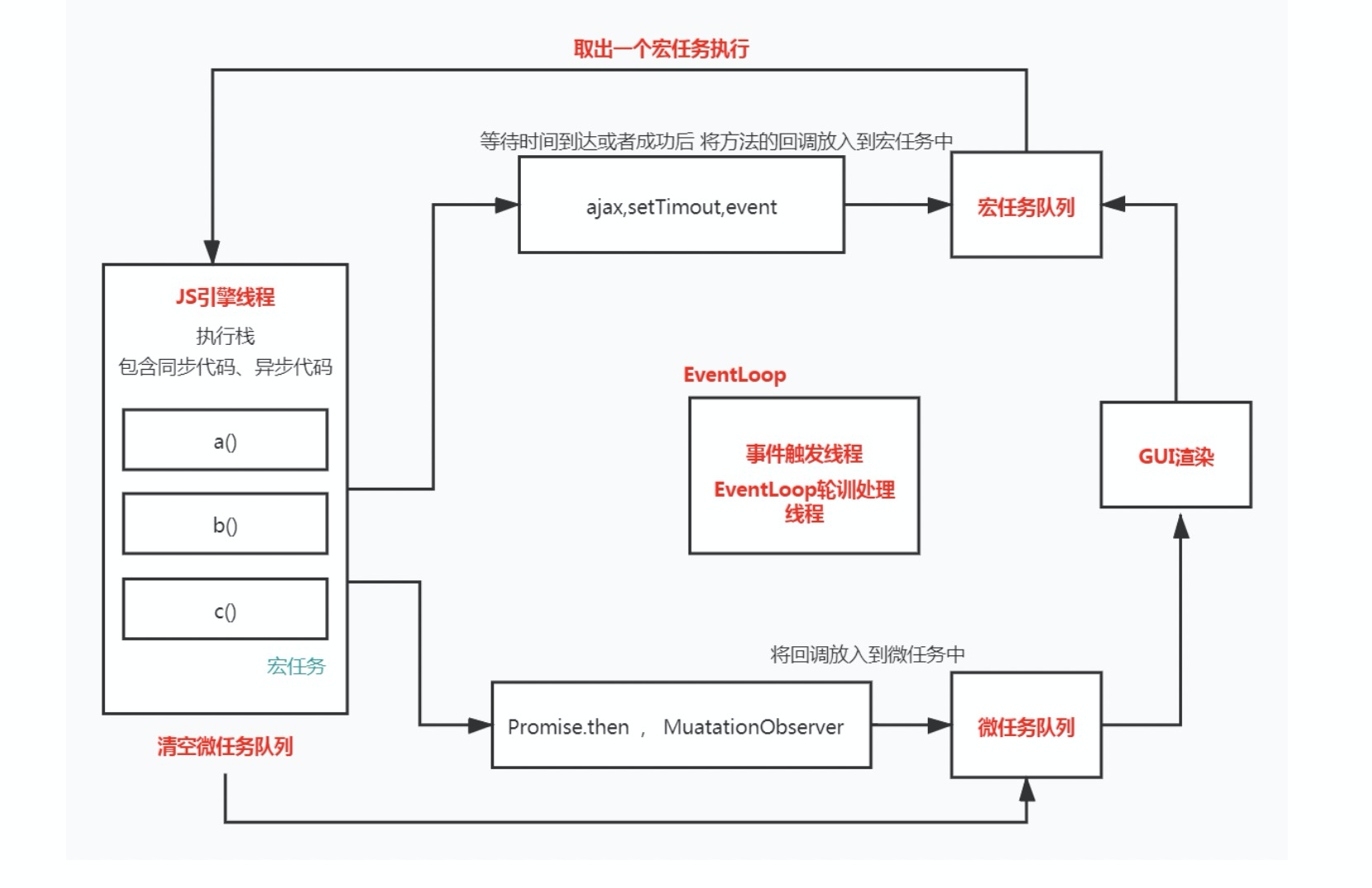
NodeJs与浏览器Event Loop的区别
浏览器的事件循环只有两个队列,宏任务队列和微任务队列,清空完微任务之后还有一步重新渲染页面(不是每次都执行)
以下代码段,如果是setTimeout页面会有显示红色的瞬间,如果是promise则自始至终都是黄色,因为渲染页面是在执行完主线程和清空微任务之后执行的
<script>
document.body.style.background = 'red';
console.log(1)
// Promise.resolve().then(()=>{
// console.log(2)
// document.body.style.background = 'yellow';
// })
setTimeout(() => {
console.log(2)
document.body.style.background = 'yellow';
}, 0);
console.log(3);
</script>
Node的事件循环按照阶段分有6个队列,每个阶段都有自己的队列,而这些队列里的任务都是宏任务,每执行完一个宏任务都会清空微任务
CommonJS的实现
众所周知,CommonJS并不是ECMA规范所支持的模块化方案,相比ES Module, CommonJS完全可以理解为是运行环境为代码封装模块化提供的一种非语法层面的实现。 类似是一种polyfill,脱离node环境就是无法运转起来的。
如果我们要自己实现CommonJS的这套模块化规范,理论上只需要一个类似V8的JS引擎就可以做到
// 如果同时存在a.js 和 a.json 优先级
const path = require('path');
const fs = require('fs');
const vm = require('vm');
function Module(filename){
this.id = filename; // 文件名
this.exports = {}; // 代表导出的结果
this.path = path.dirname(filename); // 父亲目录
}
Module._cache = {}
Module._extensions = {};
Module.wrapper = (content) =>{
// 假如说我把变量挂载在了global newFunction 是获取不到的
return `(function(exports,require,module,__filename,__dirname){${content}})`
}
Module._extensions['.js'] = function (module) {
let content = fs.readFileSync(module.id,'utf8');
// 根据内容包裹一个函数
let str = Module.wrapper(content); // 目前只是字符串
let fn = vm.runInThisContext(str); // 让字符串变成函数
let exports = module.exports; // module.exports === exports
// 模块中的this是module.exports 不是 module
// js 中的call会让函数改变this指向 并且让函数执行
fn.call(exports,exports,myReq,module,module.id,module.path);
// 这句代码执行后 会做module.exports = 'hello'
}
Module._extensions['.json'] = function (module) {
let content = fs.readFileSync(module.id,'utf8');
module.exports = JSON.parse(content); // 手动将json的结果赋予给module.exports
}
Module._resolveFilename = function (filename) {
let filePath = path.resolve(__dirname,filename);
let isExists = fs.existsSync(filePath);
if(isExists) return filePath;
// 尝试添加 .js 和 .json后缀
let keys = Reflect.ownKeys(Module._extensions);
for(let i = 0; i< keys.length;i++){
let newFile = filePath + keys[i]; // 尝试增加后缀
if(fs.existsSync(newFile)) return newFile
}
throw new Error('module not found');
}
Module.prototype.load = function () {
// 加载时 需要获取当前文件的后缀名 ,根据后缀名采用不同的策略进行加载
let extension = path.extname(this.id);
Module._extensions[extension](this); // 根据这个规则来进行模块的加载
}
function myReq(filename){
// 1.解析当前的文件名
filename = Module._resolveFilename(filename);
if(Module._cache[filename]){ // 直接将exports返回即可
return Module._cache[filename].exports;
}
// 2.创建模块
let module = new Module(filename);
Module._cache[filename] = module; // 将模块缓存起来
// 3.加载模块
module.load(); // 调用load方法进行模块的加载
return module.exports;
}
let r = myReq('./a'); // 默认只识别module.exports 的结果
console.log(r);
从上面的实现可以解释为什么module.exports = xxx和exports.xx = xx都是合理的。而exports = xxx是不合规的。因为把exports直接赋给一个值就等于把exports和module之间的引用关系给切断了。
其次,在node模块中的最外层的this都是指向module.exports的,所以基本都是,如果想得到global只能利用函数
function a() { // 此时的a函数是属于全局作用域,里面的this相当于浏览器的window
console.log(this); // global
}
a()
path.resolve vs join
path.resolve永远返回一个绝对路径, 只从最后一个/开始拼接。 path.join只是纯粹的拼接路径,会自动整理/
path.join('/a', '/b') // Outputs '/a/b'
path.resolve('/a', '/b') // Outputs '/b'
path.resolve('/a', '/b', '/c'); // /c
path.join('/a', '/b', '/c'); // /a/b/c
path.join('a', 'b', 'c'); // /a/b/c
如何查找模块
当遇到require(‘a’),将会如何查找模块?顺序如下
- 默认先查找当前文件夹是否有a.js文件
- 找当前文件夹是否有a.json文件
- 找当前文件夹是否有一个叫a的文件夹,有的话看是否有package.json, 有的话是否有看有没有main这个属性,有的话就找main的文件,否则找index.js
- 假设a不是一个核心模块,那么就会在当前文件夹的node_modules下找,没有的话就继续向上找直到根目录,找不到就报错
Node的event模块
event模块就是一个典型的发布订阅模式。主要提供几个api
- on 用来订阅,将一个事件回调注册在EventEmitter实例上
- emit 用来发布,触发所有之前注册过的事件回调
- once 用来订阅,但只触发一次之后就销毁
- off 用来取消订阅
- instance.on(’newListener’, cb), 当有新的注册事件时的回调注册
function EventEmitter(){
this._events = {}
}
// 订阅
EventEmitter.prototype.on = function (eventName,callback) {
if(!this._events){
this._events = Object.create(null);
}
// 当前绑定的事件 不是newListener事件就触发newListener事件
if(eventName !== 'newListener'){
this.emit('newListener',eventName)
}
if(this._events[eventName]){
this._events[eventName].push(callback)
}else{
this._events[eventName] = [callback]
}
}
// 发布
EventEmitter.prototype.emit = function (eventName,...args) {
if(!this._events) return
if(this._events[eventName]){
this._events[eventName].forEach(fn=>fn(...args))
}
}
// 绑定一次
EventEmitter.prototype.once = function (eventName,callback) {
const once = (...args) =>{
callback(...args);
// 当绑定后将自己移除掉
this.off(eventName,once);
}
once.l = callback; // 用来标识这个once是谁的
this.on(eventName,once)
}
// 删除
EventEmitter.prototype.off = function (eventName,callback) {
if(!this._events) return
this._events[eventName] = this._events[eventName].filter(fn=>((fn !== callback) && (fn.l!=callback)))
}
module.exports = EventEmitter
Buffer
编码的发展
一个字节由8个位组成,gbk中一个汉字占2个字节,utf8中一个汉字3个字节
- ASCII 满足英文母语和主要符号
- GB2312 两个字节表示汉字,那么理论上就是能容纳相当于16个位数的汉字 0~255 256 * 256 个汉字,实际上收录了6763个汉字和682个其它符号
- GBK是基于上面的扩展,包括21003个汉字和883个其它符号
- Unicode 如果用GBK编码去显示非中文和英文的语言就会乱码,Unicode是一个统一解决方案
- utf8 是Unicode的具体实现。一个汉字占3个字节,js语言用的是utf16
ArrayBuffer
arrayBuffer是前端H5中的二进制,new ArrayBuffer(n), 表示创建一个n个字节 n * 8位的内存单元,直接打印得到的结果是一个全是0的n字节空内容,默认是以8位作为一个字节
{ [Uint8Contents]: <00 00 00 00>, byteLength: 4 }
如果要读取这段Buffer,需要转换成对应位的无符号Array,同样4个字节的arrayBuffer传入new Uint16Array(arrayBuffer)就会变成2 * 16的结构,Uint32Array以此类推
const arrayBuffer = new ArrayBuffer(4); // 字节 4 * 8
let x = new Uint8Array(arrayBuffer); // []
x[0] = 1;
x[1] = 255; // [1, 255, 0, 0]
// 00000000 0000000 1111111100000001
let x2 = new Uint16Array(arrayBuffer); // 16 2
console.log(x2); // [65281, 0]
let x3 = new Uint32Array(arrayBuffer); // 16 2
console.log(x3); // [65281]
JS的进制转换方法
parseInt 用来将任何进制转换成十进制
console.log(parseInt('11111111', 2)) // 255
Number.toString(2/8/16) 用来将十进制转成各种进制
Number(255).toString(16) // "ff"
Number(255).toString(2) // "11111111"
Number(255).toString(8) // "377"
Base64生成的规则
Base64不是加密方式,是一种编码,主要用于url替换和小图片之类资源的替换
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3 * 8 = 4 * 6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
// Buffer.from('xx') 可以得到内容对应的编码结构
let r = Buffer.from('韡');
console.log(r) // e9 9f a1 3*8
console.log(0xe9.toString(2)); // 得到三个字节的二进制
console.log(0x9f.toString(2));
console.log(0xa1.toString(2));
// 接下来是base64关键的一步, 它会把3 * 8 变成 4 * 6的字节组合,保证每个字节都是6位
// 11101001 10011111 10100001 // 将 3 * 8的格式 拆分成 4 * 6
// 得到4位的十进制
console.log(parseInt('111010', 2)) // 58
console.log(parseInt('011001', 2))// 25
console.log(parseInt('111110', 2)) // 62
console.log(parseInt('100001', 2)) // 33
// str是64位所有的内容,所有的内容都将由这64位中的内容替换
let str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
str+=str.toLowerCase();
str+='0123456789+/';
console.log(str[58] + str[25] + str[62] + str[33]); // 6Z+h
console.log(Buffer.from('韡').toString('base64')) // 6Z+h
// 同样的方法去计算字母a的base64编码
// utf8编码是 0x61
// 二进制是parseInt('61', '16').toString(2) = 00000001100001 结果是两个字节按6位分割一下就是 000000 011000 010000 最后的01后面用0填补
// 第一位是24 第二位16就是YQ 然后不足6 * 4的部分会用=来填补
console.log(Buffer.from('a').toString('base64')) // YQ==
定义Buffer的三种方法
const b1 = Buffer.alloc(4) // 分配空的Buffer
const b2 = Buffer.from('哈哈哈') // 得到字符串的Buffer
const b3 = Buffer.from([65,65,66]) // 用数组创建Buffer
Buffer的主要方法
- buff.toString() 参数可以传encoding,比如base64实现转码。
- buff.fill()
- buff.slice() buffer分片,大文件上传下载用
- buff.copy
- Buffer.concat() 作用同slice
- Buffer.isBuffer() 判断是不是Buffer
前端的二进制对象
前端最常用的Blob对象 binary large object (是不可变的) 代表的是文件类型
URL.createObjectURL可以通过一个Blob参数返回一个ObjectURL, 可以作为href和src,返回的不是一个字符串,而是一个资源的URL。如果URL.revokeObjectURL就会被销毁
// 实现前端下载
let str = `<h1>hello world</h1>`;
const blob = new Blob([str], {
type: 'text/html'
});
let a = document.createElement('a');
a.setAttribute('download', 'a.html');
a.href = URL.createObjectURL(blob);
document.body.appendChild(a);
Stream
流的种类
包括可读流(Readable)可写流(Writable) 双工流(Duplex)转化流(Transform)
可读流readStream
一个标准的可读流需要支持on('data') on('end') 如果是文件流会再提供两个方法 open/close
fs模块可以通过createReadStream来创建一个可读文件流,内部是继承了stream模块,其中需要调用fs的open/close/read方法
第一个参数是一个文件路径,第二个参数是options,其中主要包括
- encoding 默认null,则输出为buffer,也可以是utf8/base64,这样输出就是编码好的结果
- autoClose 是否读取完毕后自动关闭流
- start/end 表示读取的
字节数,包前包后 highWaterMark这个概念比较重要,直译就是水位线,默认64 * 1024字节,表示一次读取的量,如果文件的内容超过水位线那就需要分批读取,会分多次在on(‘data’)中返回,这样需要手动拼接内容
readStream的方法包括
- on 用来监听事件,包括error/data/close/open
- pause 用来暂停流
- resume 用来恢复流
const fs = require('fs');
// const ReadStream = require('./ReadStream')
const path = require('path');
// 内部是继承了stream模块 并且基于 fs.open fs.read fs.close方法
let rs = fs.createReadStream(path.resolve(__dirname,'test.txt'),{
// let rs = new ReadStream(path.resolve(__dirname, 'test.txt'), {
flags: 'r', // 创建可读流的标识是r 读取文件
encoding: null, // 编码默认null 则输出buffer 也可以是utf8
autoClose:false, // 读取完毕后自动关闭
start: 0, // 包前又包后 字节数
end: 13,
// 2 4
highWaterMark: 2 // 如果不写默认是64*1024
});
rs.on('error', function(err) {
console.log('error', err)
})
rs.on('open', function(fd) { // rs.emit('open')
console.log('open', fd);
});
let arr = [];
rs.on('data', function(chunk) { // UTF8 ASCII 49 -> 9
// rs.pause(); // 默认一旦监听了on('data')方法会不停的触发data方法
console.log(chunk);
arr.push(chunk)
});
rs.on('end', function() { // 文件的开始到结束都读取完毕了
console.log(Buffer.concat(arr).toString())
})
rs.on('close', function() {
console.log('close')
})
实现一个ReadStream步骤
内部会 new ReadStream 继承于Readable接口
内部会先进行格式化
内部会默认打开文件 ReadStream.prototype.read
Readable.prototype.read -> ReadStream.prototype._read
const {Readable} = require('stream');
class MyRead extends Readable{ // 默认会调用Readable中的read方法
_read(){
this.push('ok'); // push方法是Readable中提供的 只要我们调用push将结果放入 就可以触发 on('data事件')
this.push(null); // 放入null的时候就结束了
}
}
let mr = new MyRead;
mr.on('data',function (data) {
console.log(data);
})
mr.on('end',function () {
console.log('end')
})
mr.on('open',function () {
console.log('open')
})
// 文件可读流 可读流 不是一样的 可读流就是继承可读流接口,并不需要用到fs模块
// 基于文件的可读流内部使用的是fs.open fs.close on('data') end
pipe方法
pipe是连接可读流和可写流的管道,目的就是做到边读边写,同时不占过多的内存,原理就是readStream调用pipe时,就会监听rs的data事件把读到的chunk写入writeStream(ws.write(chunk)), 当数据量超过ws的水位线之后,就会触发rs的pause方法来暂停读取,当缓存队列被写入完成之后触发ws的drain事件从而来调用rs的resume继续读取。
可写流WriteStream
文件可写流的参数和可读流基本一致,区别是highWaterMark,在可读流中,它是一次能读的最大字节数,在可写流中它不能限制一次写的最大字节数,它只是一个标识,当ws.write(‘xxx’)内容大于highWaterMark时就返回false否则返回true,这个标识可以结合drain事件来实现利用有限内存写入的功能来用时间换空间,比如下面用一个字节写入10个数
highWaterMark默认是16k
如果多次写入的内容大于水位线,也就是说反复调用write方法, 那么当待写入的内容大于水位线时,水位线之外的内容用一个列表缓存起来进行排队写入,整个过程只有第一次是直接写入文件,结束之后递归检查缓存然后清空
end方法,可以传字符串,或者不传,如果传了就会把内容加在末尾,但能重复调用
总结起来就是,单次调write其实是可以写无限大的内容的。但如果是多次调用,那么大于水位线的部分都将排队写入。只有当待写入内容超过水位线时才会触发needDrain,即写完之后触发drain事件
// 用一个字节的空间来实现写入10个数
const fs = require('fs');
const path = require('path');
const ws = fs.createWriteStream(path.resolve(__dirname, 'test.txt'), {
highWaterMark: 1
})
let i = 0;
function write() { // fs.open('xxx','w')
let flag = true;
while (i < 10 && flag) {
flag = ws.write('' + i++)
}
}
write();
// 抽干事件 当我们的内容到达预期后,或者超过预期时会触发此方法 (必须等这些内容都写到文件中才执行)
ws.on('drain', function() {
write();
console.log('清空')
});
util模块中有用的方法
- util.inherits 利用
Object.setPrototypeOf(Girl.prototype ,EventEmitter.prototype)来实现继承