- Published on
Prometheus入门
- Authors

- Name
- McDaddy(戣蓦)
如何安装
最简便的方式通过Docker搭建环境
搭建网络
因为是通过启动Docker容器来搭建环境,容器间本身网络是隔离的,所以需要要先建立一个网络
docker network create promNetWork
结束后可以通过下面命令,验证网络是否创建成功
docker network ls
安装Prometheus
我们需要在本地控制Prometheus的配置,现在本地准备一个配置文件promethes.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['node-export1:9100']
输入启动命令,其中指明了用到的网络,还有通过-v指定了要挂载的配置文件
docker run -p 9090:9090 -v /my-dir/promethes.yml:/etc/prometheus/prometheus.yml --network promNetWork --name prom-server prom/prometheus
安装node-exporter
注意要给容器起个名字,和上面的targets对应
docker run -p 9100:9100 --network promNetWork --name node-export1 prom/node-exporter
打开http://localhost:9100/metrics验证
经过上面步骤,打开地址就能得到以下内容

安装Grafana
docker run -d -p 3000:3000 grafana/grafana
添加数据源
注意这里的url要填写成http://host.docker.internal:9090,因为这也是docker内部的通信

成功后Import一个官方的大盘,就能得到如下大盘

核心概念

Prometheus Server
核心组件,负责实现对监控数据的获取,存储以及查询。 主要做以下几件事
- 通过静态配置管理监控的目标,或者通过服务发现动态管理监控目标
- 通过Pull的形式从目标获取监控数据
- 对采集到的数据进行存储,本质就是一个TSDB
- 提供promQL,对外提供查询分析能力
- 提供UI,可视化查询promQL
- 联邦集群,在海量数据下扩展监控能力
Exporters
Exporter将监控数据采集的端点(Endpoint)通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
Prometheus用来告警的组件
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
指标(Metric)
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total - 表示当前系统接收到的HTTP请求总量)
指标类型
指标的值代表的含义类型是有区别的,比如node_load1是一个瞬时的值,而node_cpu是一个累加值,只会不断增加
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Gauge:可增可减的仪表盘
Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
使用Histogram和Summary分析数据分布情况
这两种是用来做数据分布统计的
PromQL
查瞬时数据
http_requests_total{instance="localhost:9090"}
结构就是一个metric名字 + 花括号 里面填条件
其中=和!= 表示精确匹配
=~和!~ 表示正则匹配
http_requests_total{environment=~"staging|testing|development",method!="GET"}
范围查询
http_requests_total{}[5m]
表示向前查询5分钟的内容
聚合操作
# 查询系统所有http请求的总量
sum(http_request_total)
# 按照mode计算主机CPU的平均使用时间
avg(node_cpu) by (mode)
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu{mode!='idle'}[5m])) / sum(irate(node_cpu[5m]))) by (instance)
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准方差)count(计数)count_values(对value进行计数):就是把值当成枚举,去分组统计个数
bottomk(后n条时序)topk(前n条时序)quantile(分位数):就是查找百分比点上的数,比如0.5就是在结果集中从低到高的中位数,0.6以此类推,它的值会比0.5高
语法
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
by/without
类似group by的概念
- by等于,通过某个或多个tag进行聚合
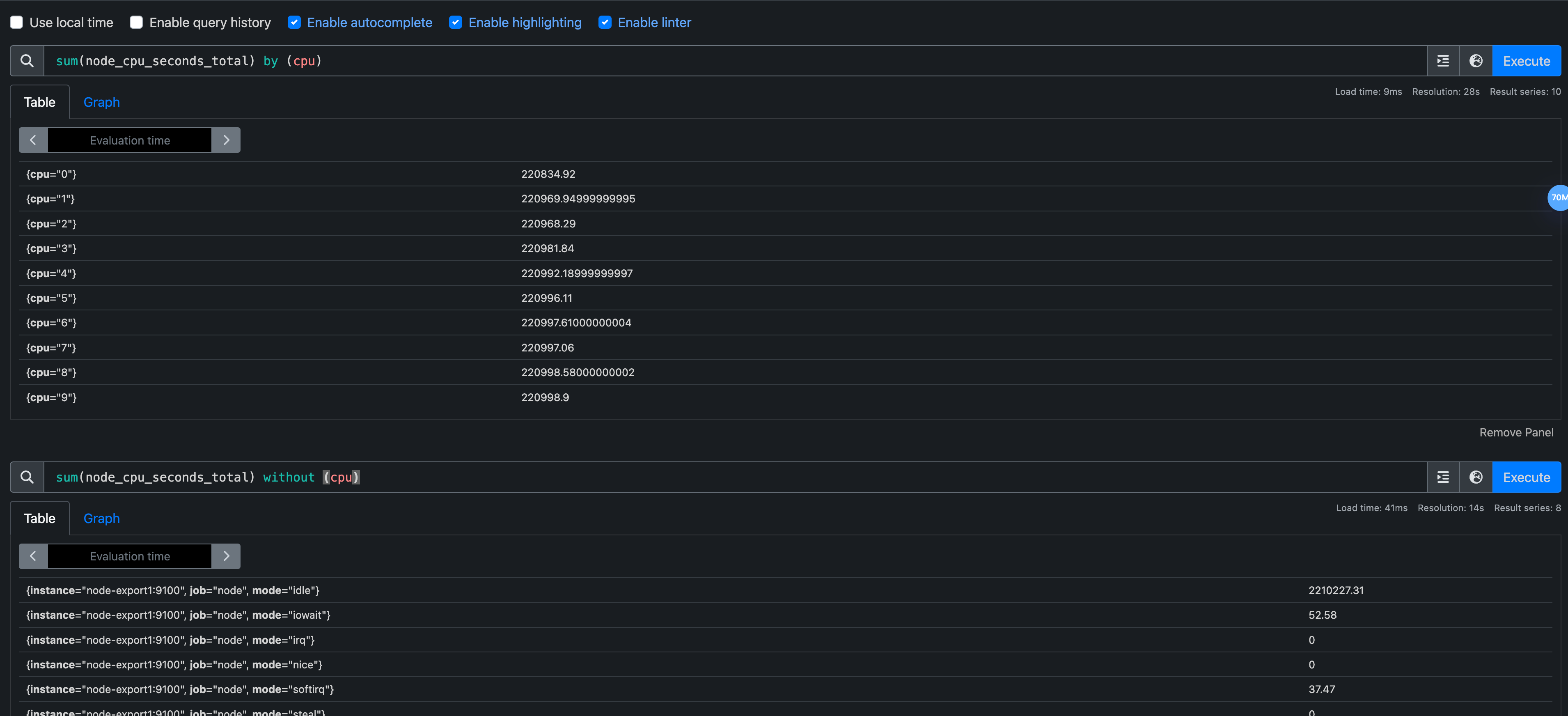
- without等于,反选的by,在这里without(cpu)等同于
by (instance,job,mode)
内置函数
increase
increase函数获取区间向量中的第一个后最后一个样本并返回其增长量
sum(increase(node_cpu_seconds_total{cpu = "0"}[2m])/120) by (mode)
这个例子,统计2分钟内cpu 0的使用率

首先得到区间向量的,第一和最后一个值,increase就是把首尾两个值相减

结果除以120,就得到了每秒的一个增长率,最终就得到这个结果,即每种mode下的cpu使用率

rate
rate函数可以直接计算区间向量v在时间窗口内平均增长速率
sum(rate(node_cpu_seconds_total{cpu = "0"}[2m])) by (mode)
可以得到和上面一样的结果

irate
作用和rate一样,但是可以感知到长尾问题(例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。),比rate更灵敏
predict_linear
predict_linear函数可以预测时间序列v在t秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。
predict_linear(node_filesystem_free_bytes[2h], 4 * 3600)
这个语句就是根据最近两小时的磁盘空间数据,预测接下来4小时后磁盘的状态,如果这个值小于阈值,那么就应该发出警告

告警
Alertmanager
 Alertmanager主要需要做到
Alertmanager主要需要做到
- 分组:大量告警同时发生时,只内聚触发一条告警,避免一次性接受大量的告警通知
- 抑制:指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
- 静默:静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
告警规则
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_Active_bytes)/node_memory_MemTotal_bytes > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
上面是一个典型的rules配置
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
在prometheus.yml中添加
rule_files:
- /etc/prometheus/rules/*.rules
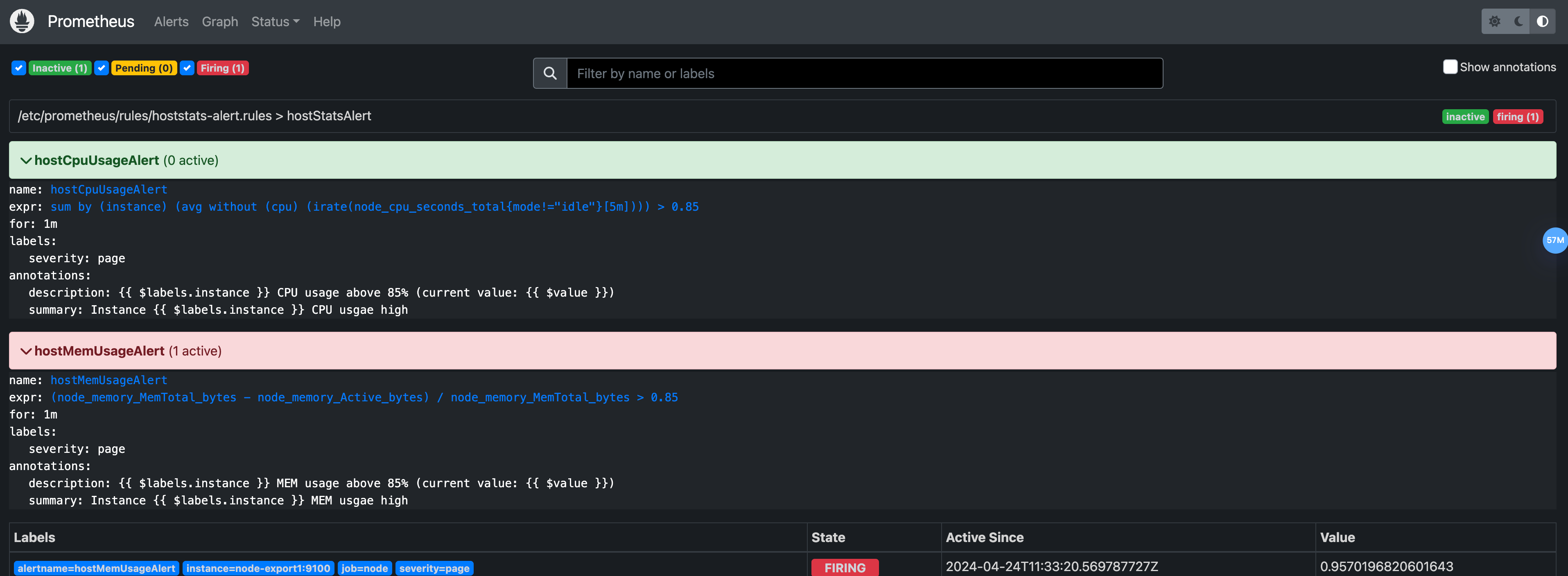
然后重启,就可以在http://localhost:9090/rules看到如下两条新的rule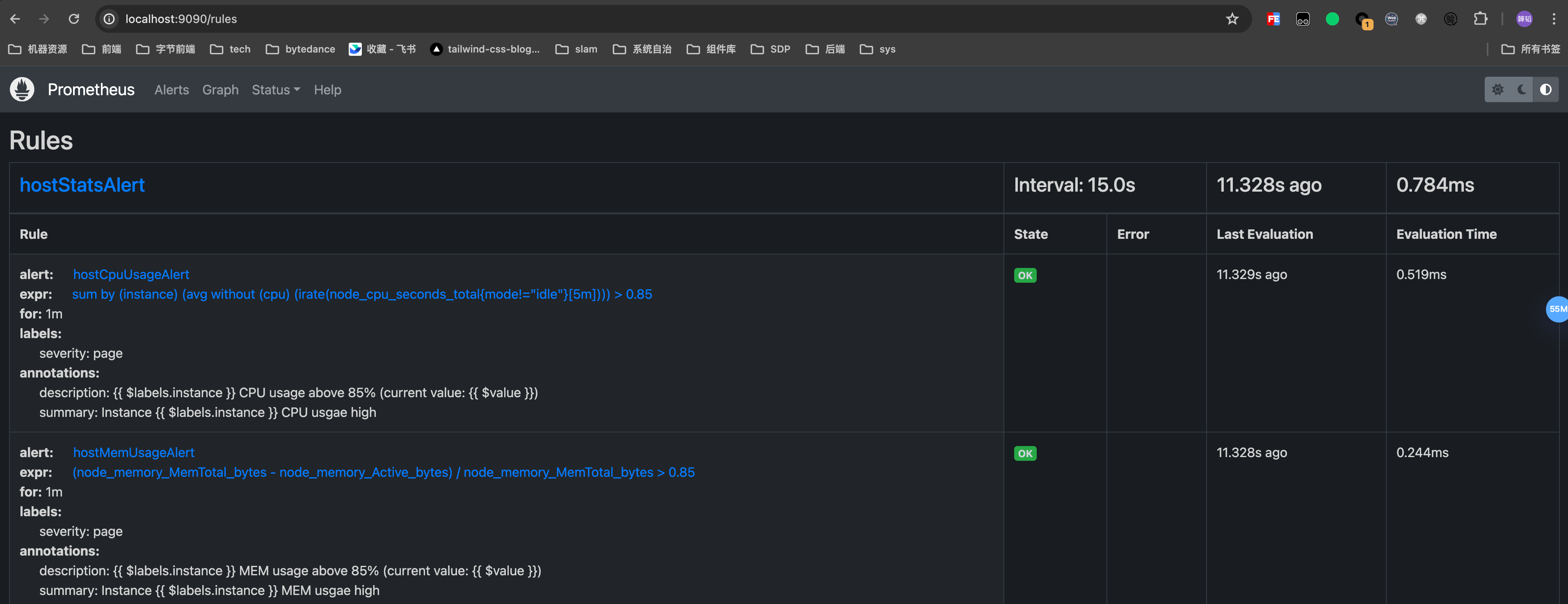
如果触发就能在Alerts里看到触发的信息