- Published on
GoLang-《100个GO语言典型错误》笔记
- Authors

- Name
- McDaddy(戣蓦)
# 1 意想不到的变量隐藏
下面这段代码中(可以正常编译),在if/else之后,最后打印出来的client是nil
func listing1() error {
var client *http.Client
if tracing {
client, err := createClientWithTracing()
if err != nil {
return err
}
log.Println(client)
} else {
client, err := createDefaultClient()
if err != nil {
return err
}
log.Println(client)
}
log.Println(client) // nil
return nil
}
明明前面的逻辑是有赋值的,但为什么最后是nil呢?
If/else中的:= 定义的是内部的client,和外部的client无关
在Go中,一个块中声明的变量名可以在它内部的块里面被重新声明,这被称为变量隐藏。内外虽然是同一个名字的变量,但是完全不相干,代码极端点,可以两者不同类型,也是不会报错的
func listing1() error {
var client *http.Client
if true {
client := "ssss"
fmt.Println(client)
}
fmt.Print(client)
return nil
}
怎么解决?
方法一: 定义一个临时变量,然后把它赋值给外部的这个变量
func listing2() error {
var client *http.Client
if true {
c, err := createClientWithTracing()
if err != nil {
return err
}
client = c
}
_ = client
return nil
}
方法二:用=替换:=,这样就不会有声明,而仅仅是赋值,这样就不会有变量隐藏的问题了
func listing3() error {
var client *http.Client
var err error
if true {
client, err = createClientWithTracing()
if err != nil {
return err
}
}
_ = client
return nil
}
# 3 滥用init函数
init函数是用于初始化应用程序状态的函数,它没有入参,也没有出参。它是在初始化包的时候被执行的,且不能被显式调用
它可能会带来几个问题
- 一个包可以定义多个init函数,执行的顺序是基于源文件字母顺序的,a.go的执行会早于b.go(两者同包),如有相互依赖是有风险的
- init的错误管理是有缺陷的,因为它不能返回任何东西,所以也就不能返回err,唯一handle错误的方式就是panic,如果是在一个lib里面写init,那它的调用方很有可能因为这个包而发生意料外的painc
- 不方便测试,如果写单测,有些初始化逻辑是不需要的,但是就无法跳过了
- 如果init函数要给什么变量赋值,那只能赋值给全局变量,但事实上全局变量太容易被篡改,所以不建议这么做
所以总之,我们还是尽量避免使用init函数
# 8 any意味着nothing
没有指定任何方法的接口类型称为空接口,即interface{}
Go 1.18开始,加入了any类型,也就是空接口的别名,所有interce 都可以被any替换
一旦使用any,变量就可以被赋各种类型的值,且不会编译报错。但这样也失去了Go静态语言的优势,我们应该能不用就不用
只有少数情况是可以使用的,比如Marshal方法,它无法预知入参会是什么类型的结构体,所以就是any
# 10 没有意识到类型嵌入可能存在的问题
如下代码,Bar在Foo中是一个嵌入的类型,我们可以从foo实例里面直接获得Baz变量
type Foo struct {
Bar
}
type Bar struct {
Baz int
}
func fooBar() {
foo := Foo{}
foo.Baz = 42
foo.Bar.Baz = 42 // 两者指向同一个变量
}
但这样可能会有些隐藏的问题
type InMem struct {
sync.Mutex
m map[string]int
}
func New() *InMem {
return &InMem{m: make(map[string]int)}
}
func (i *InMem) Get(key string) (int, bool) {
i.Lock()
v, contains := i.m[key]
i.Unlock()
return v, contains
}
上面这个例子,InMem这个类型,不想暴露map,同时想实现加锁,就把Mutex直接嵌入到结构体里。 这样看起来非常方便,但是如果外部在使用inMem的实例时,可以直接调用inMem.Lock() ,那这样是不是也很离谱?
所以一般情况下,我们只是把嵌入结构作为一种简化的语法糖(foo.Bar.Baz => foo.Baz),但这个的意义其实并不大
此外,如果被嵌入的结构里有了跟嵌入结构体中相同的成员名,那么这个语法糖也无效了
type Foo struct {
Bar
Baz string
}
type Bar struct {
Baz int
}
func fooBar() Foo {
foo := Foo{}
foo.Baz = "42"
foo.Bar.Baz = 42
return foo
}
# 17 使用八进制字面量会带来混淆
下面这段代码,结果并不是110,而是108
sum := 100 + 010
fmt.Println(sum)
因为在Go里,0开头的数字指代八进制整数,八进制的10就是十进制的8,此外0o10也是同样的效果
此外
二进制用 0b或者0B开头
十六进制用0x或者0X开头
我们可以随意在数字的中间加下划线,增加可读性比如 100_00_0_0
# 18 容易忽视的整数溢出
Go总共有10种整数类型,分别是int8/16/32/64 和 uint8/16/32/64, 外加int和uint
其中int和uint的长度取决于操作系统,在32位系统中就是32位,64位中就是64位
var count int32 = math.MaxInt32
count++
fmt.Print(count)
这段代码可以编译和执行,运行时也不会报错,但最终打印的结果是-2147483648。这就是整数溢出的结果。在Go中整数溢出是静默的,不会产生panic,所以在做操作时要非常小心
# 20 不了解切片的长度和容量
首先,在Go里面,为什么不直接称呼切片叫数组?在Go里,数组是指固定长度的数据结构,比如int[5] 就是一个数组,而切片相对于数组是变长的,可以动态增减
s := make([]int, 3, 6)
在这里,两个参数3是切片的长度,6是切片的容量,灰色的部分是内存已经分配了,但是没有被使用的部分
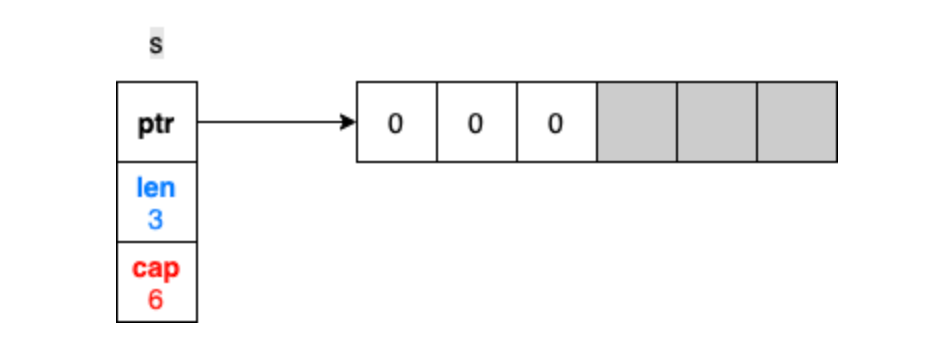
我们要读取切片内容只能在len的范围内,如果读s[4](即使此时还在分配内存的范围内),那就会报index out of range的err
如果当我们通过append新增元素超过cap时,Go就会创建一个新的数组,同时复制所有当前元素过去,新的数组的长度是原来的两倍
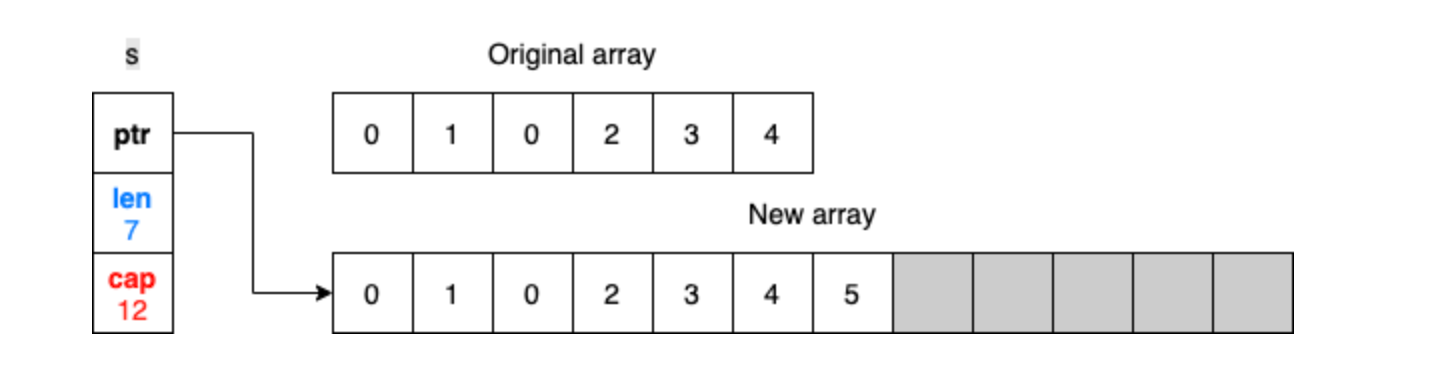
在Go中,切片小于等于1024时,每次扩容增加一倍,超过1024以后,每次扩容增加25%
而原来的数组,会在GC后被释放
切割append问题
s1 := make([]int, 3, 6) // [0 ,0, 0]
s2 := s1[1:3] // [0, 0]
s1[1] = 1 // [0, 1, 0]
fmt.Print(s2) // [1, 0]
s2 = append(s2, 2)
fmt.Print(s1) // [0, 1, 0]
fmt.Print(s2) // [1, 0, 2]
s1 = append(s1, 4)
fmt.Print(s1) // [0, 1, 0, 4]
fmt.Print(s2) // [1, 0, 4] 这个有没有超出预期?
运行上面的代码,虽然s2从s1上切出来了,但是它们各自的改动还是在影响着对方,下面简述下原因
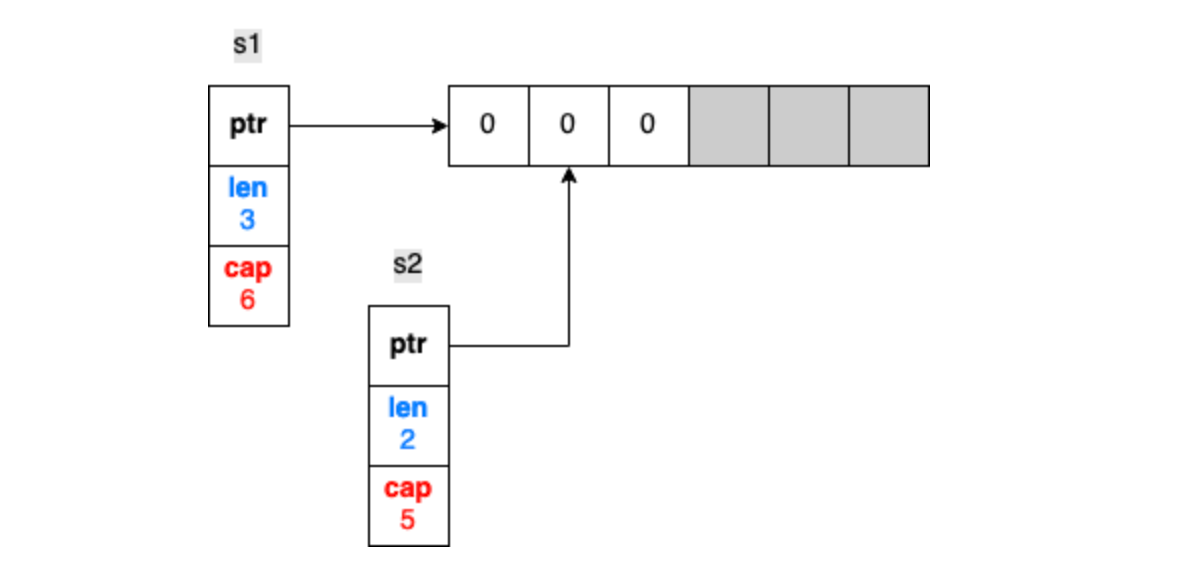
s2与s1共享一段数组,只是s2从第二位开始,同时容量比s1小1

所以s1改动的第二位其实也就是s2的第一位

同理,s2添加一位也是在同一个数组上操作, 但是,此时s1是读不到这个2的,因为它的长度还是3
最后s1添加了一个4后,s1的长度来到了4,而这个4也把刚刚s2添加的2给覆盖了
如果此时,我们再往s2里添加3个元素,s2就会扩容,从此s1和s2彻底无关

总之,切片的长度是切片中可用元素的数量,容量是切片底层数组中的数量,如果两者相等,代表底层数组满了,再往里添加元素就会把当前所有元素复制到一个新的数组里,同时切片指向新的数组
为了避免上面的不可预知问题,有两种方式来解决
- 使用copy来实现切片间的复制, 两者就没有引用上的关联,自然就没有上面的问题,但是它也有隐藏的问题,比如切片非常大时,复制就非常消耗性能, 还有一个问题就是copy只能从头开始复制,不能从中间复制
- 使用另一种切片语法
s[low:high:max],max的意义是生成的切片的容量等于max-low,在这个例子里
s1 := make([]int, 3, 6) // [0 ,0, 0]
s2 := s1[1:3:3] // [0, 0] 限定了s2的cap是2 (3-1)
s1[1] = 1 // [0, 1, 0]
fmt.Print(s2) // [1, 0]
s2 = append(s2, 2) // 此时s2已经和s1脱钩,因为s2已经超过他原本的cap
fmt.Print(s1) // [0, 1, 0]
fmt.Print(s2) // [1, 0, 2]
s1 = append(s1, 4)
fmt.Print(s1) // [0, 1, 0, 4]
fmt.Print(s2) // [1, 0, 2] 符合预期
但这种方法,如果在不调用append的情况下,还是有可能造成内存泄露风险(#25)
# 21 低效的切片初始化
func convertEmptySlice(foos []Foo) []Bar {
bars := make([]Bar, 0)
for _, foo := range foos {
bars = append(bars, fooToBar(foo))
}
return bars
}
这里例子初始化切片传了一个0值的长度(长度这个参数是必传的)且没有传容量。然后,使用append添加Bar元素。起初,bars是空的,因此添加第一个元素会分配一个大小为1的底层数组。每当底层数组被充满时,Go都会创建一个2倍于当前容量的新数组
在我们添加第3个元素、第5个元素、第9个元素时等,这个创建数据的逻辑都会重复。假设输入切片有1000个元素,该算法需要分配10个底层数组,并将1000多个元素从一个数组复制到另一个。这导致GC需要付出很多额外的工作来清理所有这些临时的底层数组。
解决这个问题,我们必须通过指定合适大小的长度或者容量来初始化
func convertGivenCapacity(foos []Foo) []Bar {
n := len(foos)
bars := make([]Bar, 0, n)
for _, foo := range foos {
bars = append(bars, fooToBar(foo))
}
return bars
}
如果我们不指定长度,指定容量。在内部Go预先分配了一个由n个元素组成的数组。因此,添加n个元素都会使用同一个底层数组,从而大幅减少分配数组的数量。
func convertGivenLength(foos []Foo) []Bar {
n := len(foos)
bars := make([]Bar, n)
for i, foo := range foos {
bars[i] = fooToBar(foo)
}
return bars
}
又或者不指定容量,只指定长度。 但这里要注意的是添加元素只能用下标来改变而不能用append,除非容量已经充满
经过测试100w量级的数据,后面两种的速度是不指定版本的3倍以上
同样的问题也会出现在map的初始化上,这里就不重复阐述了
# 22 空切片与nil切片
- 空切片:长度为0,值不为nil
- nil切片:类型是切片,长度为0,值为nil
func main() {
var s []string
log(1, s) // 1: empty=true nil=true
s = []string(nil)
log(2, s) // 2: empty=true nil=true
s = []string{}
log(3, s) // 3: empty=true nil=false
s = make([]string, 0)
log(4, s) // 4: empty=true nil=false
}
func log(i int, s []string) {
fmt.Printf("%d: empty=%t\tnil=%t\n", i, len(s) == 0, s == nil)
}
两者类型相同(后续能做的操作也相同比如append),主要区别是是否有资源分配,显然nil切片是不需要资源分配的
var s []string // 使用最广
s = []string(nil) // 几乎用不到,只要是语法中的快捷方式
s = []string{} // 用来初始化包含初始元素的切片
s = make([]string, 0) // 创建一个已知长度的切片
还要注意在encoding/json这种包的编码问题, 如果是nil切片,结果是null,而如果是空切片,结果是[]
最后如何判断一个切片是否为空,最好的办法不是判断切片是不是nil,而是去判断len(s)因为不管是nil切片还是空切片,len结果都是0,这样就不需要去做主动区分了
# 24 无法正确复制切片
如上提到,复制切片最好是使用copy,但copy可能也会有些常见错误
func bad() {
src := []int{0, 1, 2}
var dst []int
copy(dst, src)
fmt.Println(dst) // []
}
func correct() {
src := []int{0, 1, 2}
dst := make([]int, len(src))
copy(dst, src)
fmt.Println(dst) // [0 ,1, 2]
}
失败的原因是copy只会复制源和目标中长度的最小值,所以本例中最小值是nil切片的长度0,所以就没复制成功。(换句话说copy不会帮助我们扩展切片的长度)
如果不使用copy,还有一种更快捷的方式
src := []int{0, 1, 2}
dst := append([]int(nil), src...)
# 26 切片的内存泄露
下面这段代码, 原本foo数组占用的空间是1G,我们希望仅保留每个foo中的前两位,剩余的不需要,看看最终占据的内存空间
type Foo struct {
v []byte
}
func main() {
foos := make([]Foo, 1_000)
printAlloc()
for i := 0; i < len(foos); i++ {
foos[i] = Foo{
v: make([]byte, 1024*1024), // 1MB
}
}
printAlloc() // 1024130 KB
two := keepFirstTwoElementsOnly(foos)
runtime.GC()
printAlloc() // 1024132 KB
runtime.KeepAlive(two)
}
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
return foos[:2]
}
事实结果是,内存的消耗完全没有减少,原因是切片的长度len虽然是2,但是它的底层cap依然是1k,只要foo的引用存在(虽然只会访问前两位),那么就不会被GC掉
如何解决这个问题的办法有两个
- 使用copy方法,将方法改成如下,等于两个切片切断了联系
func keepFirstTwoElementsOnlyCopy(foos []Foo) []Foo {
res := make([]Foo, 2)
copy(res, foos)
return res
}
同时我们可能会想到完整切片表达式s[low:high:max],即写成foos[:2:2],但遗憾的是当前runtime.GC的实现并不会回收这段内存
- copy方法会强制把数组的cap改成2,如果还想保留1k的cap,那就只能手动把剩余的foo置空,同样能达到防止内存泄露的目的
func keepFirstTwoElementsOnlyMarkNil(foos []Foo) []Foo {
for i := 2; i < len(foos); i++ {
foos[i].v = nil
}
return foos[:2]
}
- 假如我们想保留的不是从头开始,那就只能老老实实把目标位的值复制出来
func keepFirstTwoElementsOnlyCopy(foos []Foo) []Foo {
res := make([]Foo, 2)
for i := 0; i < 2; i++ {
res[i].v = foos[i].v
}
return res
}
# 27 & 28 map的低效初始化和内存泄露
首先了解下map的底层实现原理,Go的map是基于哈希表的,这里简要介绍下哈希表
哈希表
又称为散列表,和二叉树、链表这一类一样。它是一种数据结构,设计出来用于存放数据。它的底层数据结构是一个数组
构建方式
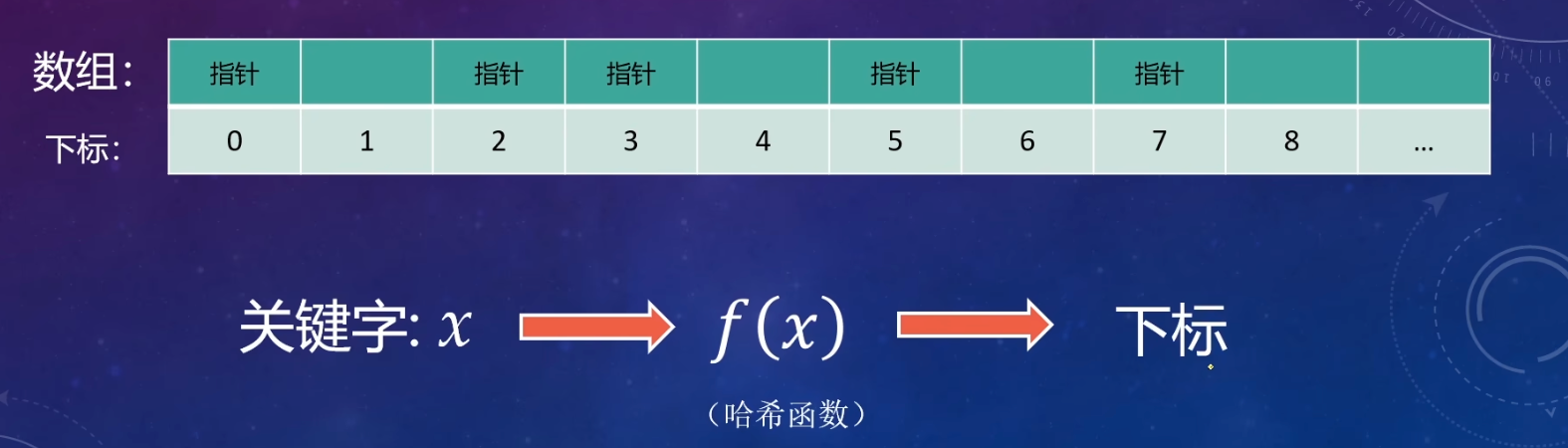
它的构建方式就是,先准备一个数组,需要添加元素时,将关键字(key)通过哈希函数获得其哈希值,然后通过运算得到对应数组里的下标,最后填入。 这里运算得到下标的方式一般有两种
取模法:比如数组是17位的,结果就是
hash值 % 17,确保一定落在数组下标范围内,其中数组的大小一般设置为质数,这样比较容易分布均匀(原因不太清楚)与运算:取值公式是
hash值 & (m - 1),这里要求数组大小必须是2的整数次幂,举个例子 Hash = 12345678, 数组长度为4(m -1 就是 011),结果就是101111000110000101001110 000000000000000000000011结果就是10,即2, 那么下标就是2
假设数组长度为5,那么结果就是
101111000110000101001110 000000000000000000000100结果是100,即4也就是最后一位,虽然也在范围内,但是[0, 3]前面这三位就永远不可能落入数据
在golang中,使用的是与运算的方法
冲突解决
我们知道如果只有4位长度地址,一旦超过4个不用key那必然会发生下标冲突,这个时候就会发生冲突,hash表有两种解决冲突的方法
- 开放地址:本质意思就是如果遇到冲突就往下一个地址寻找,至于下一个位置在哪里有多种计算方法,最终直到找到空位为止,这种方法比较复杂,也不大好理解
- 链表式解决:就是在发生冲突的时候,给这个地址的元素加一个next指针,指向这个新的元素,如果这个位置一直冲突,那就一直next下去。golang采用的就是这种解决方式
哈希表满了怎么办?
理论上讲,如果用链表解决冲突是不会存在哈希表满的情况的,只有开放地址会有这个问题。
但是如果链表的next非常多,那么查询一个key的复杂度就是O(p), p就是链表的长度,在大数据量的情况下性能就不能维持了
所以一般到达一定存储量之后,哈希表就会扩容,扩容后的容量一般是旧表的2倍或以上,然后把旧表的数据迁移到新表里去,这里如何把旧表迁移新表就涉及了重新哈希,就是说把这些数据按照上面说的构建方式导入到新表中
Golang的实现
回到Golang的map实现,在Golang里,map类型的本质其实是一个指针,指向hmap结构体
type hmap struct {
count int // 键值对的数量
flags uint8
B uint8 // 哈希桶数组的大小指数 (2^B)
noverflow uint16 // 溢出桶的数量
hash0 uint32
buckets unsafe.Pointer // 指向哈希桶数组的指针
oldbuckets unsafe.Pointer // 扩展期间指向旧的哈希桶数组
nevacuate uintptr // 扩展期间的迁移进度
extra *mapextra // 额外的哈希桶和溢出桶指针
}
这个哈希表中的每个元素被称为桶(bucket),每个桶里包含8个键值对,单个bucket的存储结构大致如下
type bmap struct {
tophash [bucketCnt]uint8 // 哈希值的高位部分,用于快速比较
keys [bucketCnt]keytype // 存储键的数组
values [bucketCnt]valuetype // 存储值的数组
overflow *bmap // 指向溢出桶的指针
}
// bucketCnt 是常数,默认值为 8,因此每个桶可以存储 8 个键值对。
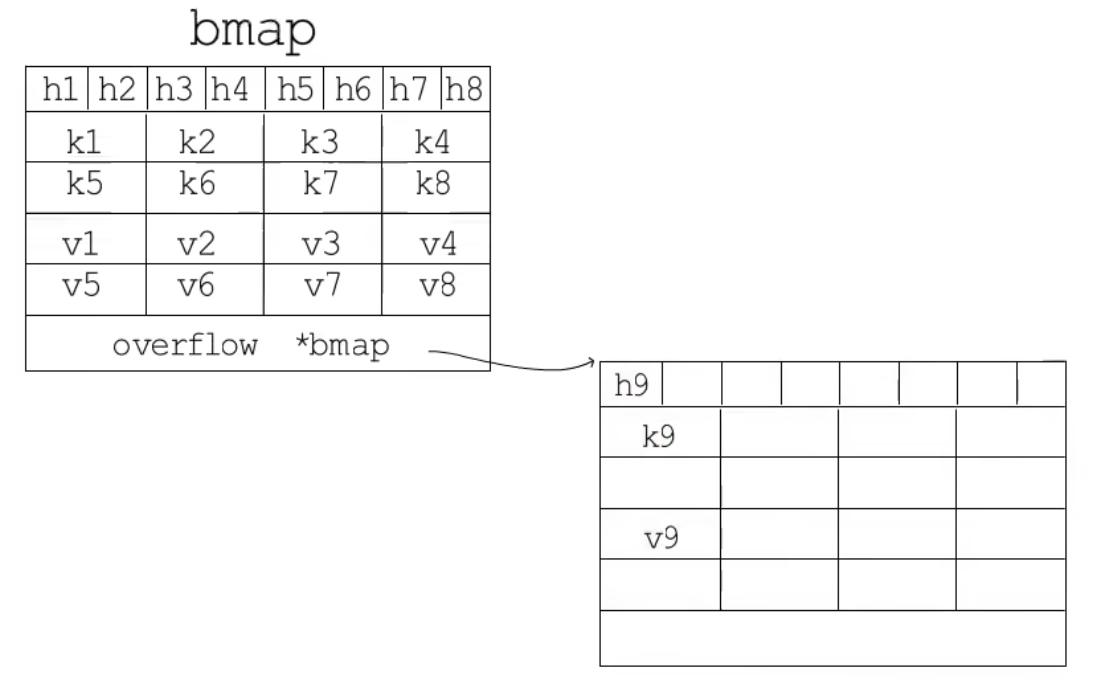
开头存8个键的hash值高8位,然后按顺序存储8个key和8个value,最后有个overflow部分,存的是溢出桶(即上面说的next),溢出桶的结构和常规桶一样
我们假设在64位的机器上,看一个bmap占多少空间
1. tophash 数组
每个 bucket 存储 8 个 uint8 类型的 tophash,总共 8 字节。
2. keys 数组
假设键为 8 字节(例如 int64 类型),则 keys 数组为 8 * 8 = 64 字节。
3. values 数组
假设值为 8 字节(例如 int64 类型),则 values 数组为 8 * 8 = 64 字节。
4. overflow 指针
一个指针的大小在 64 位系统中是 8 字节,在 32 位系统中是 4 字节。这里假设在 64 位系统中,即 8 字节。
总共加起来就是144字节,其中key和value的空间要看具体类型,一个bmap一旦初始化,大小就固定了,即使只存一个元素
现在看下如何实现渐进式扩容,目的就是尽量减少服务中的抖动
- 当需要扩容时,会准备好与当前长度两倍的新空间,然后把buckets的指针指向新空间,oldbuckets指向老的空间
- nevacuate字段用记录迁移进度,在迁移的过程中如果有对数据的访问,就会通过这个字段来判断,这个hash目前是在老空间还是新空间,然后再去找
- 在迁移中仍然使用位运算的方式,把元素分配到新的桶里
那什么情况下需要扩容呢?具体规则是
大于负载因子,即Golang内定的6.5,当
总元素数量/桶的数量(count/(2^B))即平均每个桶(不包括溢出桶)装的元素数量大于6.5时触发。此时触发的是翻倍扩容溢出桶太多,具体条件是
B <= 15 && noverflow >= 2^B (2^15 =32,768)B > 15 && noverflow >= 2^15
那什么情况会发生这种,未触发负载因子扩容,但溢出桶过多的情况呢? 一般就是指有大量删除的场景,此时触发的是等量扩容,即B值不变,重新排列一遍这些元素,从而减少溢出桶的数量,达到减少内存的目的
回到Golang低效初始化的问题,因为当初始化一个空的map时,B的值还是0,每次插入到需要翻倍扩容的时候,都需要发生一次整体的复制迁移,所以性能肯定会受影响
m := make(map[int]struct{}) // 空的初始化
m := make(map[int]struct{}, 1_000_000) // 带初始大小的初始化
经过测试,同样插入100w个元素,后者的速度会快60%
接下来看map内存泄漏的问题,假设我们想向一个map中插入100w个元素,再删除所有元素并GC,此时这个map占用多少空间?
// Init
n := 1_000_000
m := make(map[int][128]byte)
printAlloc() // 0 MB
// Add elements
for i := 0; i < n; i++ {
m[i] = randBytes()
}
printAlloc() // 461 MB
// Remove elements
for i := 0; i < n; i++ {
delete(m, i)
}
// End
runtime.GC()
printAlloc() // 293 MB
runtime.KeepAlive(m)
事实结果是即使删除了所有元素,map仍然要占用293MB这么大的空间,这里的原因是在Golang设计中,B这个数字,它只会增加不会减小,当需要存储100w数据时,B值大约是18,而情况元素之后,B值不会变化,依然保留了2的18次方的桶个数
这就会导致一些实际问题,比如业务高峰过后,内存使用量并不会相应明显下降。此时我们只能通过重启服务才能释放掉这部分内存
这里一个简单的解决办法,就是尽量把对象类型的值写成引用类型

这里还要注意一点:Golang它自己本身也是有些优化策略的,比如任何key和value如果本身占用的体积大于128字节,那么就会自动把它作为一个指针存储,而不需要程序员来设置。
就上面的例子而言,如果把所有128替换成129, 结果就是添加完100w后体积为197MB,删除后38MB
# 29 比较值时发生的错误
在Java里面两个对象(除了原生类型)用 == 来比较比的其实是内存地址,这一点在JavaScript也是一样的,但是在Golang是有区别的
首先切片之前是不能用==来对比的,下面这段代码编译就会报错
a1 := []string{"a"}
a2 := []string{"a"}
fmt.Println(a1 == a2) // invalid operation: a1 == a2 (slice can only be compared to nil)
同理map也是一样的
Golang中可对比的类型包括
- 布尔值:比较两个布尔值是否相等。
- 数字(int、float以及complex类型):比较两个数字是否相等。
- 字符串:比较两个字符串是否相等。
- channel:比较两个channel是否由同一调用创建或者两者是否都为nil。
- 接口:比较两个接口是否具有相同的动态类型和相等的动态值,或者两者是否都为nil。
- 指针:比较两个指针在内存中指向的是否是相同的值,或者两者是否都为nil。
- 结构体和数组:比较它们是否由相同类型组成
如果我们用any类型来绕过编译检查,那么可能会引起运行时错误
var cust31 any = customer2{id: "x", operations: []float64{1.}}
var cust32 any = customer2{id: "x", operations: []float64{1.}}
fmt.Println(cust31 == cust32) // panic: runtime error: comparing uncomparalble type main.customer
这里有两种方式可以解决
reflect.DeepEqual(a, b),通过反射对比,相当于是把结构体层层剖开,直到原始类型然后做比较。但需要注意两点
- 它区分nil和空切片
- 它的性能很辣鸡,比==慢100倍以上
实现一个equal方法,类似这样
func (a customer2) equal(b customer2) bool { if a.id != b.id { return false } if len(a.operations) != len(b.operations) { return false } for i := 0; i < len(a.operations); i++ { if a.operations[i] != b.operations[i] { return false } } // 上面的一整段可以用 slices.equal(a.operations, b.operations) 替代 return true }
# 30 忽视在range循环中元素被复制的事实
看下面这段代码的输出
accounts := []account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
fmt.Println(accounts)
不熟悉Golang的可能会觉得是 [1100 1200 1300],但实际上是 [100 200 300]。 结果就是这个循环对原始的切片没有产生任何影响
原因是在Go语言中,一切赋值都是一个拷贝,所以这里的加法是发生在account的拷贝上,所以不会产生效果。要解决这个问题有两种方式
下标访问
for i := range accounts { accounts[i].balance += 1000 } // 或者 for i := 0; i < len(accounts); i++ { accounts[i].balance += 1000 }把类型改成指针
[]*account{},这样拷贝的只是一个指针,而指针的拷贝依然指向同一个结构体,所以是生效的
# 31 忽视range循环中参数是如何求值的
考虑如下两段代码,分别会正常结束还是死循环
s1 := []int{0, 1, 2}
for range s1 {
s1 = append(s1, 10)
}
s2 := []int{0, 1, 2}
for i := 0; i < len(s2); i++ {
s2 = append(s2, 10)
}
答案是s1会正常结束,s2会死循环
原因是对range循环来说,表达式求值仅发生一次,后面不管怎么更改,表达式不再触发,同时表达式的结果是一个拷贝(非指针)
s1 := []int{0, 1, 2}
for s := range s1 {
s1[0] = 20
s1[1] = 20
fmt.Println(s) // 不会打印出20
s1 = append(s1, 10)
}
相反s2的情况每次循环是会重新计算的,所以最终会死循环
# 32 忽视在range循环中使用指针元素的影响
先来一个无关主题的大大的迷惑点
type LargeStruct struct {
foo string
}
lMap := make(map[string]LargeStruct, 0)
lMap["1"] = LargeStruct{foo: "1"}
lMap["2"] = LargeStruct{foo: "2"}
lMap["2"].foo = "bar" // cannot assign to struct field lMap["2"].foo in map compiler
上面这段代码是无法通过编译的
type Inner struct {
C int
}
type Outer struct {
B Inner
}
func main() {
a := Outer{
B: Inner{C: 42},
}
fmt.Println(a.B.C) // 输出 42
// 这样修改将不会影响原有值
// b := a.B
// b.C = 100
a.B.C = 100
fmt.Println(a.B.C) // 100
}
而这段代码是符合预期的。 原因是map的实现是特殊的
在直接的链式调用中a.B得到的是实例本身,所以可以直接去改C,如果我们断开链式,用b := a.B得到的就是副本
而在map中,map[key]这个语法返回的永远是副本,不管是链式调用还是断开调用,所以解决这个问题的方法,只有把map中的类型改成指针,或者分步骤曲线救国
v := lMap["2"]
v.foo = "bar"
lMap["2"] = v
回到主题,下面这段代码,最终这个map里会存什么元素?
s := Store{
m: make(map[string]*Customer),
}
s.storeCustomers([]Customer{
{ID: "1", Balance: 10},
{ID: "2", Balance: -10},
{ID: "3", Balance: 0},
})
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
fmt.Printf("%p\n", &customer)
s.m[customer.ID] = &customer
}
}
答案是存了3个重复的{ID: "3", Balance: 0},原因是当使用range循环迭代一个数据结构时,必须记住,所有的值都被赋给一个具有唯一地址的唯一变量。
也就是说在这段语法中for _, customer := range customers customer在多次循环中,都是维持了同一个地址,只是在三次循环中分别在这个地址上存了指向不同元素的指针,对map来说三次赋值都是同一个内存地址
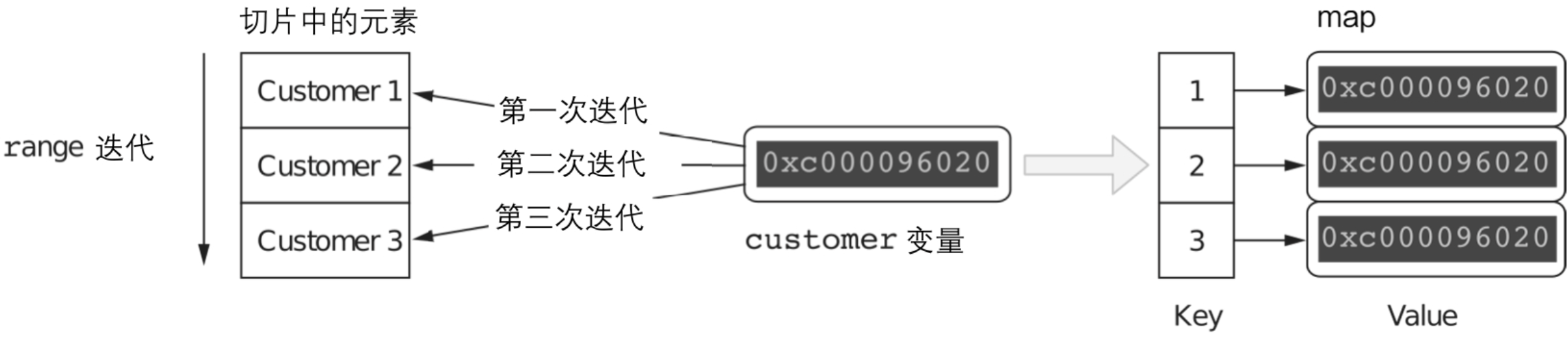
要解决这个问题,只能用以下的两种方式
// 设置一个临时变量,这个变量是有自己独立唯一的地址的
func (s *Store) storeCustomers2(customers []Customer) {
for _, customer := range customers {
current := customer
s.m[current.ID] = ¤t
}
}
// 把真实的元素的地址赋值过去
func (s *Store) storeCustomers3(customers []Customer) {
for i := range customers {
s.m[customers[i].ID] = &customers[i]
}
}
# 33 在map迭代过程中做出错误假设
在使用map时,要注意不能有下面这些假设
- 数据是按键排序的 (对一个map遍历打印key,每次的结果都可能不同)
- 保持插入顺序 (同上)
- 确定的迭代顺序 (同上)
- 在迭代的同时添加能对后来产生影响的键值对
m := map[int]bool{
0: true,
1: false,
2: true,
}
for k, v := range m {
if v {
m[10+k] = true
}
}
fmt.Println(m)
最后这点比较迷惑的,结果是不稳定的 
就是说我们不知道在遍历中添加map元素会不会影响循环次数,影响几次,但确定是不会死循环的,而这个行为是go作者故意的行为,就是为了让开发者不要有上面的假设, 如果非要这么玩,就需要先做下拷贝
注意这个影响循环次数的问题仅针对map,切片的循环类似操作是不会受到影响的
P.S. 同样的逻辑在JavaScript里面是会死循环的
let myMap = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three']
]);
myMap.forEach((value, key) => {
console.log(key, value);
myMap.set(key + 3, value + ' plus');
});
console.log('Final map:', myMap);
# 34 错误使用break/continue
基本原则:break语句终止最里面的for、switch或select语句 (continue同理)
所以下面这段还是会把5个数字打印完的
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break
}
}
如果非要跨层级break,那就要写成下面这种标签的形式
loop:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break loop
}
}