- Published on
GraphQL快速入门
- Authors

- Name
- McDaddy(戣蓦)
什么是GraphQL?
我们来看看官方文档是如何定义的
GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时(类型系统由你的数据定义)。GraphQL 并没有和任何特定数据库或者存储引擎绑定,而是依靠你现有的代码和数据支撑。
几个关键词
API的查询语言:GraphQL的目标是成为API的一个实现形式,即后端生产一个Graphql的服务作为API接口,前端调用此服务获取API数据或修改数据
基于类型系统:GraphQL的本质是实现一个Schema,而这个Schema与我们代码里的关系模型是一一对应的
没有和任何特定数据库或者存储引擎绑定: 它和底层用哪种数据存储方式无关,不论用哪种数据库,都可以通过GraphQL来实现API
GraphQL和RESTFUL API有什么关系
在我们的概念里面API的形式主要就是Restful API,但其实大多数人对他的理解都是不到位的。 我更愿意称之为基于HTTP Method的API实现方法。
因为现实中,我们只是比较粗糙得把请求目的和HTTP Method一一对应,比如创建对象就用Post,获取数据就用Get,修改数据用Put,删除数据用Delete。至于uri怎么命名,参数放在Query还是Path,数据的类型等等都是模糊的,换句话说,即使是一个完全不了解Restful的后端开发,也可以开发出供前后端正常使用的API,而当问起采用什么规范,依然回答Restful ^_^
所以说Restful归根结底是一个规范,它其实没有任何强制力,它的好处是易于上手(无所谓你使用的后端语言与服务框架),但是实际达成的效果是非常有限的
而GraphQL它并不是一个规范,可以理解为是一种API实现技术。使用它必须使用限定的框架、限定的语法,如果不遵守它那连代码都运行不起来,从根源上改变了API的实现形式。
接下来我们直观的感受下GraphQL的能力
GraphQL案例
这里我们就以GitHub作为案例用来演示,大家知道GitHub是对外暴露OPEN API的,即所有开发者都可以在被授权的条件下调用它暴露的API。
在22年以前,GitHub采用的就是传统的Restful API,以后REST API被停止维护,取而代之的就是GraphQL API
我们可以打开 Explorer 进行测试,通过授权认证后,我们可能看到如下的一个可交互的查询界面

查询仓库Star数
以React仓库为例,把下面的语句贴到查询语句编辑区
{
repository(owner: "facebook", name: "react") {
stargazers {
totalCount,
}
}
}

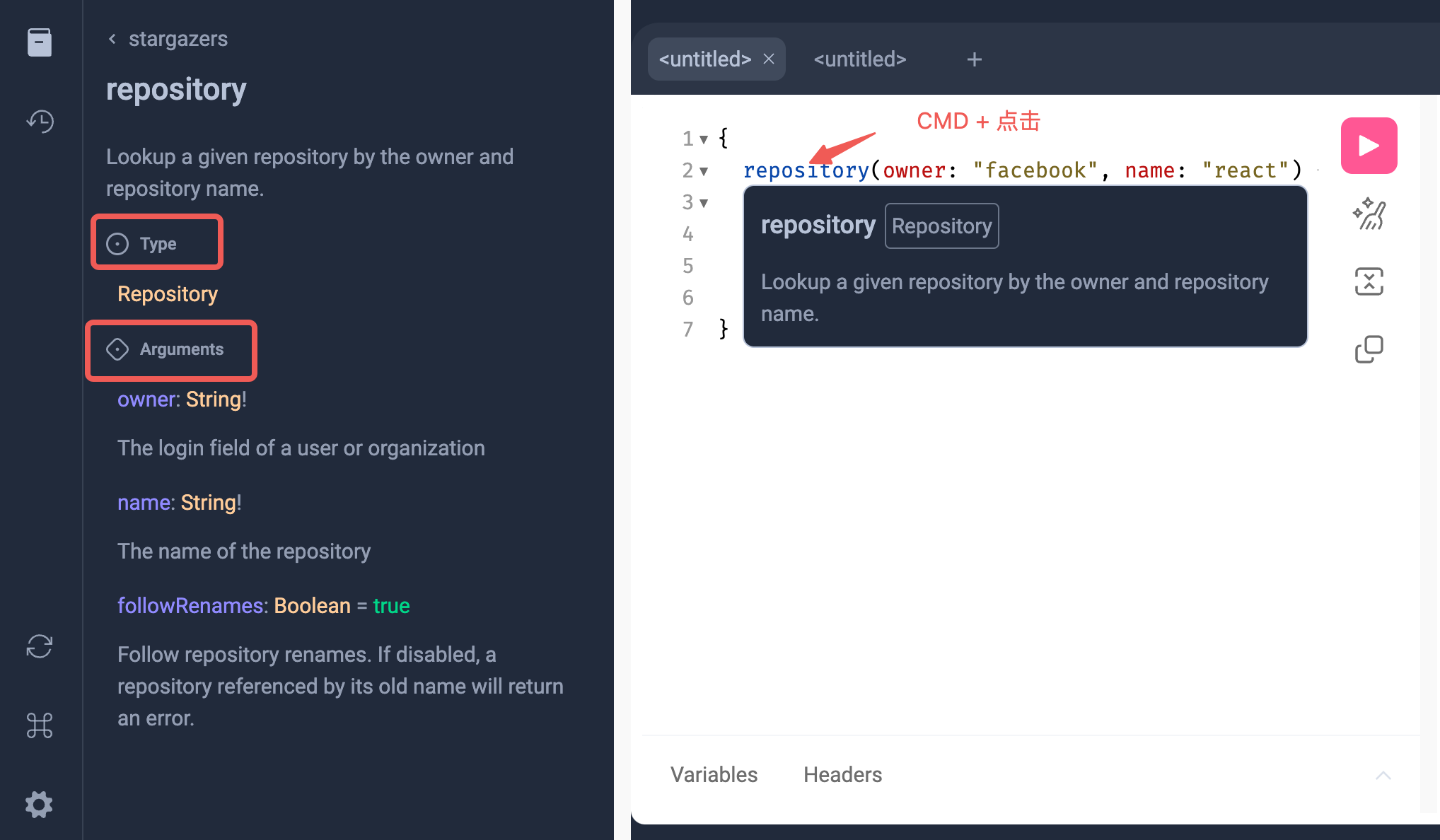
查看类型定义
在上面例子里,在编辑区找到任意一个属性名,通过CMD + 单击就可以在左侧得到对应的文档信息,比如类型、参数、默认值、字段类型等等。可以说是一个非常完备,且可以交互的API文档
获取前十条Issue列表
{
repository(owner: "facebook", name: "react") {
issues(first: 10, states: [OPEN], orderBy: {field: CREATED_AT, direction: DESC}) {
nodes {
title
state
updatedAt
}
}
}
}
这里涉及几个知识点
传参:只要是提供Arguments的对象都是可以进行传参的,比如owner可以传仓库所有者的名字,name是具体仓库名
类型:Graphql的类型主要分为三种
一种是标量类型
Scalar Types,我们直接理解为我们各种语言中的原生类型,这里只有5种类型Int:有符号 32 位整数。Float:有符号双精度浮点值。String:UTF‐8 字符序列。Boolean:true或者false。ID:ID 标量类型表示一个唯一标识符,通常用以重新获取对象或者作为缓存中的键。ID 类型使用和 String 一样的方式序列化;然而将其定义为 ID 意味着并不需要人类可读型。
这些类型就可以视为GraphQL里面最底层类型
第二种是枚举类型
Enumeration Types,和我们编程语言中的意义相同enum OrderDirection { ASC DESC }对象与列表类型,就是我们熟悉的对象
在上面的查询中我们可以注意到,每次输出的结果是不能以对象作为结果输出的,必须至少显式声明一个标量类型字段,才能完成输出
CRUD操作
除了查询数据,GraphQL也是支持修改数据的,只是查询是它的默认操作,一般可以省略,而修改数据必须显式声明
创建仓库
mutation {
createRepository(
input: {name: "test-graphql", visibility: PUBLIC, description: "this is a graphQL test"}
) {
repository {
url
}
}
}
修改仓库
mutation {
updateRepository(input: {
repositoryId: "R_kgDOK6-Nhw"
description: "let me try it"
}){
repository{
url
}
}
}
创建Issue
mutation {
createIssue(input: {
title: "测试一下2"
repositoryId: "R_kgDOK6-Nhw"
body: "<div>Test</div>"
}){
issue{
url
}
}
}
删除Issue
# 先查出Issue ID
query {
repository(owner: "McDaddy", name: "test-graphql") {
issues(first: 1) {
nodes{
id,
title
}
}
}
}
mutation {
deleteIssue(input: { issueId: "I_kwDOK6-Nh8558kUw"}){
repository{
url
}
}
}
几个知识点:
语法:虽然看起来就是在拼结构体,但是语法上是有要求的
- 字符串只能用双引号,单引号会报错
- 行与行之间不需要有分号或者逗号
非空:如果我们在任何类型的后面看到一个感叹号,表示这个类型它不能为空
强制返回:虽然这种创建修改类的API,前端一般可能不在乎返回(只要不报错),但是在Graphql它是强制需要你去指定返回的数据结构的
GraphQL解决了什么
这里我们还是以GitHub作为例子
仅获取所需的数据
有些后端非常喜欢把整个数据不经过过滤直接返回给前端,美其名曰为将来做准备。其实这样的行为是前端非常不耻的操作,会对前端调试造成非常大的噪声,同时也占用了不必要的带宽。
但实际情况,确实会经常出现需要添字段的场景,后端为了多吐一个字段还要额外修改代码,也确实有点没意义
以GitHub获取组织成员的接口为例,REST会返回所有对象中的字段
curl -v https://api.github.com/orgs/:org/members
而Graphql就可以做到精确获取,比如我只想得到成员的名字和头像
query {
organization(login:"github") {
membersWithRole(first: 100) {
edges {
node {
name
avatarUrl
}
}
}
}
}
嵌套查询
我们在实际场景中使用REST API经常会碰到N + 1查询的问题,以GitHub为例
curl -v https://api.github.com/repos/:owner/:repo/pulls/:number # 获取某个Pull Request
curl -v https://api.github.com/repos/:owner/:repo/pulls/:number/commits # 获取此PR的commits
curl -v https://api.github.com/repos/:owner/:repo/issues/:number/comments # 获取此PR的comments
curl -v https://api.github.com/repos/:owner/:repo/pulls/:number/reviews # 获取此PR的reviews
其中的1指的就是某对象的实例,N就是与之相关联的各个数据,这些数据都不存在对象的本身,而是通过外键关联。
为了得到这些完整的信息,必须发起多次查询
这里说明下,为什么GitHub不提供一个包含所有数据的API,原因就是我们常说的指责单一化。每个API都有自己明确的职责,且粒度尽量小,这样是最好控制与扩展的API设计模式
而使用GraphQL接口就可以合成一个请求
{
repository(owner: "octocat", name: "Hello-World") {
pullRequest(number: 1) {
commits(first: 10) {
edges {
node {
commit {
oid
message
}
}
}
}
comments(first: 10) {
edges {
node {
body
author {
login
}
}
}
}
reviews(first: 10) {
edges {
node {
state
}
}
}
}
}
}
强类型化
我们在做前后端API对齐的时候,免不了需要借助工具,低级一些的用文档,高阶一点的用类似BAM、Apifox之类的工具来定义接口
这里定义的重点就是接口的入参和返回的结构体,比如
- 一个对象里有几个字段
- 哪些可以为空,哪些不能为空
- 类型到底是string还是int
- 如果是枚举,有没有给出枚举值(别和普通原生类型弄混)
- 。。。
而这些工作都是需要前后端默契协作,有责任心的情况下才能做得好
那么如上所见,GraphQL是自带类型,如果后端是用GraphQL实现的接口,那么前端就自动可以获取到所有的对应类型。甚至可以得到一个自动生成的接口文档,如果后端改变了变量类型,前端代码也能自动收到报错信息(原理就是前端会读取后端产生的schema),然后进行调整
这种实现就无形中把前后端之间那堵数据结构隐形的墙拆除了,前端也可以非常直观地得到后端的数据结构
我们甚至可以通过一个网站来查看整个API的关系图 graphql-voyager
所以看到这里,我们应该可以理解,为什么叫做Graph QL了吧?
GraphQL的实际使用方法
上面我们演示的都是在一个PlayGround中进行的,那么在实际开发中是如何使用GraphQL呢
这边就要说到大名鼎鼎的Apollo GraphQL,它可以理解为在原生GraphQL之上做的一套封装,这个封装既提供了前端的client库,也提供了后端实现的server库,但都是针对node.js的。这是目前最火的GraphQL搭建方法
如果是GoLang的话可以使用 graphql-go
如果是Java的话可以使用 graphql-java
同时,我们要知道GraphQL肯定不是超脱于HTTP的存在,GraphQL请求的本质依然是HTTP,它的URI永远是不变的,即所谓的单一End Point,所有请求都是同一个URL,且只允许POST请求

而它的请求Body,就是我们写的query或者mutation语句

具体的实操,这篇就不展开了,将来有机会再分享
GraphQL的劣势
- 上手成本高,不像Rest那样易上手,更适合全栈开发团队
- 本身无法做鉴权,需要应用配合
- 对已经成规模的项目,迁移成本还是比较高的,可以考虑一些业界成熟方案,比如 Hasura
- 它并不是银弹,并不能解决所有API相关的所有问题