- Published on
国际化优化的思考与实践
- Authors

- Name
- McDaddy(戣蓦)
背景
国际化是每个需求迭代中一道繁琐但又必须要做的工序,没有任何技术含量,但做起来又感觉非常麻烦,这里列举一下当前我认为的痛点
- 步骤繁琐,目前正常情况下一般需要7步才能完成一个国际化过程
- 将需要国际化的中文用i18n.d包裹起来
- 跑 npm run extract, 此时temp-zh-words.json就会将待翻译的语句抽取出来
- 人工或跑 npm run translate, 通过谷歌翻译自动翻译抽取出来的中文, 翻译结束后在temp-zh-words.json中仔细检查翻译是否符合预期
- 再次跑 npm run extract, 此时会自动将翻译好的英文回填到原来的位置,且将.d改为.t
- 在所有翻译出来的英文前加上所需的namespace
- 跑 npm run locale,会自动将翻译好的内容集合到zh.json和en.json。记得检查有漏翻的情况
- 恢复temp-zh-words.json为空文件
- 无法复用之前已经翻译过的内容,比如这次要翻译的是“确定”,如果不想走上面的流程,就需要自行在zh.json中找到”确定“对应的单词和namespace然后手动拼到文件中。
- 如果一个词组,比如”数据模型字段“在一个模块中出现N多次,当产品要求把文案改成”关联模型字段“时,就需要把所有出现的地方都统一改一遍,费事且容易漏改出错
- 由于引入国际化,文案都变成了英文,改起代码来总觉得不直观,找一个文案要先找zh.json的中文,再搜一遍对应的英文,才能找到代码位置,有的时候英文是个比较短的常用词,比如model, 这词在项目中有几百次出现,但中文是有限多个的, 这样就很难定位了。
- 担心长句子因为符号折行,出现NOT_TRANSLATED
解决思路
Q:如何减少操作步骤?或者通过一个命令将之前所有的步骤打通
A:可以利用inquirer这个cli交互库,将所有步骤串联起来,需要使用者人工操作的步骤可以按需暂停。
Q:如何能利用之前翻译过的内容,不做重复劳动?
A:每次检查要翻译的内容都区分为翻译过的内容和从未被翻译过的内容,如果翻译过的内容不符合预期可以再重新移到未翻译的文件中,如果符合预期那么就会自动填充,不用重新翻译。
Q:如何在代码中统一管理翻译后的结果,当文案变更时不需要多处修改
A:可以尝试自动生成一个常量对象,记录所有翻译后的结果,代码中用常量的形式引用翻译后的文案,然后将常量维护在一个公共config文件中
Q:如何让国际化之后的代码也能尽量显示直观的中文,搜索文案时能快速定位?
A:可以尝试把中文也写在上面的常量对象中,利用jsDoc在代码中快速获得对应中文
Q:如何避免长句的翻译出现折行无法正常生成locale文件的情况?
A:以我个人经验,会造成这种情况的符号主要是点和冒号,可以在翻译脚本中强制替换成.和:来解决
方案流程
- 首先还是需要我们和以前一样手动把要翻译的中文用
i18n.d包裹起来 - 使用命令
npm run i18n开始执行国际化 - 脚本会将已翻译和未翻译的内容分别写在
temp-translated-words.json和temp-zh-words.json
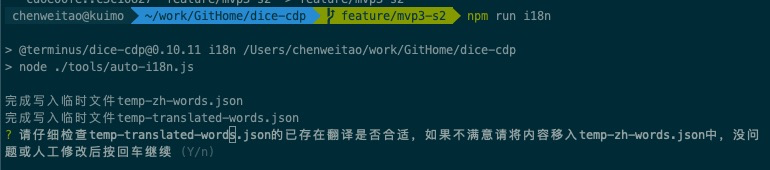
- 检查已翻译的内容是否符合预期,文件结构如下,如果觉得老的翻译不是想要的,就把这段key的值置空,然后粘贴到
temp-zh-words.json中去。
{
"模型名称": "cdp:model name"
}
- 按回车后,如果有未翻译的内容就会自动开始谷歌翻译,完成后需要人肉检查结果是否合理,不合理就手动改

- 按回车后,为这次翻译的内容指定一个namespace
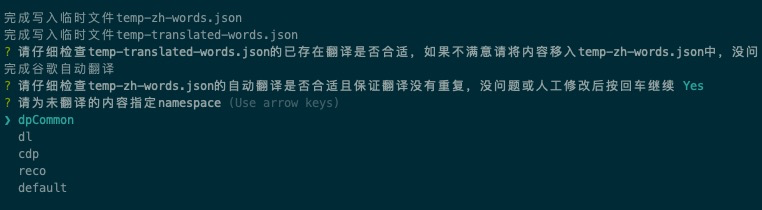
- 选择是否要生成I18N的常量片段,
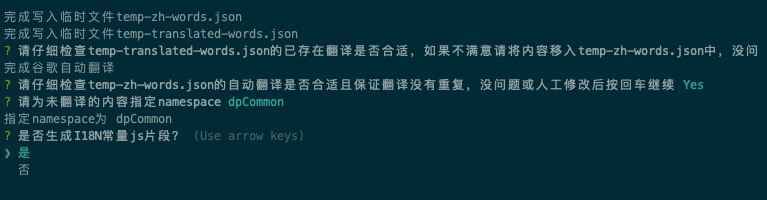
- 如果选择是,就会在
temp-i18n-labels.js中生成当前所有翻译内容的常量集合
const I18N = {
/**
* @description 模型名称
*/
MODEL_NAME: i18n.t('cdp:model name'),
/**
* @description 这是一段测试的文案,结果将会被翻译成英文
*/
THIS_IS_A_TEST_COPY_THE_RESULT: i18n.t('dpCommon:this is a test copy, the result will be translated into English'),
};
- 自动替换源文件内容,如果上一步选择是,就会用I18N常量来替换,这里会提示将
temp-i18n-labels.js中生成的内容手动粘贴到相应的源文件中。 如果选择否就跟我们的原始方案一样

- 结束之后按回车,选择是否直接清除临时文件,这样就省得手动去删除

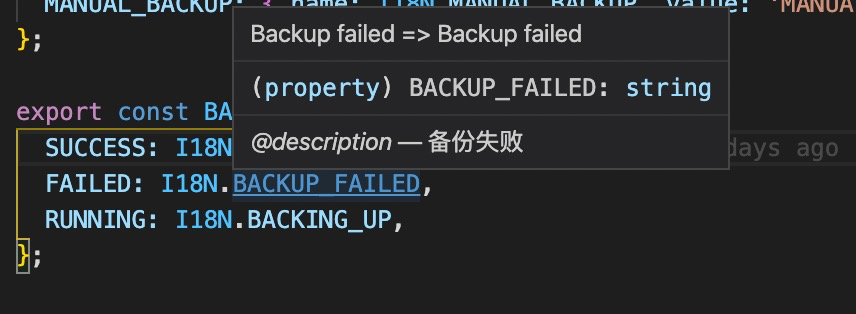
- 如果采用常量的方式替换源文件,那么hover在变量上会有中文提示的效果
最后
目前在试用了一个礼拜不到,通过复用现有翻译可以解放很大一部分生产力,很多简单的翻译基本只需要按几下回车就完成了,然后如果开发新模块建议可以使用常量的方式管理国际化,将所有翻译集合到一个config文件中,代码看起来干净改起来也可以统一改。
#! /usr/bin/env/ node
/* eslint-disable @typescript-eslint/no-var-requires */
/* eslint-disable @typescript-eslint/no-require-imports */
/* eslint-disable no-console */
const fs = require('fs');
const path = require('path');
const { walker } = require('./file-walker');
const { invert, remove, words, get } = require('lodash');
const inquirer = require('inquirer');
const { doTranslate } = require('./google-translate');
const ora = require('ora');
// i18n.d("中文")
const reg = /i18n\.d\(["'](.+?)["']\)/g;
const tempFilePath = path.resolve(__dirname, './temp-zh-words.json');
const tempTranslatedPath = path.resolve(__dirname, './temp-translated-words.json');
const tempLabelPath = path.resolve(__dirname, 'temp-i18n-labels.js');
const zhResource = require(path.resolve(__dirname, '../app/locales/zh.json'));
let namespace = 'dpCommon'; // 默认namespace
const namespaces = ['dpCommon', 'dl', 'cdp', 'reco', 'default']; // 全部namespace
const backupNamespace = 'dp'; // 备用namespace
const specialWords = []; // 保存有重复namespace+翻译组合的词
let conflictCount = 0;
let outputLabels = true; // 是否需要输出I18N常量片段
/**
* 存放所有要生成的I18N常量
* 结构为
* {
* CONST_NAME: { content: i18n.t('ns:word'), zh: '单词', }
* }
*/
const labelMap = {};
/**
* 已经翻译过的集合
* {
* '中文': 'dpCommon:Chinese'
* }
*/
const translatedWords = {};
let notTranslatedWords = []; // 未翻译的集合
const findExistWords = (toTransChineseWords) => {
const _notTranslatedWords = [...toTransChineseWords]; // 当前文件需要被翻译的中文集合
// 遍历zh.json的各个namespace,查看是否有已经翻译过的中文
Object.keys(zhResource).forEach(namespaceKey => {
// 当前namespace下所有翻译
const namespaceWords = zhResource[namespaceKey];
// key-value 位置对换 变成 { '中文': 'Chinese' }的形式,如果有重复,后面会覆盖前面
const invertTranslatedWords = invert(namespaceWords);
toTransChineseWords.forEach((zhWord) => {
// 当存在现有翻译且translatedWords还没包含它时,加入已被翻译列表,并从未翻译列表中移除
if (invertTranslatedWords[zhWord] && !translatedWords[zhWord]) {
translatedWords[zhWord] = namespaceKey === 'default' ? invertTranslatedWords[zhWord] : `${namespaceKey}:${invertTranslatedWords[zhWord]}`;
remove(_notTranslatedWords, w => w === zhWord);
}
});
});
notTranslatedWords = notTranslatedWords.concat(_notTranslatedWords);
};
const extractI18nFromFile = (content, filePath, isEnd, resolve) => {
// 只处理代码文件
if (!['.tsx', '.ts', '.js', '.jsx'].includes(path.extname(filePath)) && !isEnd) {
return;
}
let match = reg.exec(content);
const toTransChineseWords = []; // 扣出当前文件所有被i18n.d包装的中文
while (match) {
if (match) {
const [, zhWord] = match;
toTransChineseWords.push(zhWord);
}
match = reg.exec(content);
}
if (!isEnd && toTransChineseWords.length === 0) {
return;
}
// 传入需要被翻译的中文列表,前提是不在notTranslatedWords和translatedWords中出现
findExistWords(toTransChineseWords.filter(zhWord => !notTranslatedWords.includes(zhWord) && !translatedWords[zhWord]));
if (isEnd) {
// 所有文件遍历完毕 notTranslatedWords 按原来的形式写入temp-zh-words
if (notTranslatedWords.length > 0) {
const zhMap = {};
notTranslatedWords.forEach(word => {
zhMap[word] = '';
});
fs.writeFileSync(tempFilePath, JSON.stringify(zhMap, null, 2), 'utf8', (writeErr) => {
if (writeErr) return console.error('写入临时文件temp-zh-words错误', writeErr);
});
console.log('完成写入临时文件temp-zh-words.json');
}
// translatedWords写入temp-translated-words
if (Object.keys(translatedWords).length > 0) {
fs.writeFileSync(tempTranslatedPath, JSON.stringify(translatedWords, null, 2), 'utf8', (writeErr) => {
if (writeErr) return console.error('写入临时文件temp-translated-words错误', writeErr);
});
console.log('完成写入临时文件temp-translated-words.json');
}
resolve();
}
};
let tempZhMap = null;
let translatedMap = null;
// 通过翻译的英文来生成CONST的key,单词间用_连接,超过20位的翻译只取前20位的有效单词
const getConstName = (enWords) => {
const wordNameArray = words(enWords.toUpperCase()); // lodash.words 可以直接忽略符号只取单词
const nameArray = [];
let count = 0;
// 长度暂时限制为20
while (wordNameArray.length && count < 20) {
const word = wordNameArray.shift();
nameArray.push(word);
count += word.length;
}
return nameArray.join('_');
};
const generateLabelAndRestoreFile = (content, filePath, isEnd, resolve) => {
if (!['.tsx', '.ts', '.js', '.jsx'].includes(path.extname(filePath)) && !isEnd) {
return;
}
let match = reg.exec(content);
let newContent = content;
let changed = false;
while (match) {
if (match) {
const [fullMatch, zhWord] = match;
let replaceText;
if (tempZhMap[zhWord]) {
// 如果已经在temp-zh-words.json中找到翻译就替换
const enWord = tempZhMap[zhWord];
let i18nContent = namespace === 'default' ? `i18n.t('${enWord}')` : `i18n.t('${namespace}:${enWord}')`;
if (specialWords.includes(zhWord)) {
i18nContent = `i18n.t('${backupNamespace}:${enWord}')`;
}
if (outputLabels) {
let constName = getConstName(enWord);
replaceText = `I18N.${constName}`;
if (labelMap[constName]) {
// 万一长句子前面20位都相同,尾巴上加一个不重复的数字
conflictCount += 1;
constName += `_${conflictCount}`;
}
labelMap[constName] = { content: i18nContent, zh: zhWord };
} else {
replaceText = i18nContent;
}
} else if (translatedMap[zhWord]) {
// 如果在temp-translated-words.json中找到翻译就替换
const translatedEnWord = translatedMap[zhWord];
if (outputLabels) {
const wordName = translatedEnWord.includes(':') ? translatedEnWord.split(':')[1] : translatedEnWord;
let constName = getConstName(wordName);
replaceText = `I18N.${constName}`;
if (labelMap[constName]) {
conflictCount += 1;
constName += `_${conflictCount}`;
}
labelMap[constName] = { content: `i18n.t('${translatedEnWord}')`, zh: zhWord };
} else {
replaceText = `i18n.t('${translatedEnWord}')`;
}
} else {
console.warn(zhWord, '还没被翻译');
}
if (replaceText) {
newContent = newContent.replace(fullMatch, replaceText);
changed = true;
}
}
match = reg.exec(content);
}
if (changed) {
fs.writeFileSync(filePath, newContent, 'utf8', (writeErr) => {
if (writeErr) return console.error(`写入文件:${filePath}错误`, writeErr);
});
}
if (isEnd) {
if (outputLabels && Object.keys(labelMap).length > 0) {
const labelStream = fs.createWriteStream(tempLabelPath);
labelStream.write('const I18N = {\n');
Object.keys(labelMap).forEach(label => {
labelStream.write(' /**\n');
labelStream.write(` * @description ${labelMap[label].zh}\n`);
labelStream.write(' */\n');
labelStream.write(` ${label}: ${labelMap[label].content},\n`);
});
labelStream.write('};\n');
labelStream.end(() => {
console.log('完成写入临时i18n label文件');
resolve();
});
} else {
resolve();
}
}
};
const autoI18n = async () => {
const extractPromise = new Promise((resolve) => {
// 第一步,找出需要被翻译的内容, 将内容分配为未翻译和已翻译两部分
walker({
root: path.resolve(__dirname, '../app'),
dealFile: (...args) => {
extractI18nFromFile.apply(null, [...args, resolve]);
},
});
});
await extractPromise;
if (notTranslatedWords.length === 0 && Object.keys(translatedWords).length === 0) {
console.log('未发现需要国际化的内容,程序退出');
return;
}
if (Object.keys(translatedWords).length > 0) {
await inquirer.prompt({
name: 'confirm',
type: 'confirm',
message: '请仔细检查temp-translated-words.json的已存在翻译是否合适,如果不满意请将内容移入temp-zh-words.json中,没问题或人工修改后按回车继续',
});
}
// 第二步,调用Google Translate自动翻译
if (notTranslatedWords.length > 0) {
const spinner = ora('谷歌自动翻译ing...').start();
await doTranslate();
spinner.stop();
console.log('完成谷歌自动翻译');
// 第三步,人肉检查翻译是否有问题
await inquirer.prompt({
name: 'confirm',
type: 'confirm',
// 除了要检查翻译是否正确,还要检查'运行中'和'进行中'两个翻译相同的词不能同时被处理,此问题在之前的方案中也存在
message: '请仔细检查temp-zh-words.json的自动翻译是否合适且保证翻译没有重复,没问题或人工修改后按回车继续',
});
}
tempZhMap = JSON.parse(fs.readFileSync(tempFilePath, { encoding: 'utf-8' }));
if (Object.keys(translatedWords).length > 0) {
translatedMap = JSON.parse(fs.readFileSync(tempTranslatedPath, { encoding: 'utf-8' }));
}
// 第四步,指定namespace
if (Object.keys(tempZhMap).length > 0) {
const { ns } = await inquirer.prompt({
name: 'ns',
type: 'list',
message: '请为未翻译的内容指定namespace',
default: namespaces[0],
choices: namespaces,
});
if (ns) {
namespace = ns;
}
console.log('指定namespace为', namespace);
// 第五步,检查自动或人工翻译后,是否有namespace冲突
// 比如原先在cdp的namespace下有一个中文`进行中`翻译为`running`, 这次也需要加一个词在cdp下叫`运行中`,翻译结果也是`running`
// 此时就必须将这个running安排到一个单独的空间,否则这个词就会丢失
Object.keys(tempZhMap).forEach(key => {
if (get(zhResource, `${namespace}.${tempZhMap[key]}`)) {
if (get(zhResource, `${backupNamespace}.${tempZhMap[key]}`)) {
// 如果此时又来一个`奔跑中`,那就无法自动处理了,属于极小概率事件,由使用者自行处理
console.error(key, '在目标namespace和备用namespace两个命名空间都有相同翻译了,请手动解决这个问题');
throw (new Error('duplicate translation'));
} else {
console.log('<', key, '> 有相同的namespace和翻译已存在,自动转入备用namespace');
specialWords.push(key);
}
}
});
}
// 第六步,按需输出I18N代码片段
const { outputLabels: requireLabels } = await inquirer.prompt({
name: 'outputLabels',
type: 'list',
message: '是否生成I18N常量js片段?',
default: '是',
choices: ['是', '否'],
});
outputLabels = requireLabels === '是';
// 第七步,用I18N的常量或者原始的i18n.t回写源文件
const generatePromise = new Promise((resolve) => {
walker({
root: path.resolve(__dirname, '../app'),
dealFile: (...args) => {
generateLabelAndRestoreFile.apply(null, [...args, resolve]);
},
});
});
const spinner = ora('替换原文件ing...').start();
await generatePromise;
spinner.stop();
console.log('完成替换原文件');
// 第八步,写入locale文件
if (Object.keys(tempZhMap).length > 0) {
const { writeLocale } = require('./i18n-extract');
const localePromise = new Promise((resolve) => {
writeLocale(resolve, outputLabels);
});
const loading = ora('写入local文件ing...').start();
await localePromise;
loading.stop();
console.log('完成写入locale文件');
}
if (outputLabels) {
await inquirer.prompt({
name: 'confirm',
type: 'confirm',
message: '请手动将临时文件temp-i18n-labels.js中的代码片段插入到相应文件中去,完成后按回车继续',
});
}
// 第九步,清理临时文件
const { clear } = await inquirer.prompt({
name: 'clear',
type: 'list',
message: '是否需要清除所有临时文件?',
default: '是',
choices: ['是', '否'],
});
if (clear === '是') {
Object.keys(translatedWords).length > 0 && fs.unlinkSync(tempTranslatedPath);
outputLabels && fs.unlinkSync(tempLabelPath);
fs.writeFileSync(tempFilePath, JSON.stringify({}, null, 2), 'utf8');
console.log('完成清除临时文件');
}
console.log('国际化已完成,再见👋');
};
autoI18n();